Lexer가 어떻게 동작하는지 알아보자
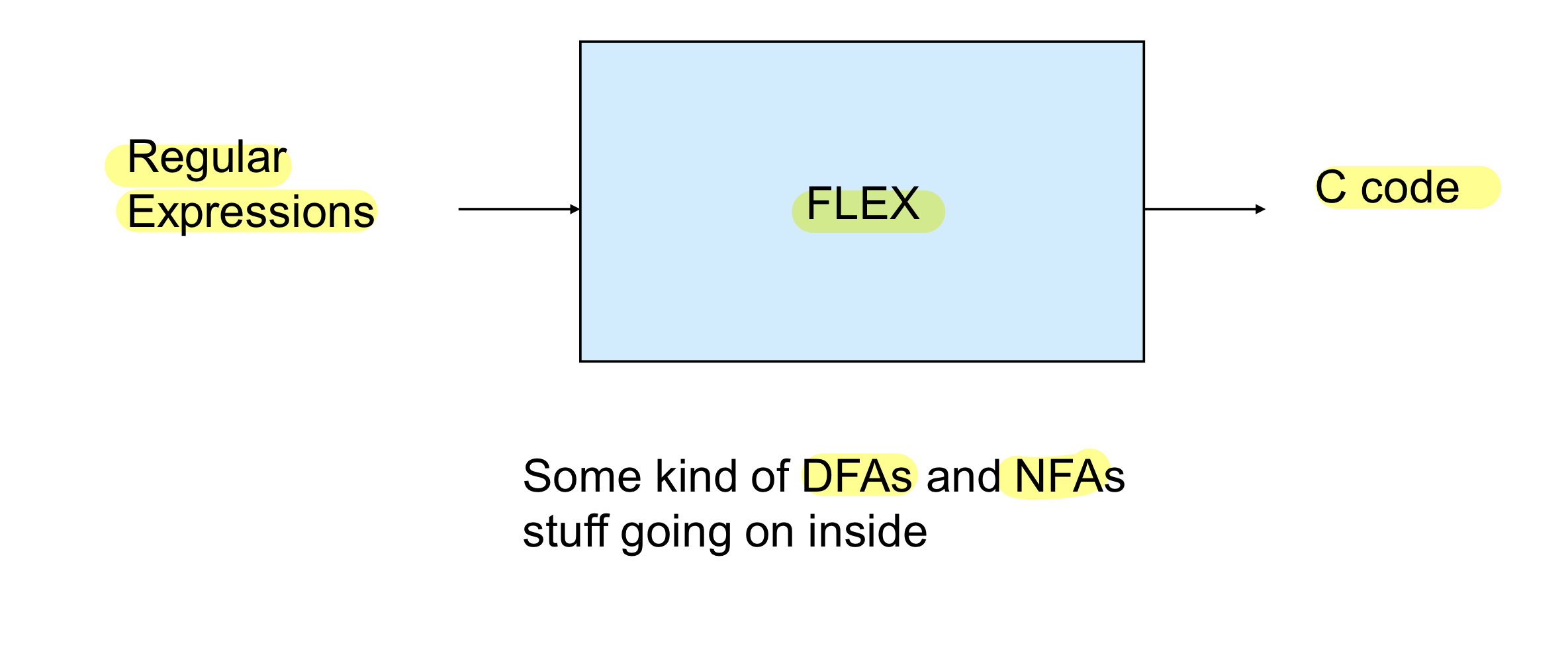
토큰은 RE 형태로 표현되고 각 language에 맞는 스펙이 들어오면 flex를 구동시켜서 DFA를 시뮬레이션 할 수 있는 program의 c code가 output으로 나오는 것을 알 수 있다
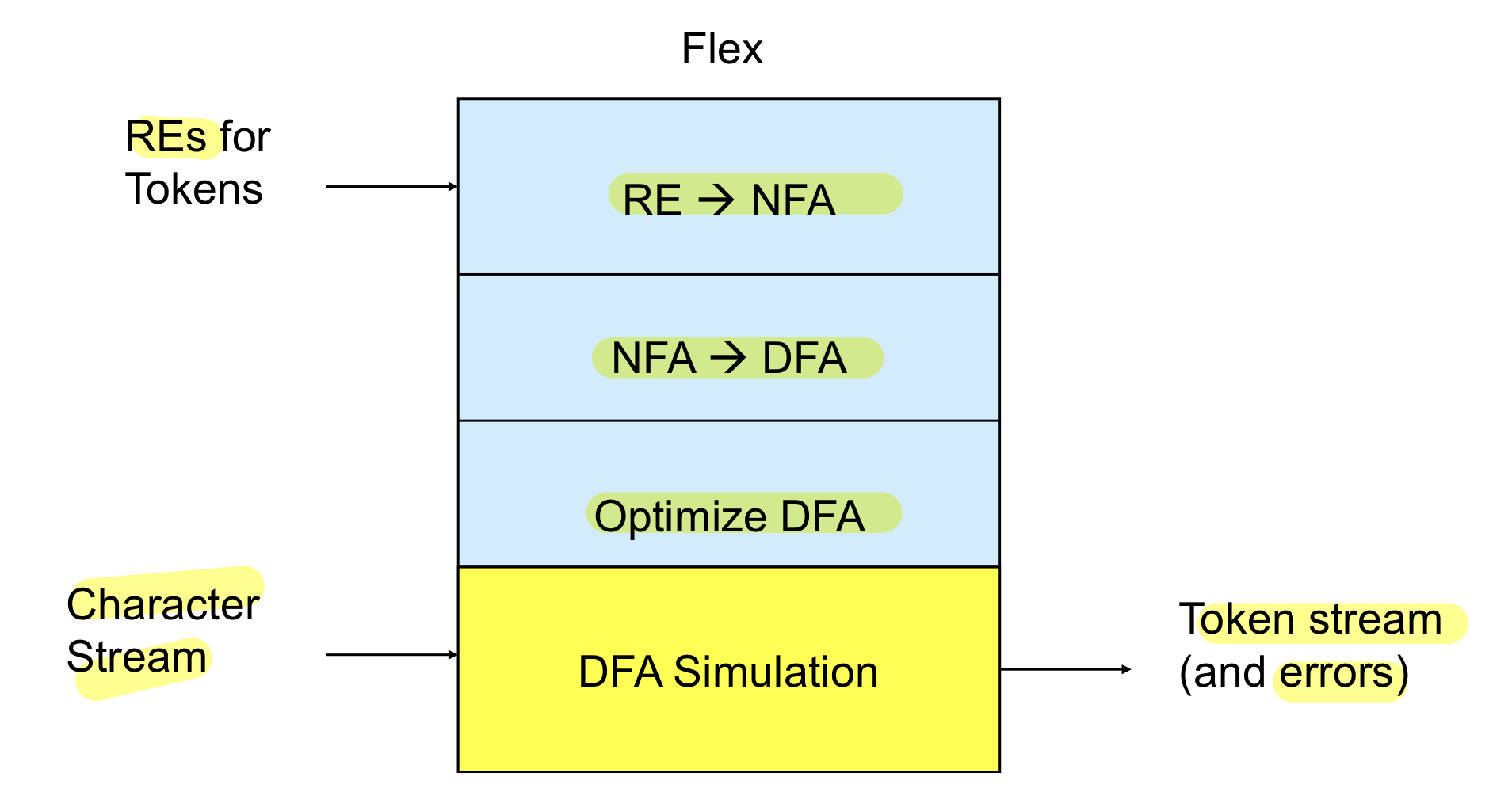
- Re->NFA->DFA 순서로 변환(RE->DFA보다는 RE->NFA가 더 쉽기 떄문)
- 하지만 실제 프로그램으로 짜기에는 NFA가 어려우므로 DFA로 변환, 그리고 변환과정에서 state가 증가하기에 dfa를 최적화시킴
