Frontend structure
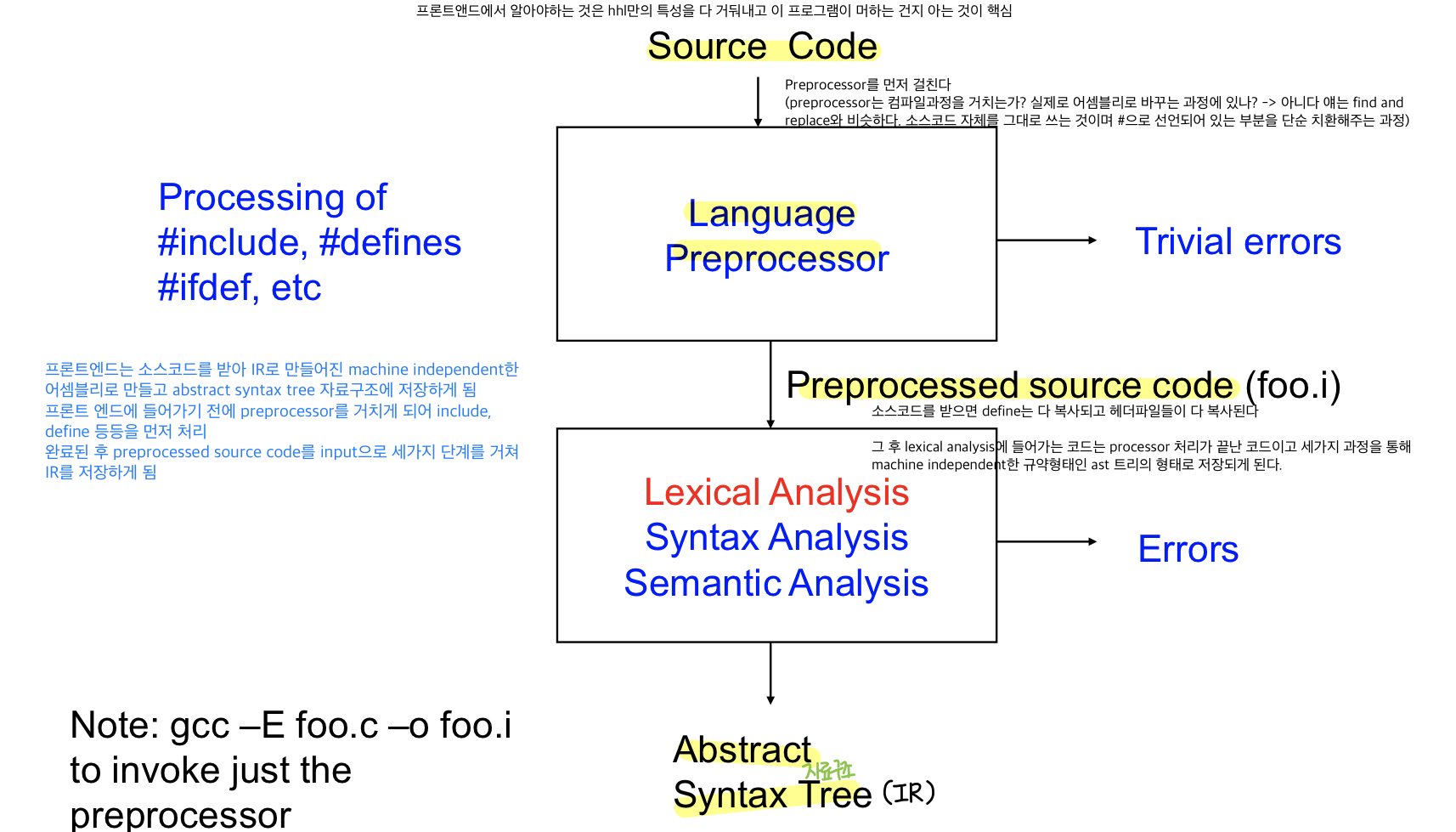
- 프론트앤드는 소스코드를 받아 IR로 만들어진 machine independent한 assembly로 만들고 abstract syntax tree라는 자료구조에 저장하게 됨
- 프론트 앤드에 들어가기 전에 preprocessor를 거치게 됨
- 전처리 과정은 컴파일러 과정이라고 볼 수 없다
ex) include, define 등 먼저 처리, find and replace와 비슷, #으로 되어있는 부분을 단순 치환해주는 과정
→ 완료된 후 preprocessed source code(define이 다 복사되고 헤더파일들이 복사됨)를 Input으로 받아 세단계를 거쳐 machine independent 규약형태인 IR, ast 트리의 형태로 저장하게 됨
lexical analysis
- 알파벳으로 쓰여진 코드를 하나씩 읽어서 유의미한 중요한 단어들을 추출하는 과정을 말함
분석 시 스펙을 어떻게 어떤 걸로 정하는가, 어떻게 검출하는가, 어떻게 이 과정을 자동화하는가
specification- 어떻게 lexical pattern을 specify할 것인가?
