CFG를 이용해서 syntax 룰을 지정하고 이걸로 Parsing을 수행하며 간단한 Predictive parser에 대해서 알아보았다(top down parsing)
단, 커버리지가 좋지 않기 때문에 많이 사용하는 bottom up parsing에 대해서 알아보자
Bottom Up parsing(LR grammar)
- 좀더 파워풀하고 lr grammar를 이용할 것(LL grammar보다 더 비싼 편)
- Topdown parsing은 rightmost derivation을 사용하는 거였다면 대부분의 연산자가 left associative가 많기에 lr grammar에서는 left recursive grammar를 사용
- right most derivation을 backward로 이용
- token에서 시작해서 production rule을 거꾸로 사용하면서 반복적으로 파싱을 수행하면서(RHS를 LHS로 replace) terminal들이 점점 nonterminal로 합쳐지다보면 start symbol에 도착
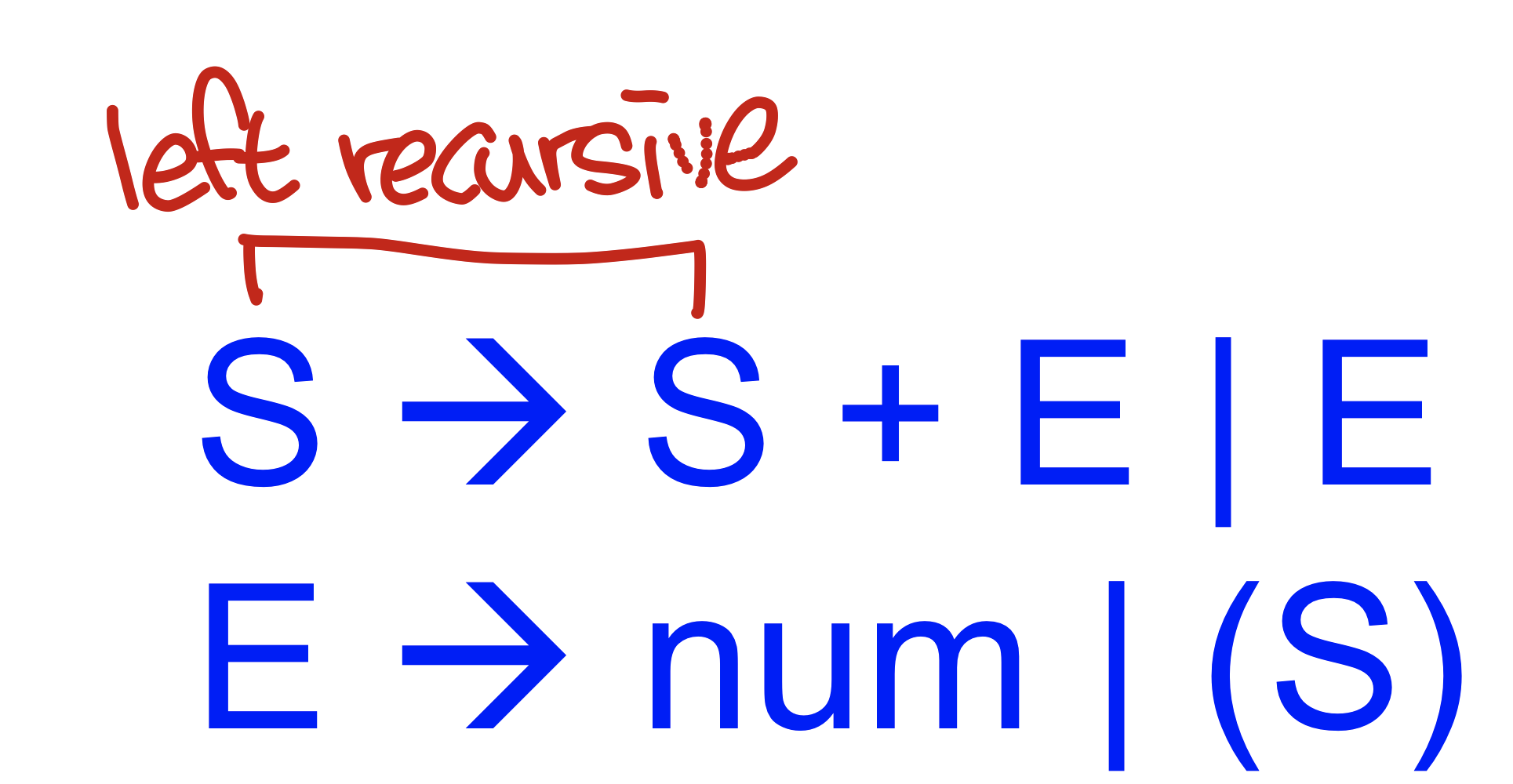
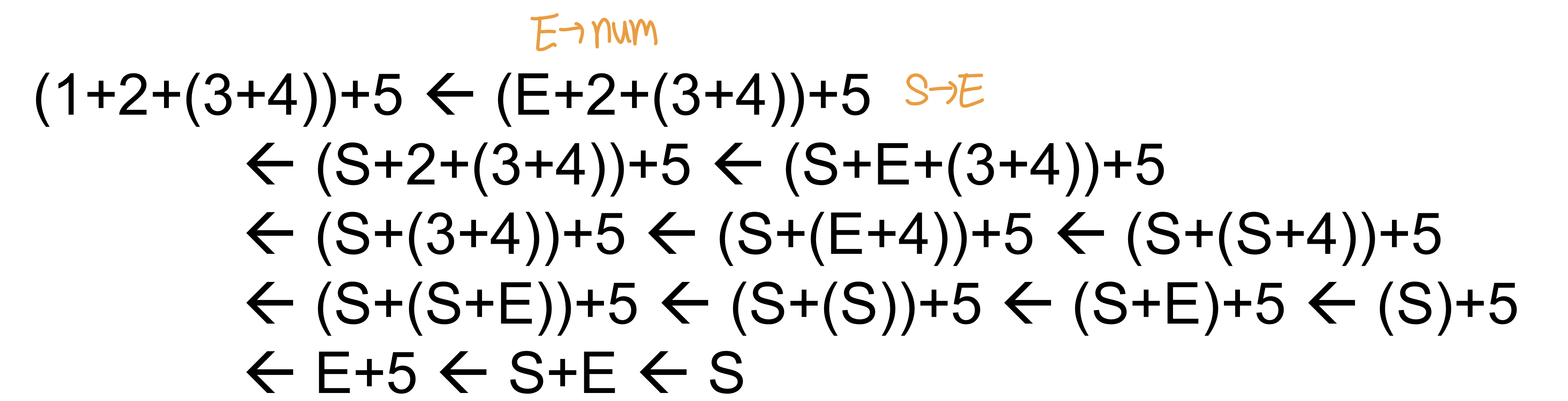
- 오른쪽 production rule을 nonterminal로 바꾸는 과정을 iterative하게 반복
- 반대로 production rule을 적용 - reduce
- 기본적으로 shift-reduce parser가 사용된다.
- LR grammar를 위한 parser(LL grammar는 커버리지가 낮아서 사용 불가능)
- Automatic parser generator(yacc,bison)들이 사용함
cf. 연산순서와 derivation 순서는 반대인 게 좋다.rightmost derivation에는 left associative grammar(left recursive grammar)에 유용, leftmost derivation에는 right associative grammar가 유용