- Lookup table을 구축하고 DFA를 시뮬레이션 할 수 있는 프로그램을 만들어주게 됨
→ Character stream에서 문자를 하나씩 받으면서 simulation으로 token stream을 output으로 만들어주며 주는 혹은 실제로 lexical error를 만들어줄 수도 있음(다 끝났는데 final state가 아니거나 지정된 액션이 없다면 에러를 내보낸다)
RE -> NFA
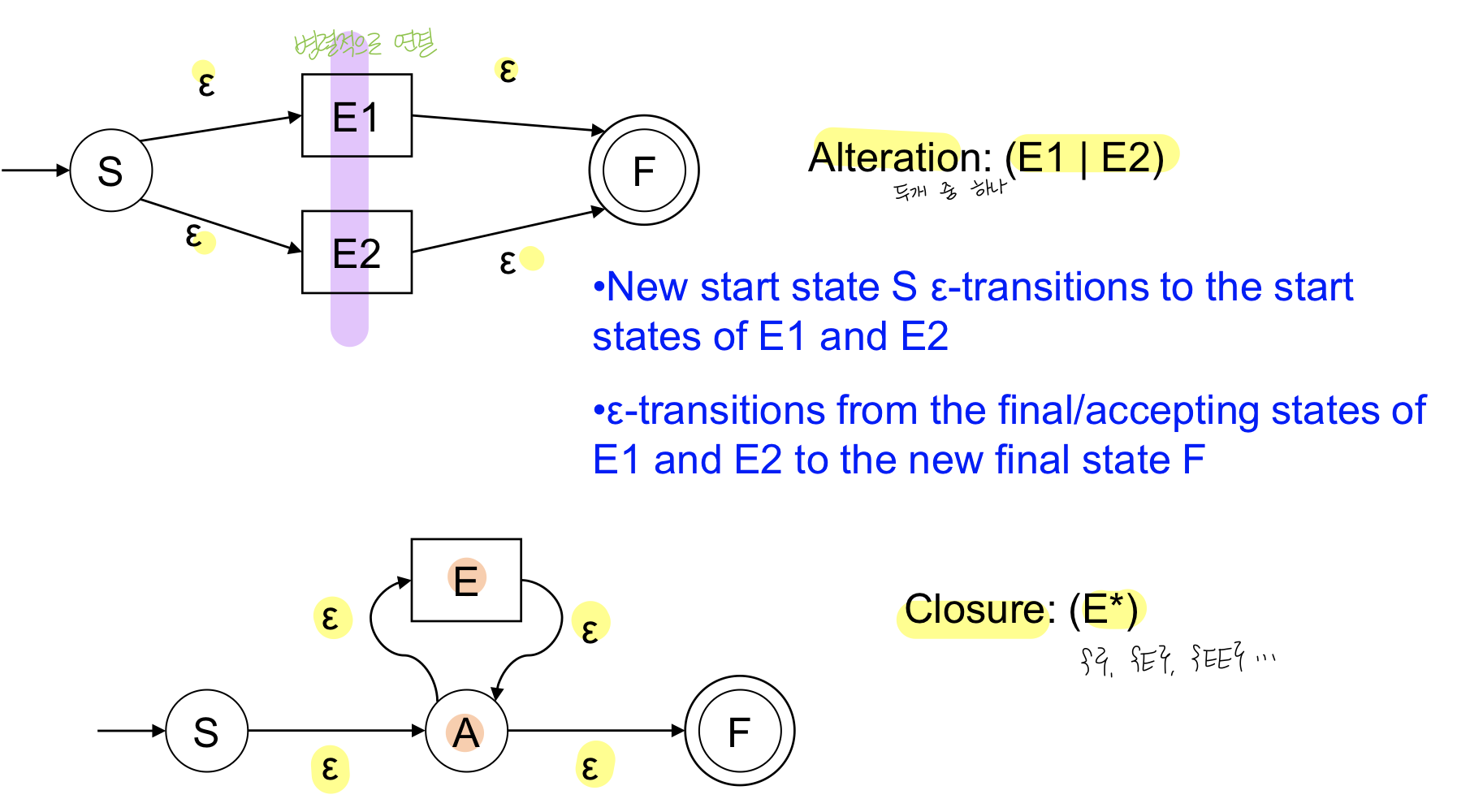
Thompson’s construction algorithm을 사용
- nfa를 귀납적으로 만드는 것이다.