: lexical pattern(어떠한 단어들을 추출할 것이냐, 단어를 어떻게 지정할 것이냐 등의 스펙 설명서, 견적을 내줘야 함)을 어떻게 만들 것이냐?
Ex) x,xy,match0은 변수 3,12,0.12는 숫자
→ 변수는 string으로 만들어지고 숫자는 문자열로 만들어지고 등등의 패턴을 지정해줘야한다
- 이 떄 lexical pattern을 저장하기 위해 정규표현식을 사용
- hhl이 무엇인가에 따라서 spec은 달라질 수 있다.
Recognition - 어떻게 lexical pattern을 인식할 것인가?
타겟 language에서 lexical pattern을 정규표현식으로 지정해주면 이러한 패턴을 어떻게 인식할 수 있을까??
얘가 숫자구나, 얘가 변수구나 -> text로 된 c코드를 읽어서 어떻게 인식할 수 있을까??
ex) mach0은 변수, 512는 숫자
- Deterministic finite automata,DFA를 이용
- input language에 중요한 키워드나 변수를 지정하는 스펙 규약을 지정해주고 이 걸 어떻게 실제도 키워드로 인식할 것인가? DFA로 검출
Automation - 어떻게 automatially하게 spec으로부터 string recognizer를 만들 수 있을까?
: 이러한 과정을 어떻게 자동화할 수 있을까?? 스펙이 있을 때 스트링을 인식하는 거를 어떻게 자동으로 만들 수 있을 까?
- Thompson’s construction and subset construction를 이용
(정리)
Regular expression으로 만들어진 스펙을 받아서 thompson’s construciton and subset construciton을 이용하여 DFA를 자동으로 만든다.
lexical anaylsis process
-
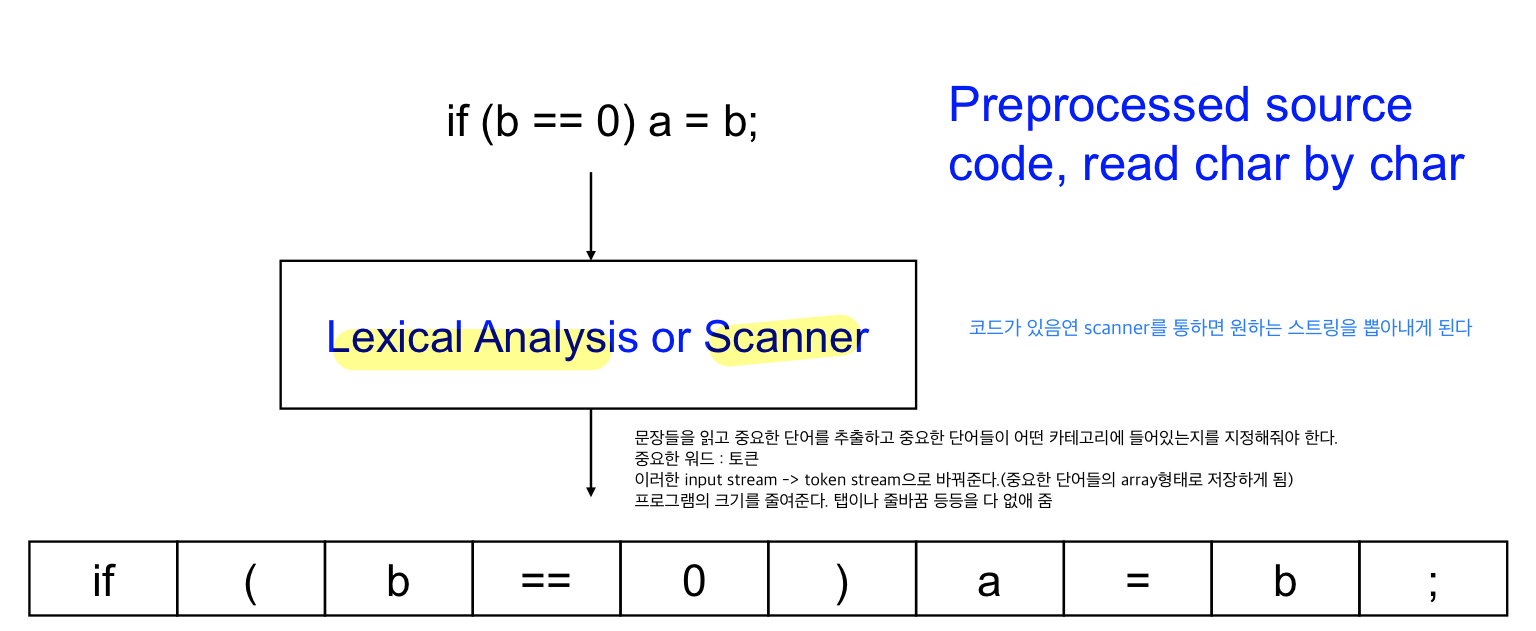
코드가 있으면 Scanner를 통하면 원하는 string들을 뽑아내게 된다
- 문장들을 읽으면서 중요한 단어들을 추출하고 중요한 단어들이 어떤 카테고리에 들어가 있는지 지정해줘야 한다.