→ rightmost derivation이다보니 left recursive grammar에 유리
-대부분의 언어는 left resursive grammar일 확률이 높음
-top down : S → 토큰
-bottom up : 토큰 → S,S가 나오면 에러가 없음을 감지
Bottom up parsing의 장점
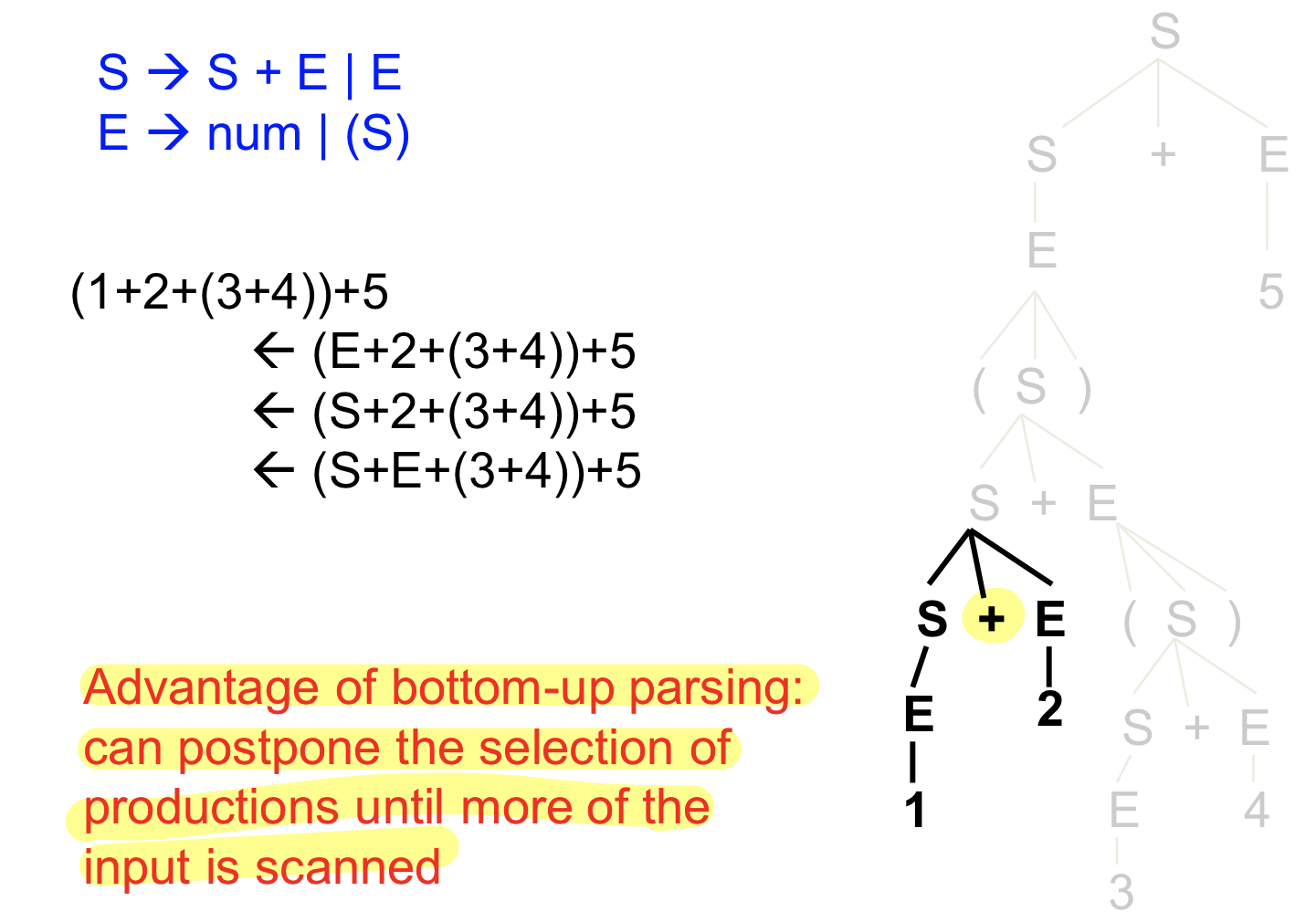
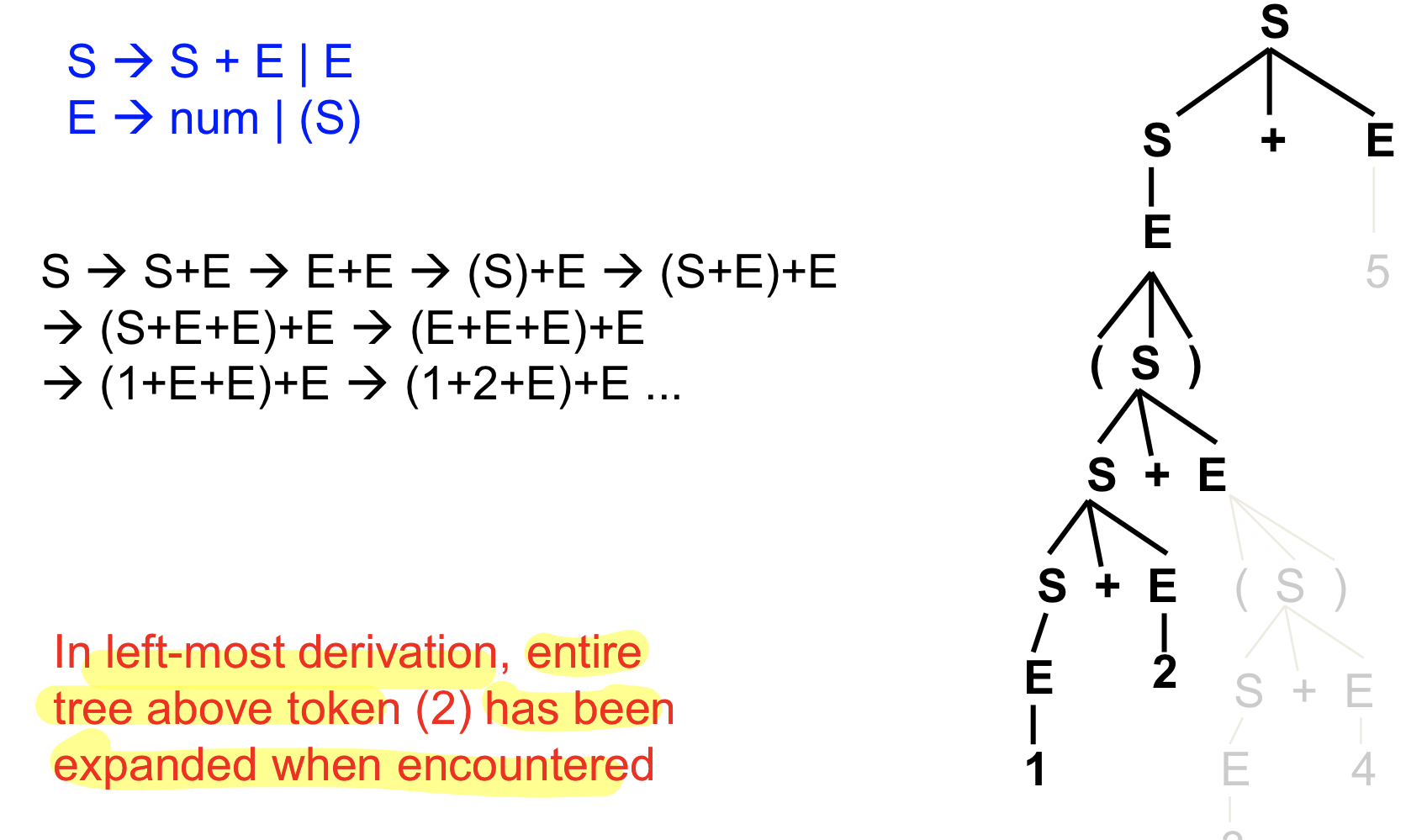
⇒ top down parsing과 달리 하나의 input을 보고 바로 production rule을 지정하지 않아도 된다. top down의 경우에는 lookahead symbol을 보면 바로 production rule이 지정되어야 하지만 bottom top은 더 스캔해서 production 지정을 미룰 수 있다.