- 각각의 base RE에 대한 룰을 정의한다
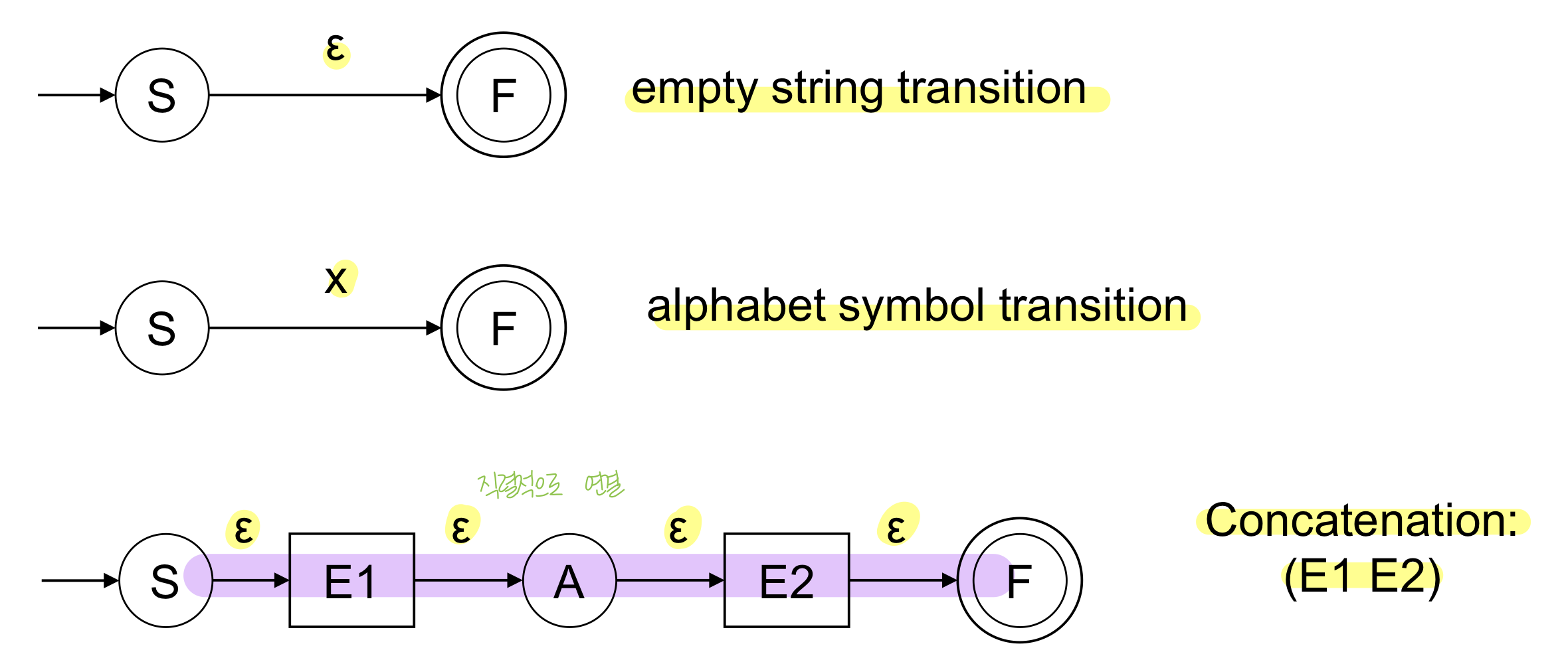
- combine(연결하고 키우면서)하면서 최종적인 복잡한 NFA를 만드는 것
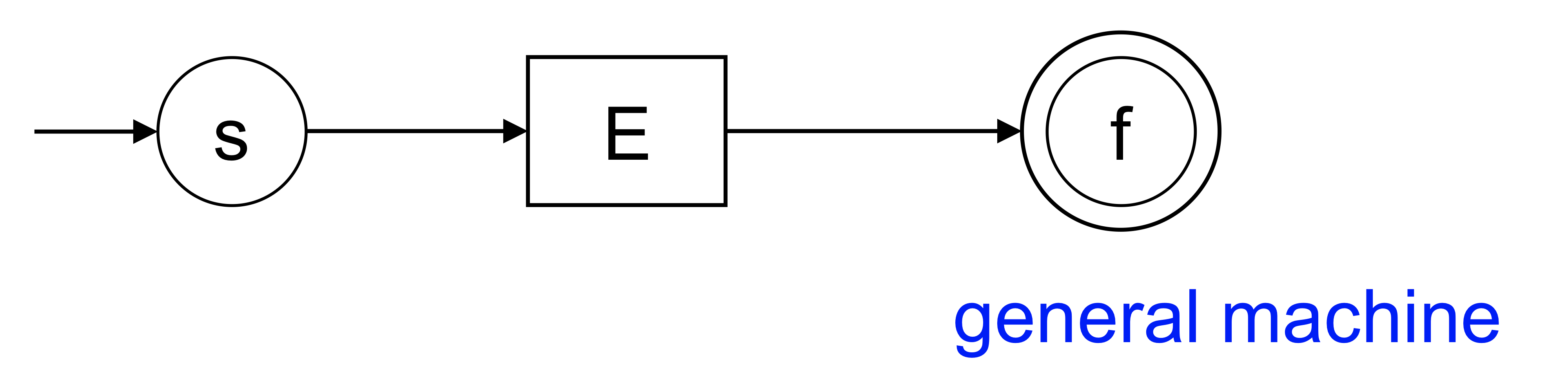
각각의 re마다 nfa를 만드는 룰을 만들고 복잡한 룰은 기본 nfa를 합쳐주면서 최종 nfa를 만들어보자!