- input stream → token stream으로 변경해준다.(중요한 단어들의 array형태로 저장)
lexical analysis
1) Multi character input stream 로 만들어진 코드를 (뽑아내고 싶은 identifier들)token stream으로 만드는 것 + 프로그램의 길이를 줄임
2) Space, 주석을 없애서 program의 length를 줄여 필요한 문자들을 각각의 토큰으로 인식하여 저장
cf. 이후 Token stream을 이용해서 문법적으로 틀렸는지 체크하고 토큰들의 관계를 저장하는 것 : syntax anaylsis, 문법 체크
Tokens
- 언어마다 감지하는 토큰들이 다르기에 hhl마다 정규표현식으로 표현됨
- 변수,identifiers ex) x,y, elsex
- 키워드,keyword - 언어에서 지정된 특수한 역할을 하는 특수어 ex) if, else, whild, for, break
- 숫자,integers ex) 2, 1000, -2
- 소수, floating- point ex) 2.0, -0.001, 0.02, 1e5
- 특수문자, symbol ex) +, *, {, } , ++, « , ≤ , [ , ]
- 문자열, strings ex) “x” “he said”
token을 어떻게 표현하는가?
- 토큰은 정규표현식(Regular expression)을 이용해서 표현하게 되는데 귀납적으로 구현됨
- 스펙은 원하는 토큰들의 규약을 의미 ex) 어떤 거는 변수로 분류해야 하고 어떤 거는 키워드로 분류해야 한다
- 토큰들을 표현하기 위해 많은 language가 있으므로 RE를 이용해서 스펙을 지정
- RE는 inductively하게 정의

R+는 엡실론이 없이 R,RR,RRR …인 것 == RR*
R* -> empty,R,RR ….
language
: Regular expression (R)으로 토큰을 만들어주는데 R로 만들어지는 string의 set, L(R)로 표현
L(R) = R로 정의된 언어

- 인식하고 싶은 모든 토큰들을 표현할 수 있는 regular expression의 set을 만들어놓고 언어로 묶으면 원하는 specification이 된다.

← 많이 사용되는 RE는 알아야 하며 시험에도 나올 것, 특수한 게 아니라 기본적인 걸로 풀 수 있는 문제가 나올 예정

여러개의 RE rule이 겹칠 경우 어떻게 해야할까?
원하는 토큰을 인식하기 위해서 RE를 받지만 이걸로는 충분하지 않음, 중복되는 매치들이 존재
→ Multiple match인 경우의 룰이 필요!!