(단, state를 좀 더 많이 보기 때문에 시간이 더 걸릴 수 있다)
LL vs LR
- LL(K)
- input token stream을 왼쪽부터 스캔 : Left to Right scan of input
- Left most derivaiton을 이용해서 파싱을 수행 : Left most derivation
- k symbol lookahead
→ top down(predictive) parsing or LL parser
-pre order traversal of parse tree 수행
-right recursive grammar
- LR(k)
- 스캔은 똑같이 스캔을 왼쪽에서 오른쪽으로 본다 : Left to right scan of input
- right most derivation으로 수행 : right most derivation
- k symbol lookahead
→ bottom up or shift-reduce parsing or LR parser
-post order traversal of parse tree 수행
-left recursive grammar
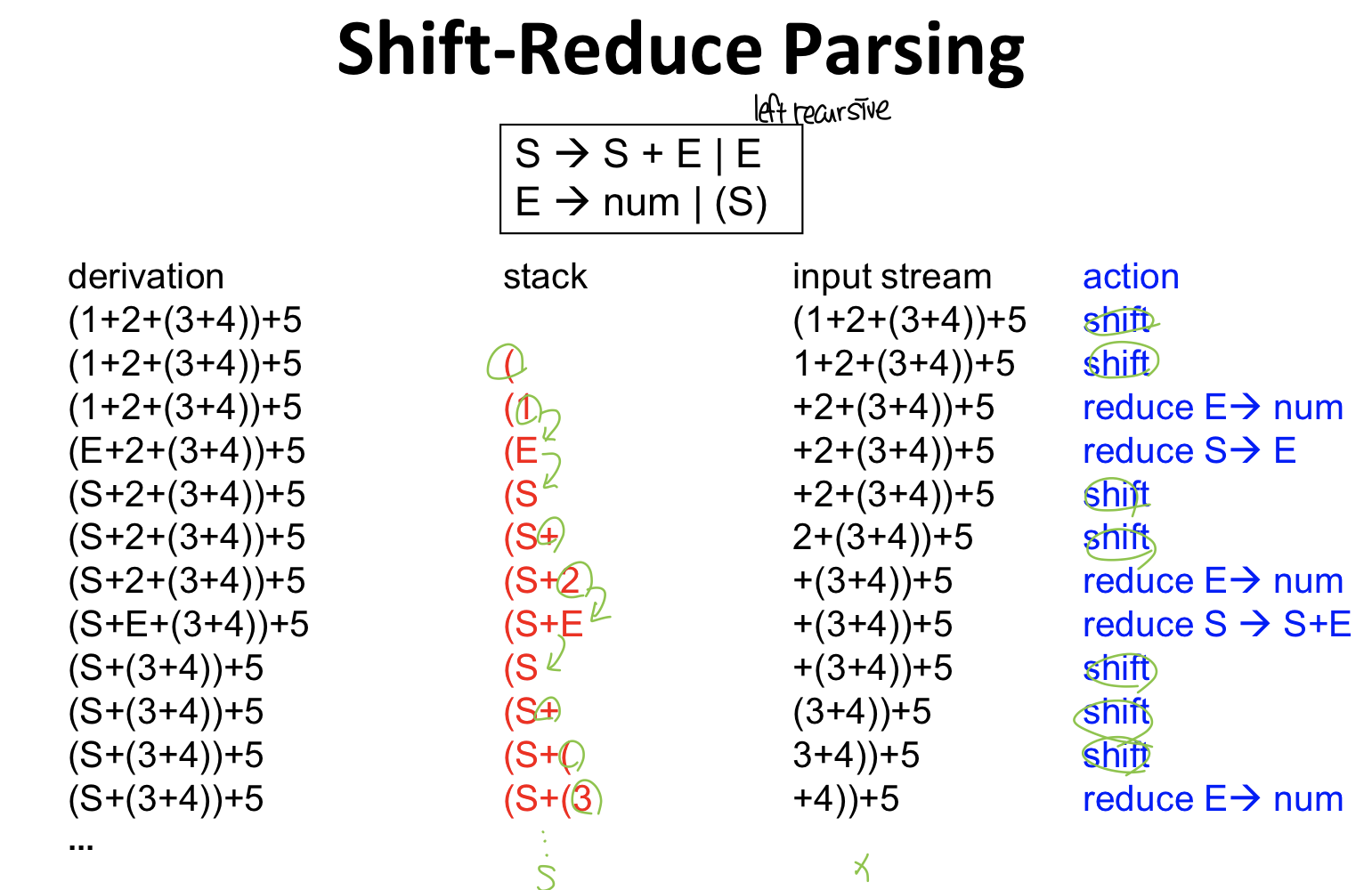
Shift reduce parsing
state를 저장하면서 shift, reduce action을 통해서 state를 바꿔가면서 파싱하는 것이 shift reduce parsing
- parsing actions : 파싱 시 shift와 reduce라는 두개의 operation을 통해서 파싱을 수행
- 파싱 수행 시 현재의 parser state를 가지고 있어야 한다.