Thompson Construction
| ex) RE = (x | y)* |
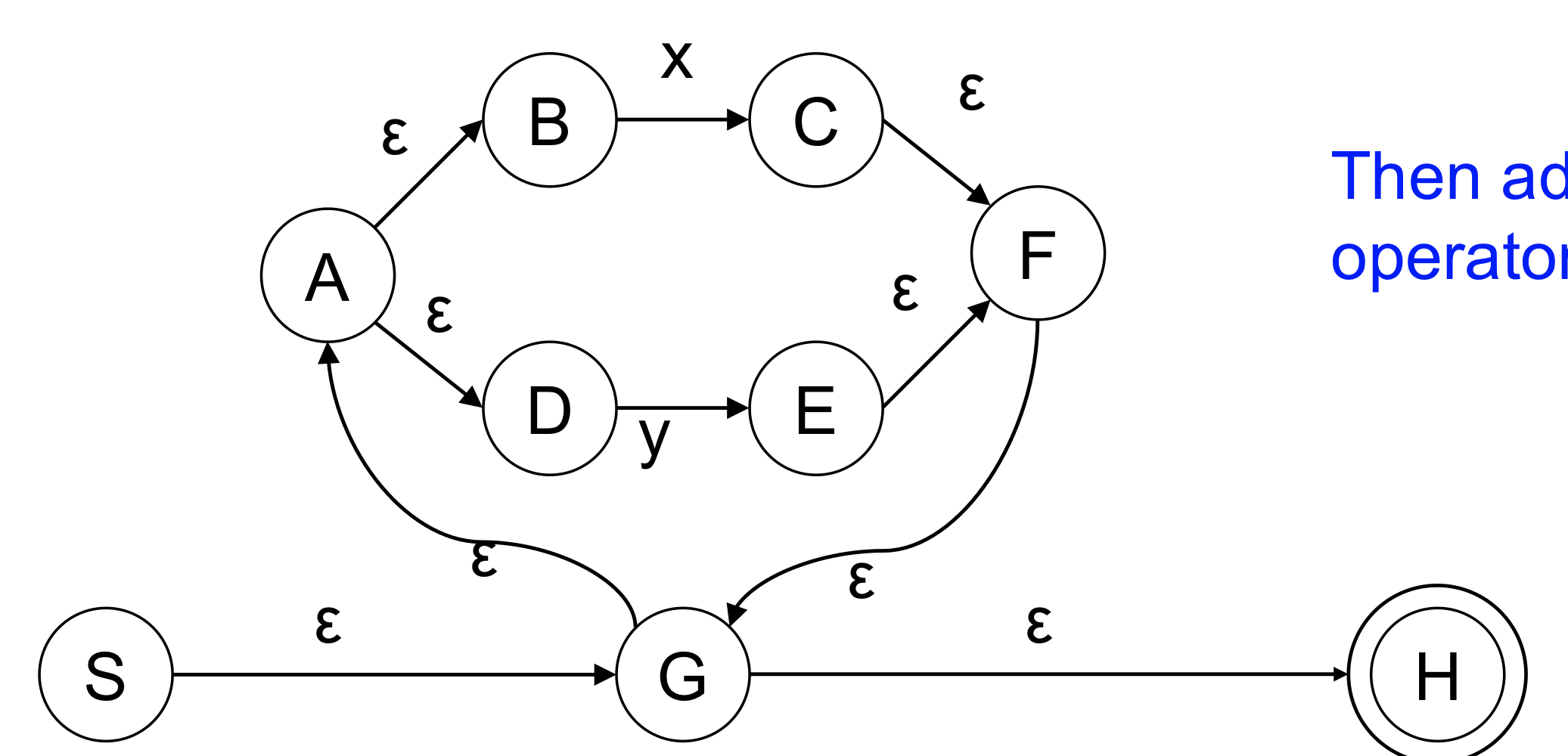
- 아무리 많은 x,y가 나와도 final state가 올 수 있고 character stream에서 final state로 가지 않으면 에러임을 알 수 있음
NFA->DFA
- Nfa와 dfa 차이(non-determinism)를 제거해주면 된다.
- multiple transiton : 같은 character에 의해서 나갈 수 있는 outgoing edge가 여러개인 경우, 하나의 state에서 하나의 character를 받았는데 갈 수 있는 state가 여러개인 경우
- empty transition : 어떤 state에 따라서 input이 없어도 기본 state가 바뀔 수 있는 경우
| ex) RE = (a* | b)c |