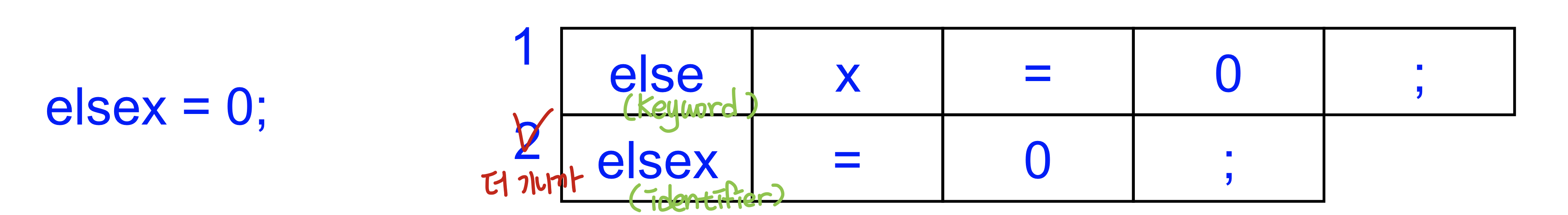
- 더 긴 토큰이 선택되어야 한다 : Longest matching token wins
- else까지 보면 키워드이지만 elsex면 변수가 되는데 이 때 더 긴 변수로 정한다
- 같은 길이라면 priority를 지정해줘야 한다 : priorities
- 같은 길이라면 lexer가 priority를 정해주면 된다. 이걸 정하는 것은 스펙을 정하는 사람이 정할 것이고 여기서는 keyword > identifer가 될 것
- 스펙에서 각각의 우선순위를 지정해줘야 한다
→ 더 긴걸 선택하고 같을 경우에는 우선순위가 높은 keyword가 선택되어야 한다.
- 스펙을 정해줄 때 RE들 + 다른 종류간의 identifier 간의 priority+ longest maching token rule = definition of a lexer
-
lexical analysis할 준비 완성!
Automatic generation of Lexers
lexer를 자동으로 만들어주는 프로그램 – lex, flex
- 이 둘은 스펙을 정해주면 lexical analyizer를 만들 수 있는 소스코드를 뽑아내 줌
Lexer generator의 Input
- priority가 정해진 RE들의 set
- LFM(longest first mathcing)는 기본적으로 정해진 것
- RE마다 행동해야하는 Action을 정해짐
Output
- 토큰을 뽑아낼 수 있는 프로그램을 만들어줌
Spec을 가지고 lex를 거치면 c program이 나오고 이를 컴파일하면 lexer가 만들어지게 되는 것
Spec을 주고 flex가 프로그램을 실행하면 lexer program이 만들어지고 이를 컴파일하면 lexer가 만들어짐
Lex / Flex
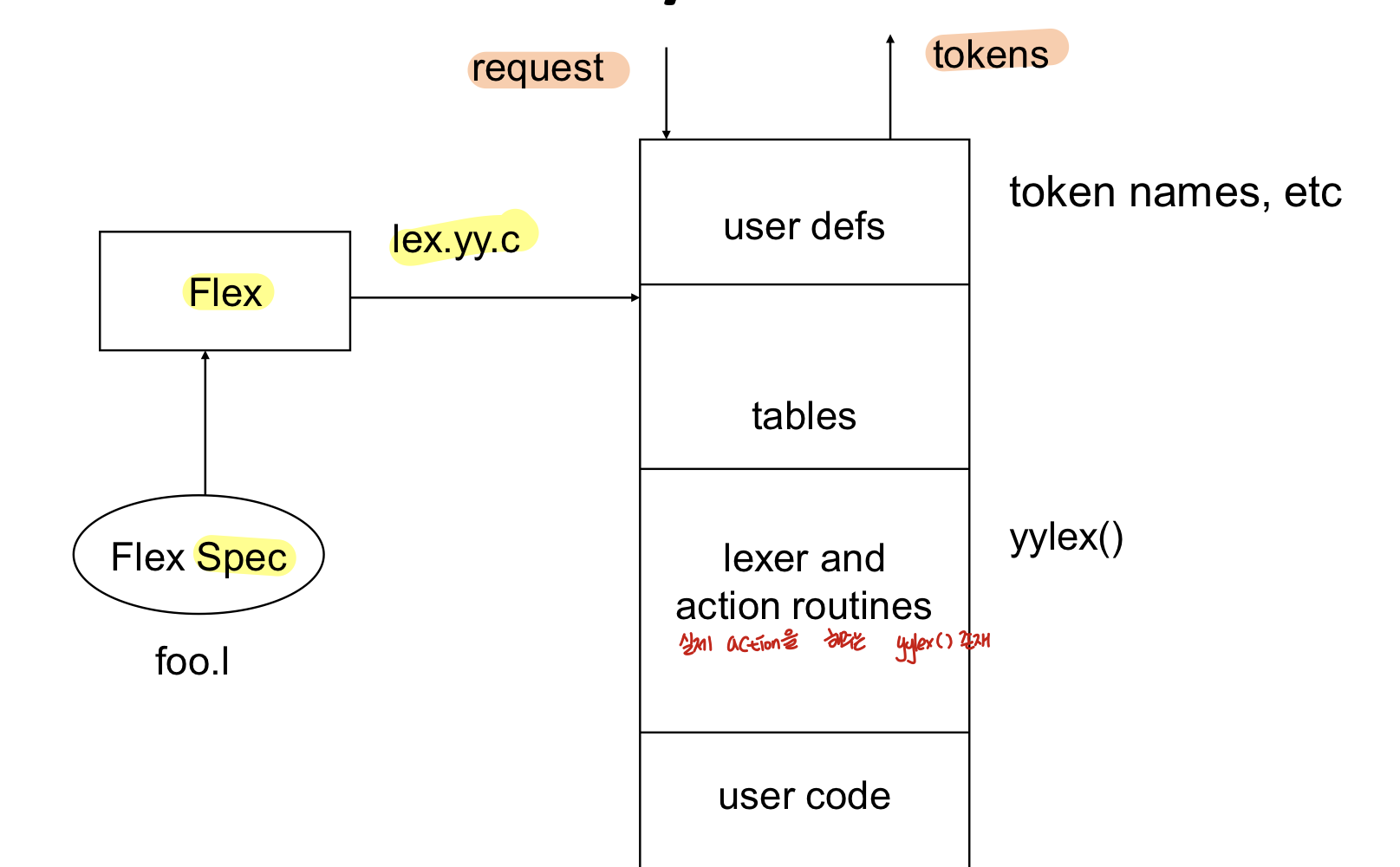
lexer를 만들기 위해서 스펙을 지정해주고(foo.l) 이 스펙을 flex의 input으로 넣어주면 자동으로 수행해주는 프로그램인 lex.yy.c가 나오게 된다. → 이 프로그램의 input은 input stream이고 이 프로그램의 output은 token stream이 된다.