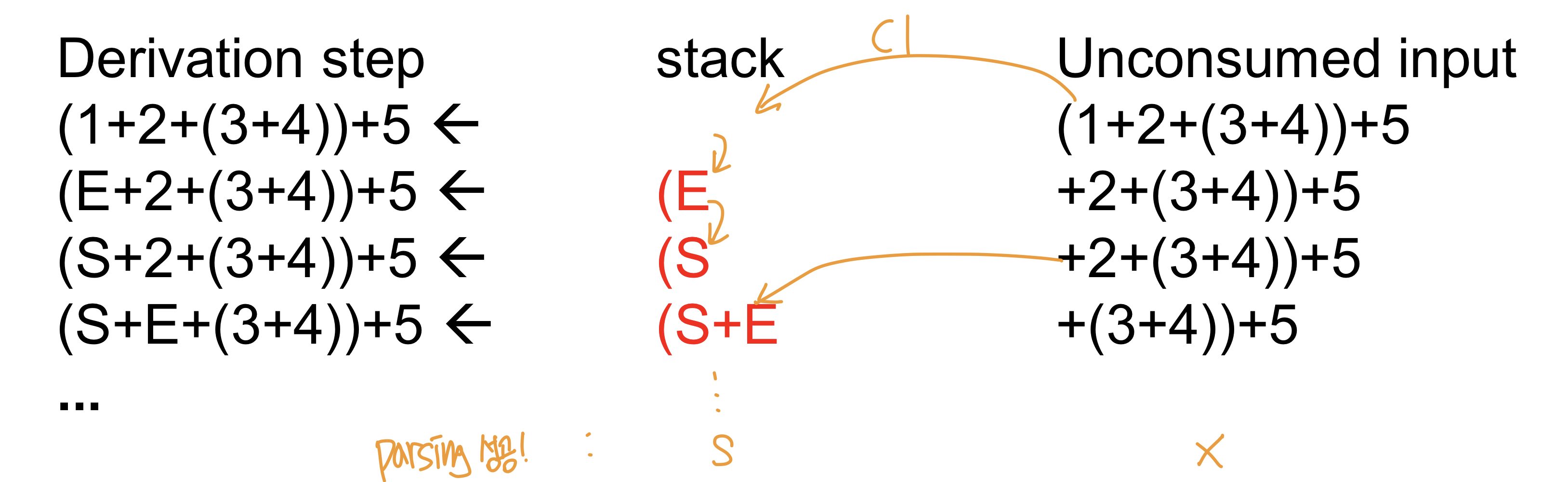
⇒ Parser state : 스택에 들어있는 terminal과 nonterminal의 모임(right방향으로 커짐).
- 지금까지 parsing한 상태를 알려줌, 스택을 활용해서 스택에는 nonterminal, terminal의 조합으로 구성되어있으며 스택은 왼쪽에서 오른쪽으로 커지면 last in first out(처음 들어간게 제일 나중에 나옴) empty stack이었다가 parsing하면서 한 방향으로 커지고 스택이 token stream을 하나씩 보면서 스택이 다 비워지고(S만 남음) token stream을 다 봤다면 문제없이 된다
⇒ 스택에 terminal,nonterminal을 넣었다 뻈다 하면서(shift, reduce 반복)해서 파싱을 수행해서 스택에 s가 나오면 성공함을 알 수 있음
- current Derivation step : 현재의 스택과 현재의 Input
- 현재 parsing을 할 수 있는 스탭은 하나의 스택과 하나의 input tokend으로 알 수 있다. input의 일부가 stack에 들어가 있고 derivation 반대방향으로 작업을 하면서 스택 안에 token stream이 parsing된 상태로 들어가고 input stream을 하나씩 넣으면서 파싱하게 된다.
Shift-reduce actions
- 파싱은 Shift와 Reduce의 연속
Shift
Lookahead token(보지 않았던 토큰들의 제일 왼쪽 토큰)을 스택에 넣는 작업
- input에서 맨 왼쪽에 있는 토큰을 스택에 저장하자
- 스택에 저장할 경우 TOS가 추가되고 거기에 새로운 토큰이 들어간다.