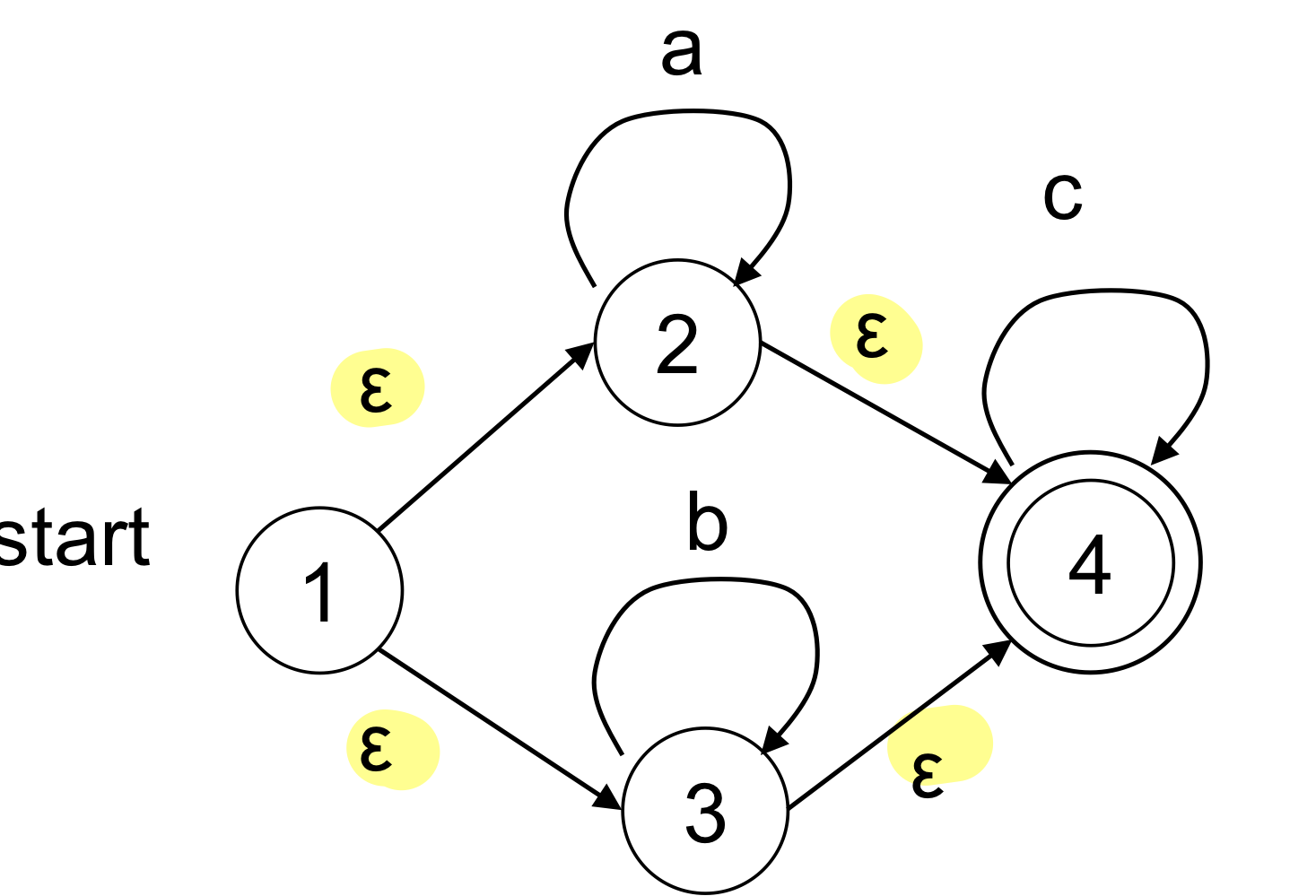
테이블 기반으로 만들게 되는데 1번 state가 갑자기 2번 state일수도 있고 그러니까 문제가 되는 것
문제 1. multiple transition이 존재할 때
→ subset construction으로 해결한다.
- Subset state를 만들어 여러개 의 state를 합쳐서 하나의 큰 state를 만든다
- 하나의 input으로 다수의 state로 가게 된다면 그 state들을 하나로 묶어서 하나의 큰 state(power set of states on the NFA)를 새로 만들자!
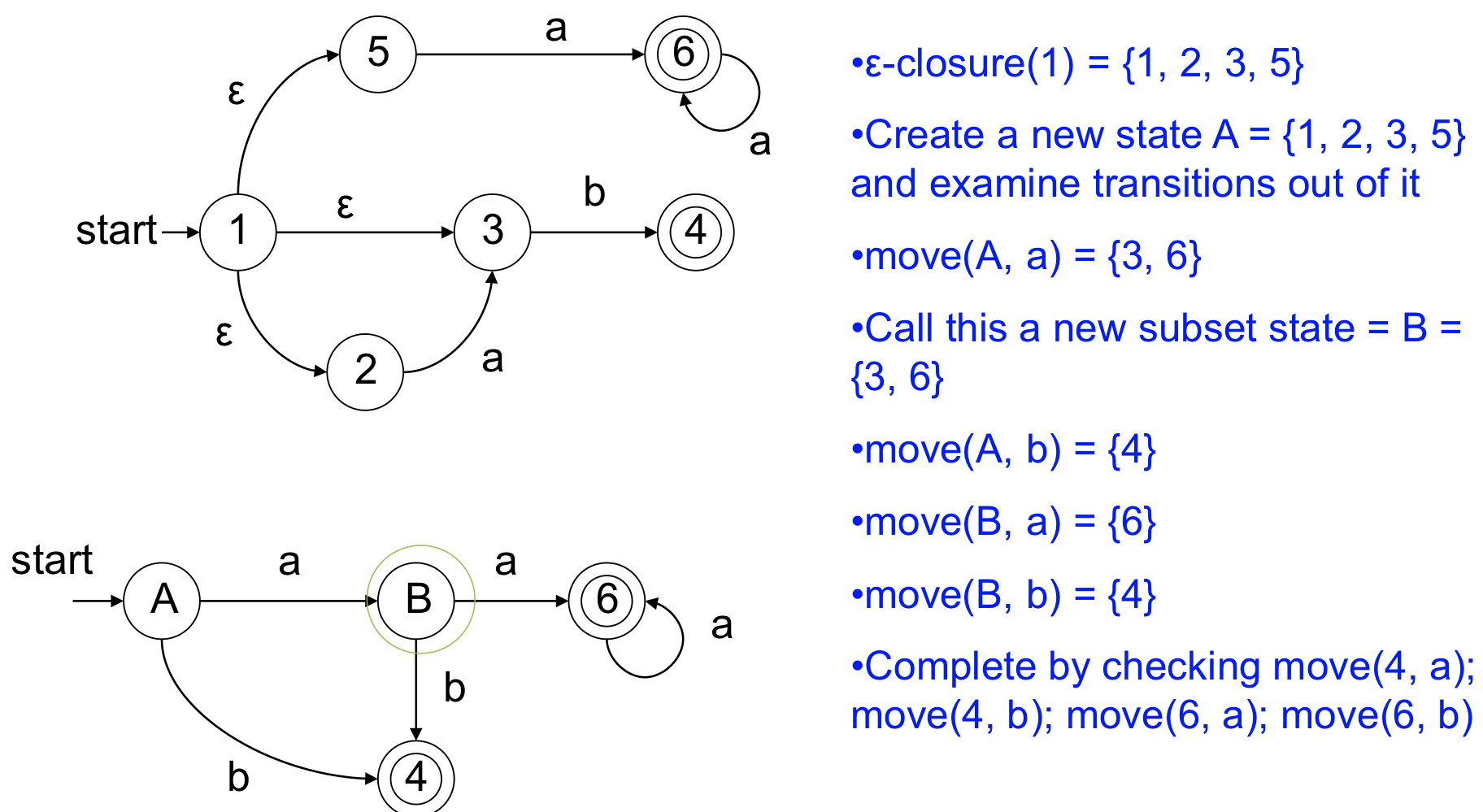
ex) RE = a + b*

- State가 추가되고 테이블이 좀 더 늘어나는 것을 알 수 있다
- final state가 들어간 state들은 모두 final state에 넣어줘야 한다.