- finite state table, DFA의 transition table과 실제 action을 하는 yylex()가 존재한다
Lex specification
Priority를 지정한 RE의 모임
- Lex의 스펙은 definition section, rules section, user functions section으로 구성

Definition section
: 원하는 패턴과 state를 정의해줌
Rules section
: lexical pattern, semantic action들에 대한 정보를 만들어준다
User functions section
: 필요한 Function을 만들어준다
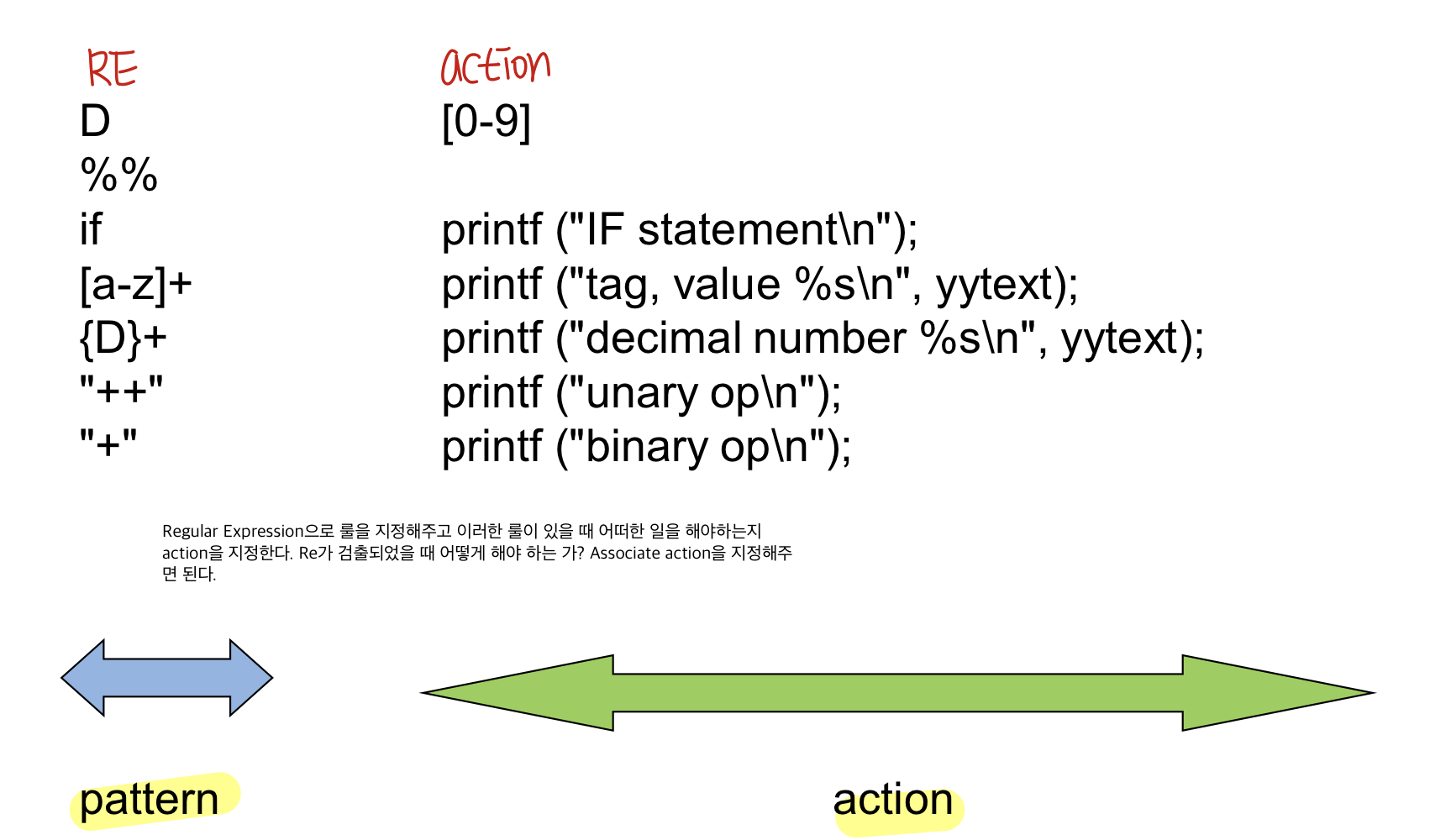
ex) flex program

ex1) flex program

- Lex spec을 보면 어떻게 lexical anaylsis를 할 타겟 language의 spec을 만들어야 하는지 알게 될 것
- 패턴을 RE로 알려주고 패턴에 따른 action을 지정해 줌
- 스펙을 넣어주게 되면 lex.yy.c가 나오게 되고 얘를 컴파일하면 lexical anaylsiser가 나온다 input으로 character string을 넣어준다.
- Flex를 이용해서 lexical anaylzer를 만들어줄 수 있다
Lex Regular Expression Meta Chars

Lexical anaylsis를 위해서 스펙을 RE로 표현하고 spec을 Input으로 해서 lexical anaylsis를 할 수 있는 프로그램을 자동으로 만들어주는 lexer(lex,flex)에 대해서 알아보았다
lex가 어떻게 일을 할까?
FSA(finite state automaton)를 사용해서 수행하게 됨
- RE를 이용해서 regular set을 찾고 FSA를 이용해서 regular set을 인식(set에 드어있는지 안들어있는지 검출)
FSA
: 스테이트의 수가 유한하고 각각의 state 사이에 transition이 있고 initial state와 final state가 존재, final state는 여러개여도 됨