Reduce
스택의 맨 위에서부터 어떠한 심볼(b)이 있을 때 스택에서 b를 빼고 nonterminal x를 넣는 작업
(x→ b, pop b, push x)
- x→b라면, X가 베타로 expand되는 것이기에 x는 하나의 nonterminal이고 베타가 더 길기 때문에 베타를 빼고 x를 넣으므로 스택이 좀 더 작아지기에 reduce라고 한다
-
rightmost derivation을 거꾸로 해서 start symbol로 바꿔주는 작업

S->s+e라는 룰을 이용해서 reduce를 하는데 여기서 tos에 있는 심볼들만 작업이 가능함 tos에 이게 있으면 이걸 pop해서 추가하는 것, reduce 시 lookahead는 전혀사용되지 않는다. 스택에 집어놓고 줄이는 과정이 있는데 shift는 새로운 토큰을 스택에 추가하는거 reduce는 현재 스택에 있는 값을 줄이는 작업, pop하고 하나의 nonterminal로 바꿈.
⇒ 스택이 작아지다가 start symbol로 돌아오게 되면 파싱에 성공한 것
cf. 여기서 reduce기 때문에 pop과 push의 수는 대략적으로 pop이 더 많을 것, s->e라면 pop하면 s를 넣으면 되지만 일반적으로는 pop이 더 많은 편 푸시는 항상 한개!(사실 뒤에 state도 푸시해야하기 때문에 *2를 해줘야하지만 push는 항상 하나의 nonterminal만 한다.)
shift-reduce 시 두 가지 문제점
1) 어떠한 상황에서 lookahead symbol이 있고 스택에 nonterminal,terminal이 있을 때 shift랑 reduce 중에 뭐할 건지 결정해야 한다(reduce를 할 수 있을 때가 있고 하면 안되는 경우도 존재)
2) reduce할 때도 룰이 여러개 있을 때 어떠한 reduce rule을 적용할 것인지 결정
- Shift는 lookahead를 넣는거지만 하나의 작업이지만 reduce는 몇개의 조합을 가지고 reduce작업을 해야하는데 여러가지 production rule에 거칠 수 있기에 어떠한 reduce를 수행할 것인지 파악해야 한다.
Reduce를 해야하는지 shift를 해야하는지? 만약 한다면 어떤 걸로 해야하는지?
→ state를 지정해서 해보자
Action selection problem
- stack에 beta라는 긴 문자열이 있고 lookahead symbol이 beta일 때
- b를 넣어야(shift) 할까
- beta=ar이라면 x→r이라는 production rule을 사용해서 ar에서 aX로 reduce를 해야 할까??
-
스택에 ar가 있다면 a를 보고 reduce를 할지 shift를 할지 판단할 수 있음
x->r라면 감마가 매칭되어서 x로 바꿀 수 있지만 알파엑스가 최종적으로 맞는 reduce인지는 a로 판단해야 한다
lr parsing을 만드는 방법
basic mechanism
- Parser state를 지정 : 현재 스택의 상태를 대변해주는 것을 parser state라고 한다.
Ex) 200개의 non이 들어있을 때 parser state를 지정해주면 앞에 많은 애들이 있지만 parser state에 지정된 대로 액션을 취하면 제대로 파싱이 될 것이다라고 알려주는 것이 parser state
- Parser state는 스택에 들어있는 과거의 히스토리를 압축한 것이라고 볼 수 있음(미래를 보기 위해 과거를 저장하는 그런 느낌)
- 스택에서 reduce, shift는 모든 substring을 봐야 지정할 수 있지만 stack으로 pop해서 다 볼 수는 없으니까 대변할 수 있는 state를 지정
-
stack에 symbol과 state를 동시에 집어넣음. State를 집어 넣어줘서 현재 state의 상황을 알려줌
- Parsing table을 만들어서 어떠한 액션을 취할지와 다음 state는 무엇인지 지정해준다.