문제 2. Empty transitions
- Empty transiton으로 가는 state를 모두 합쳐서 하나의 state로 만들어준다 : part of the state
엡실론 closure : any state s을 empty transition으로 도달할 수 있는 모든 state를 하나의 epsilon clousre로 만든 state를 이용해서 dfa를 만듦
ex) RE = ab
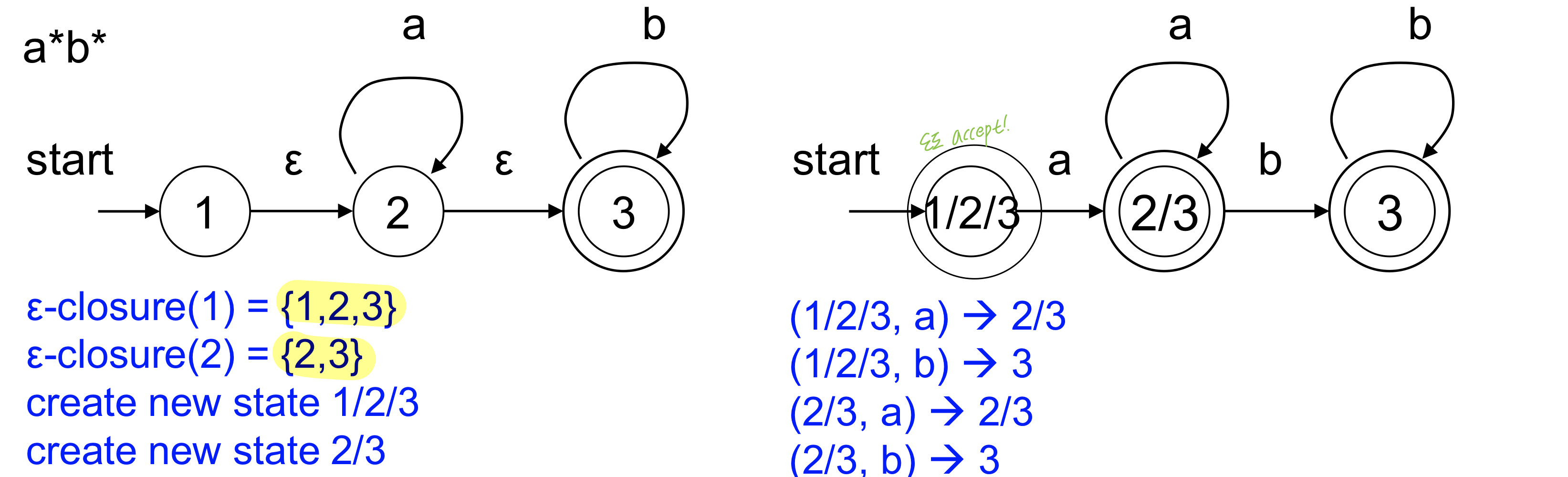
각 state의 closure를 새로운 state로 해서 DFA를 만든다.
ex) NFA → DFA
optimization(NFA→ DFA Optimizations)
자세히 다루지는 않을 예정
- Nfa자체에서 empty cycle이나 empty transition을 삭제