현재 state에서 어떠한 조건에 따라 다음 state로 가는지 지정
- Input character stream이 있을 때 분석해서 원하는 regular expression을 뽑아내게 된다 -> 하나의 FSA가 되어 character를 보면서 state를 옮기면서 결국 regular expression을 추출하게 됨
- Final state로 끝나면 문제없이 끝나게 되고 만약에 final state에 도달하지 못한다면 문제가 있는 것, 즉, 검출할 수 없는 문자열인 경우 에러가 난다.
- 시작점은 한개이고 final state는 여러개, 여러가지 검출하는 토큰의 형태 할 수 있으니까
두가지 종류의 FSA
1) NFA(nondeterministic finite automata)
똑같은 상황에서도 다양한 경우의 수를 가짐
- State에 있고 input이 들어올 때 가능한 transition이 여러개인 경우
- input string이 필요 없는 transtion이 존재하는 경우
2) DFA(deterministic finite automata)
현재 state에서 input string이 있을 때 항상 단일한 transition이 존재
- 각각의 state에서 갈 수 있는 하나의 엣지만이 존재, empty transition이 없다
Deterministic : 항상 정해져 있다, 항상 언제나 똑같은 상황에서는 같은 결과가 나온다
Finite automata는 테이블로도 graph로도 표현 가능
lexical anlaysis를 하기 위해서는 spec을 받아 NFA를 만들고 실행 시 문제가 있으므로(예측 불가의 문제) DFA로 만들어 준다.
- state machine에서 어떠한 상황에서 가능한 transition 개수가 여러개가 된다거나 input없이 transition이 되는 경우 NFA라고 하고 이걸로 프로그램을 짜기는 어려우므로 DFA로 변환해서 사용
- 프로그래밍 할 떄에는 DFA가 짜기는 더 쉬운 편, 나의 스펙으로 NFA로 만든 뒤 DFA로 변환해서 DFA로 lexer를 만든다.