- Parser action은 parsing table을 통해서 determinisitc하게 지정할 수 있다
LR parsing table
Topdown 보다 훨씬 복잡한 편(table의 size가 커짐)
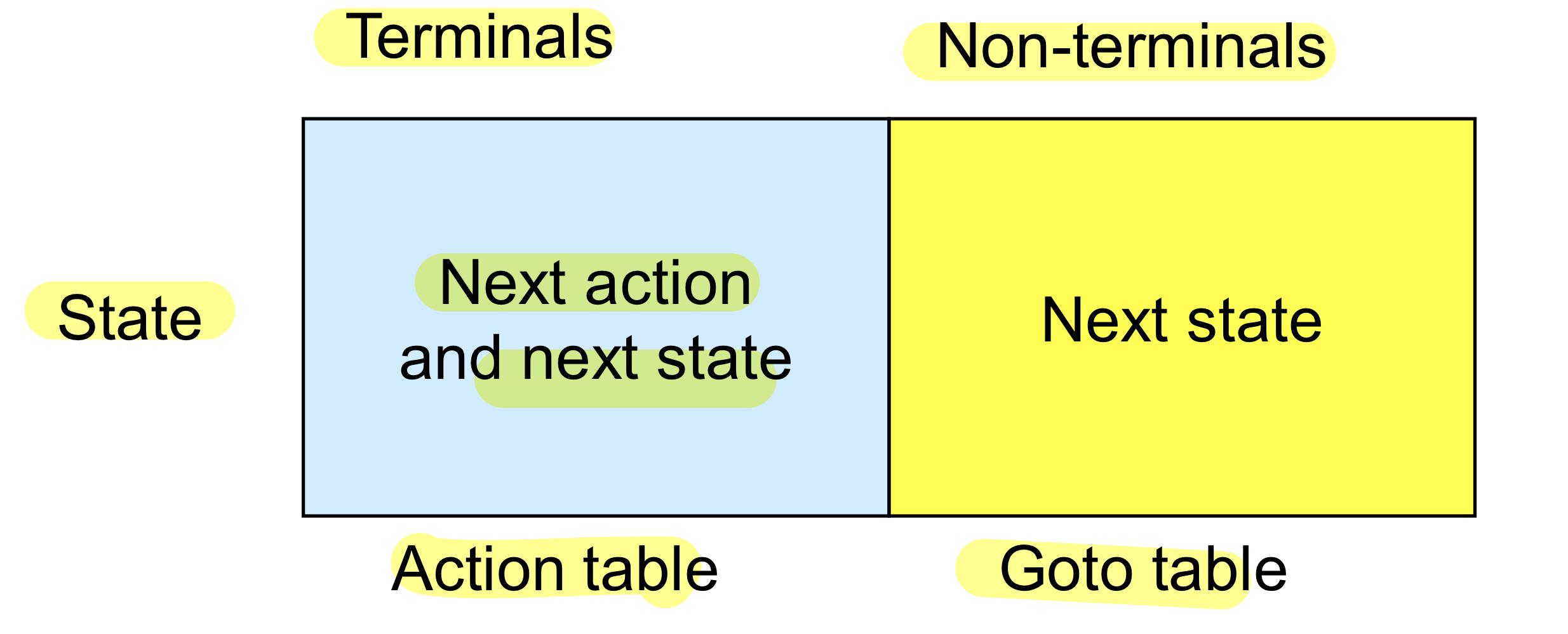
- Row는 state로 구성되며 column은 terminal과 nonterminal로 구성
- State와 terminal로 이루어진 부분에는 현재 어떤 액션을 취할 건지 next state가 무엇인지 지정 : action table
- State와 nonterminal이 있을 때에는 next state만 지정 : goto table
- 현재의 current state S 와 input terminal C로 action 결정

Shift를 해서 s’라는 새로운 state로 바꿔야 하던지 production rule이 있다면 알파를 찾아서 뽑아내고 그 자리에 x를 스택에 넣어주는 작업을 수행
여기서 pop에 2를 곱한 이유는 알파의 non,ter과 state가 들어가기 때문. pop한 다음에 s’가 top이며 알파만큼 빠졌을 때의 스택의 현재 state를 top이라고 지정할 수 있으므로 그걸 s’로 지정한 다음에 x를 넣어주고 현재의 top(s’)과 reduce 결과인 x라는 Non으로 새로운 next state를 찾고 스택에 저장(goto table)
Lr parsing table을 자동으로 만들 수 있으면 parsing을 수행할 수 있게 됨
ex) LR parsing table
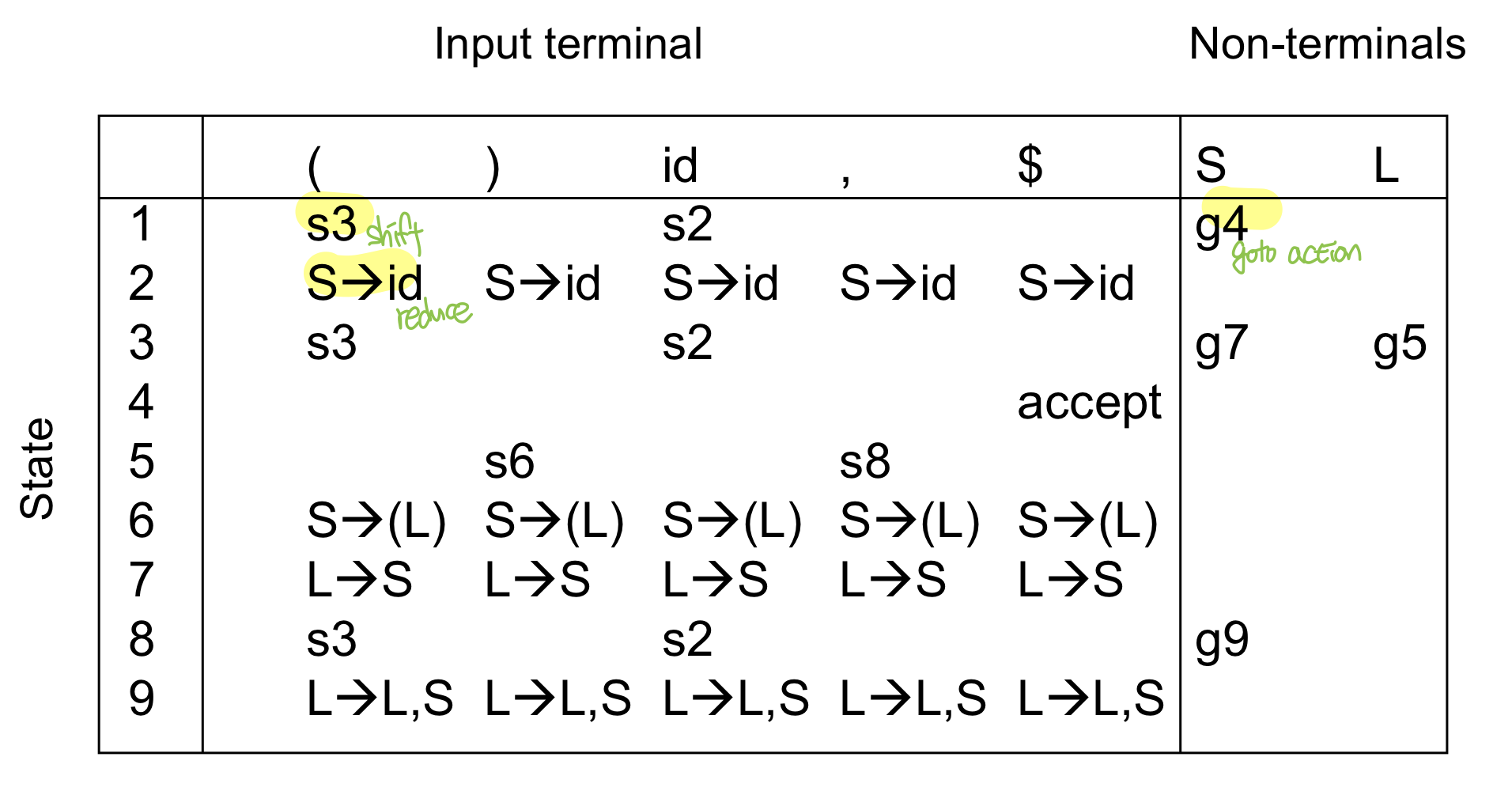
LR(k) grammar
LR(k) = left to right scanning, right most derivation, k lookahead chars
- main case : LR(0), LR(1), SLR, LALR(1)
- Lr(1)이 커버리지도 높고 좋은 그래마이지만 너무 복잡해서 단순화할 수 있는 slr, lalr(1)을 많이 사용함
- 우리는 lr(0)로 만들 예정