1) empty cycle removal
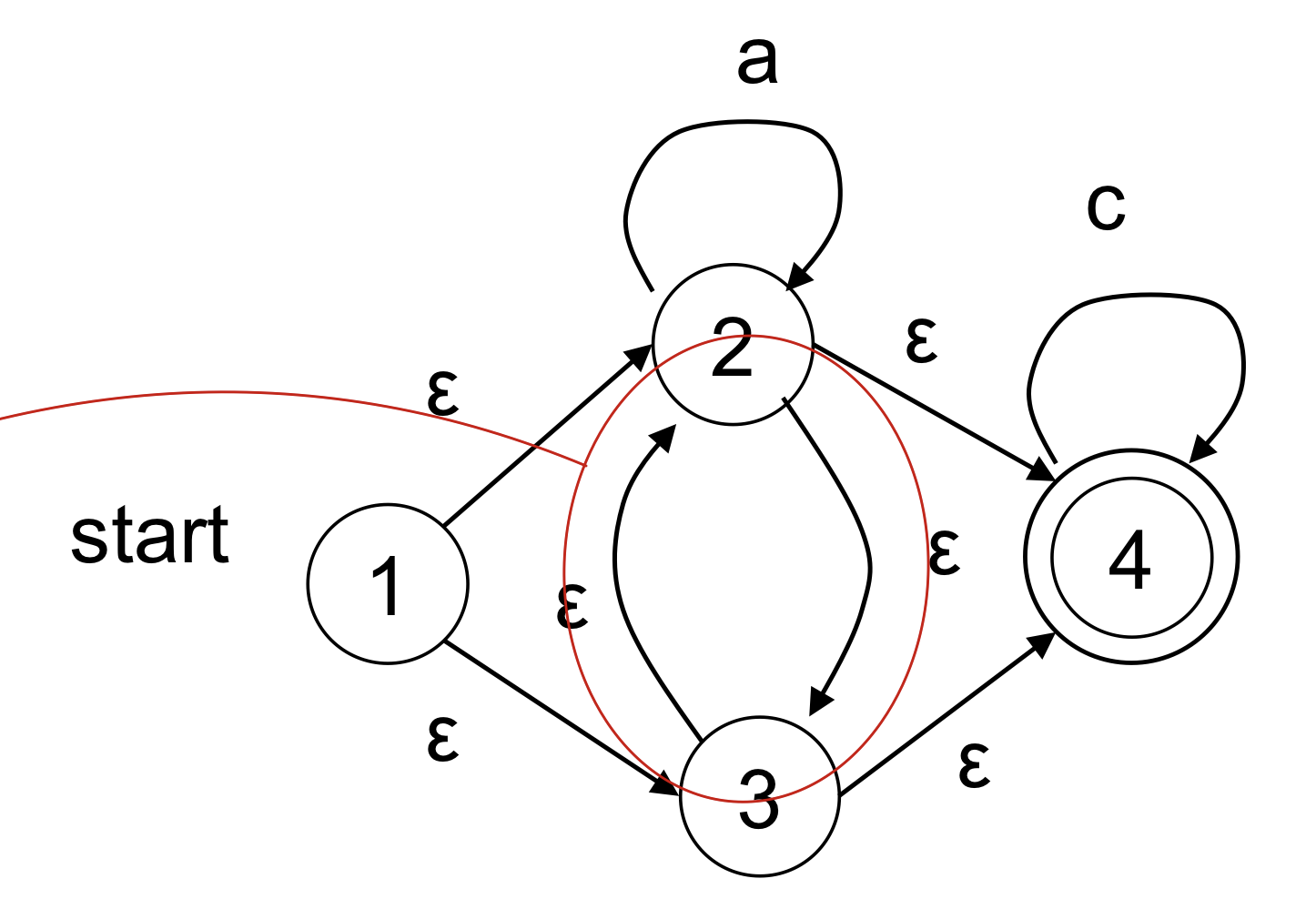
2) empty transition removal
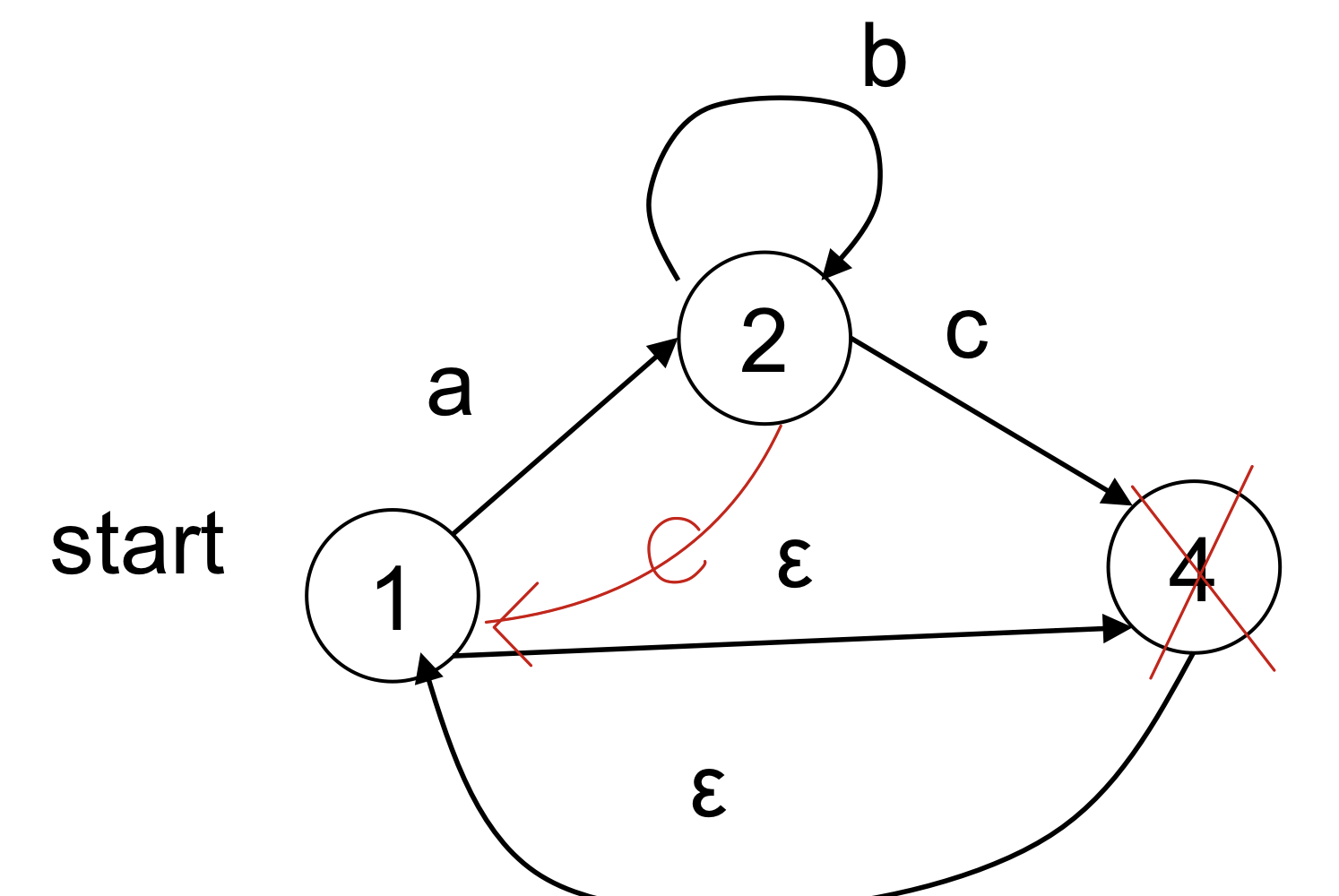
State Minimization(DFA를 최적화)
State들이 nfa->dfa하면서 수가 증가하므로 rebundent한 state들이 생길 수 있으므로 간결하게 만들 수 있고 간결하게 만들어야 테이블이 메모리에 저장되기 떄문에 수가 많을 수록 크기가 커지게 되기 때문에 효율적으로 사용하기 위해 minimization이 필요
- redundant, equivalent state를 합친다
- 똑같은 state의 그룹을 찾아서 합치면 된다(indistinguishable state들을 합쳐주면 된다.)