Lex : spec을 받아 nfa를 만들고 이를 dfa로 만들고 최적화하여 이를 시뮬레이션 할 수 있는 c program을 만들어주는 것
ex) NFA
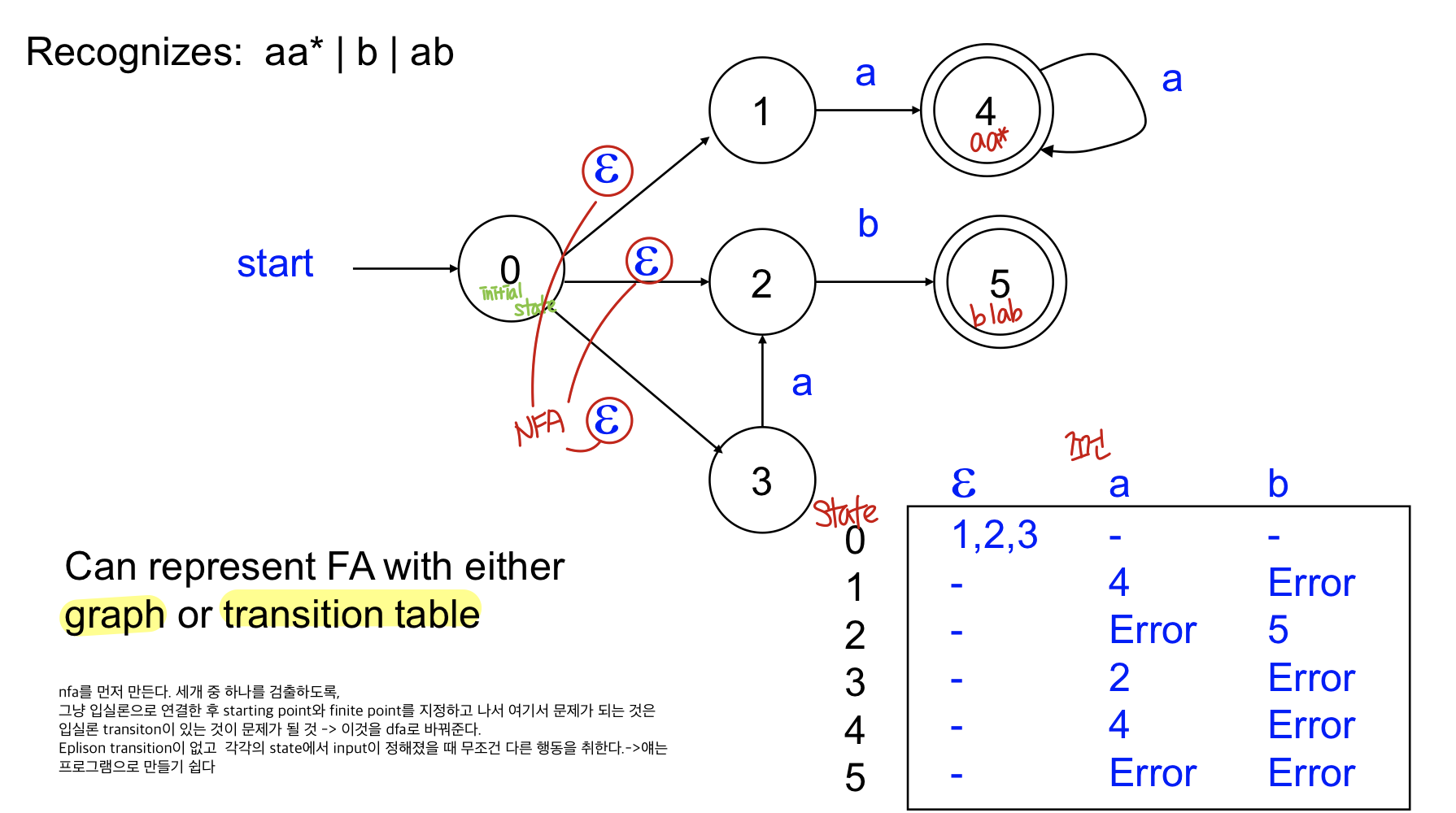
ex) NFA → DFA
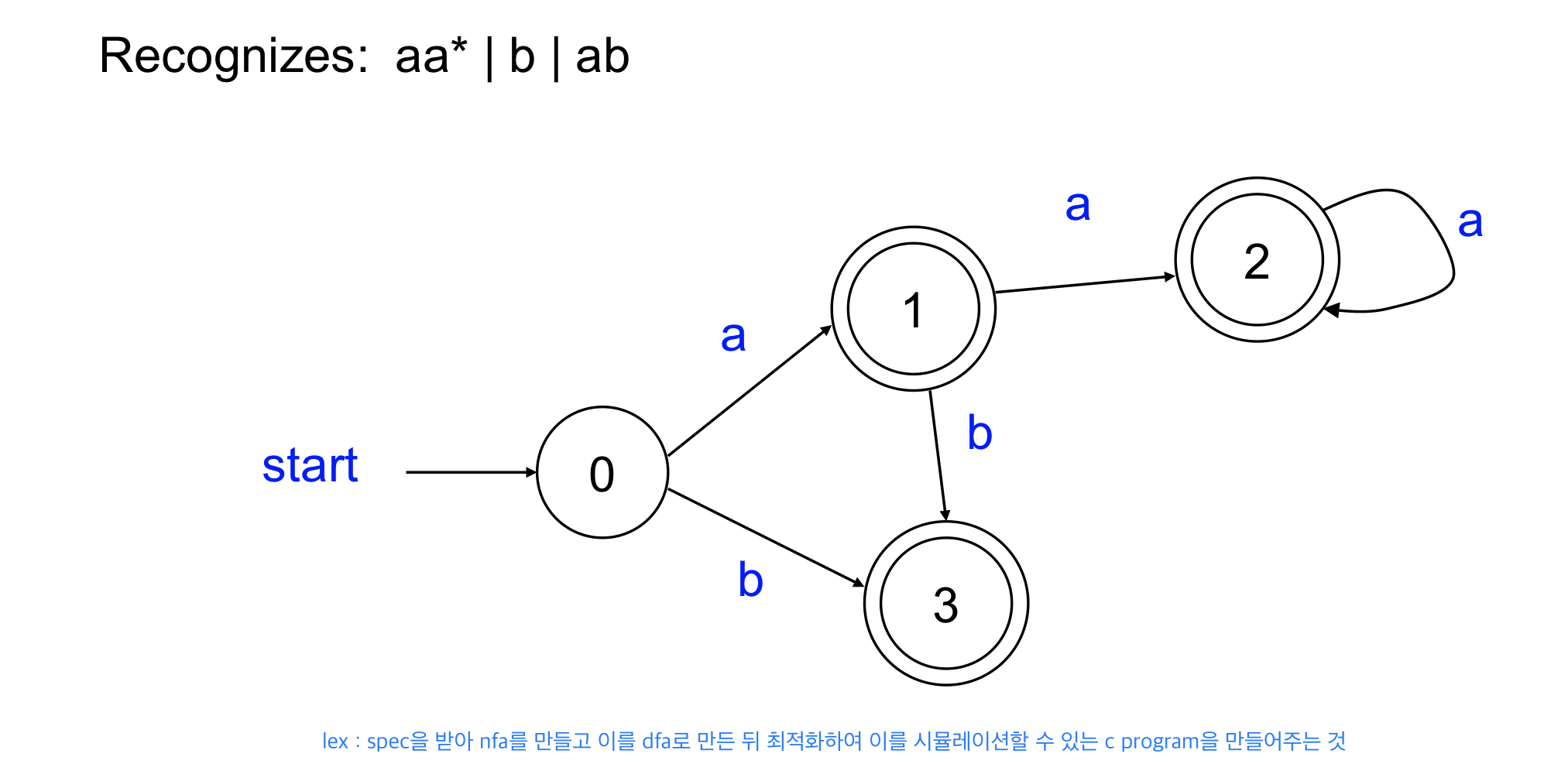
DFA vs NFA
DFA
- DFA는 각각의 input에 따라서 해야하는 액션이 하나밖에 없다
- 테이블로 만들 수 있다(table driven approach)
- NFA보다 많은 state가 필요
NFA
- NFA는 각각의 스텍에서 하나의 Input에 대해 여러개의 초이스가 존재
- accepting state로 가는 게 하나라도 있으면 accept된다.
- 실제로 프로그램을 만들기 어렵다. Table driven spproach가 불가능하기 때문, 스테이트가 여러개가 있어 멀 골라야 제대로 가는지 모르기 때문
Finite automata로 가는건 쉽지만 검출이 어려워 table로 만들어서 input string을 받았을 때 다음 state가 먼지 표현하기 쉽게 하기 위해 dfa로 변경