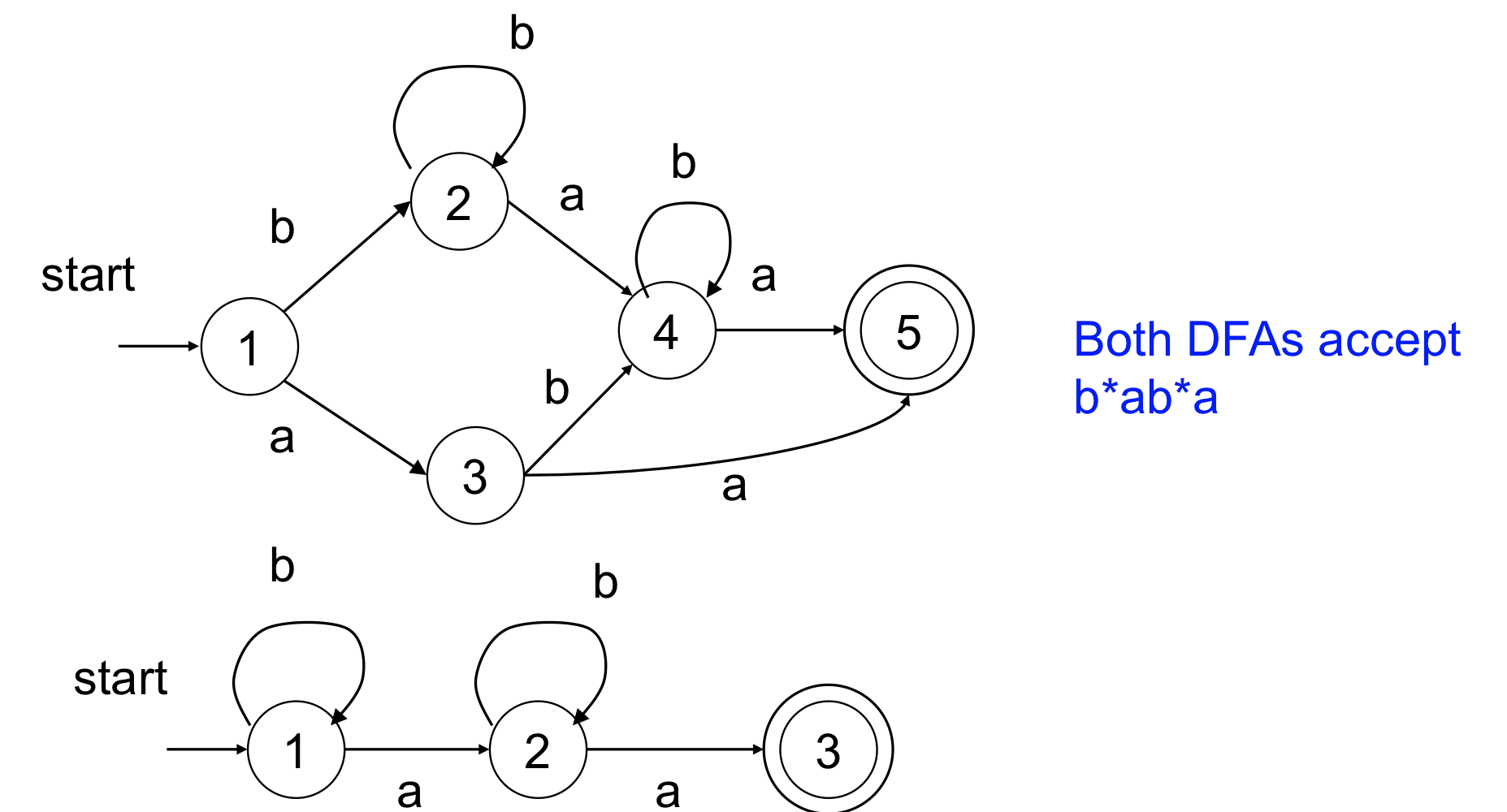
- Re를 만들어서 nfa -> dfa-> 최적화 -> 프로그램 -> token stream
Simulating the DFA
Output DFA가 나오면 이용해서 시뮬레이션을 하게 되는데 어떻게 만들어질까?

- 각각의 state, input에 대한 transition은 table로 표현 가능하며 table lookup은 current tate/input으로 어느 state로 가야하는지 알려준다.
- 각각의 state에서 transition이 일어날 때 테이블로 만들어주고 table lookup으로 수행하게 됨
- Transition table의 input으로 state와 input이 나오게 되고 accept state를 지정함(final state들의 state)
- 캐릭터를 하나 읽고 캐릭터가 없을 때까지 state가 변하게 되고 도달할 state가 없으면 error로 간다
- 테이블을 만들어서 table lookup으로 input character 하나와 지금의 state로 시뮬레이션한다는 것이 중요
Handling multiple REs
각각의 프로그래밍 언어는 다양한 re를 handling하기 위해 nfa를 만들 때 e transition으로 다양한 옵션을 준 후 이것을 dfa로 변환하면 됨
lexical analysis의 남은 이슈
- Token stream으로 받아야 하는데 toekn들이 final state로 도달 시 중요한 단어들을 저장해줘야 한다(Token stream at output)
-
Multiple match가 있는 경우 좀 더 긴 걸 선택해야한다(longest match)
→ final state에 갔을 때 여기서 좀 더 transition을 하면서 final로 갈 수 있는지 보고 갈 수 있다면 그걸로 하고 없다면 지난번에 갔던 데로 가면 된다
- 토큰이 만들어졌을 때 키워드인지 identifier인지 알아야하는데 이건 rule priority로 판단 가능, final state에서 가장 priority가 높은 토큰과 연결한다