- lookahead를 보지 않고 action을 결정할 예정
- shift-reduce parsing 이해에 도움이 될 것
Building LR(0) parsing table
parsing table을 build하기 위해서
- Parser의 state를 지정
- state들 사이에 있는 Transition을 서술하는 DFA 만들기
- DFA를 이용해서 parsing table을 만들 것
Lr(0 ) state는 set of LR(0) item으로 구성
LR(0) item :x→ab라는 production rule이 있을 때 중간에 .을 추가한 것을 말함
. : 지금까지 스택에 어디까지 들어와있다를 의미
ex) x→ a.b
파서에서 a까지는 스택에 top에서 매칭할 수 있다를 알려주는 것,b가 스택에 들어오면 ab가 다 들어왔음을 알 수 있다.즉, . 은 a가 스택의 탑에 저장될 수 있으며 b는 아직 안들어왔다는 의미가 된다
- LR(0) item은 현재 파서의 possible upcoming production progress를 알려주는 방법
- .보다 앞에 있으면 이미 있다는 것이고(parsing이 가능한 부분을 의미) .뒤에는 token stream으로 볼 수 있지 않을까?를 의미
- LR(0) state = LR(0) item들의 모임
cf. stack의 TOS만 봐서는 a라는 스트림이 있는지 모른다. 따라서 스택의 맨 위에 몇 개의 데이터가 있는지 LR(0) item으로 알아야 하고 이것은 지금 스택의 TOS부터 최근의 history를 담고 있는 것이 state
→ 꺼내보지도 않고 TOS부터 몇개의 심볼을 봤을 때 a인지를 알기 위해 state를 저장, 나의 과거를 알려줌
ex) example LR(0) state
LR(0) item - RHS of production에 .이 어딘가 있는 production을 의미
cf. LR(0) item은 엄청 많아지기 때문에 LR(0) item만 가지고 state를 구성하면 너무 state가 많아지므로 동일한 작업을 할 수 있는 동일한 성격을 가지는 LR(0) item만을 모아서 LR(0) state라고 한다.
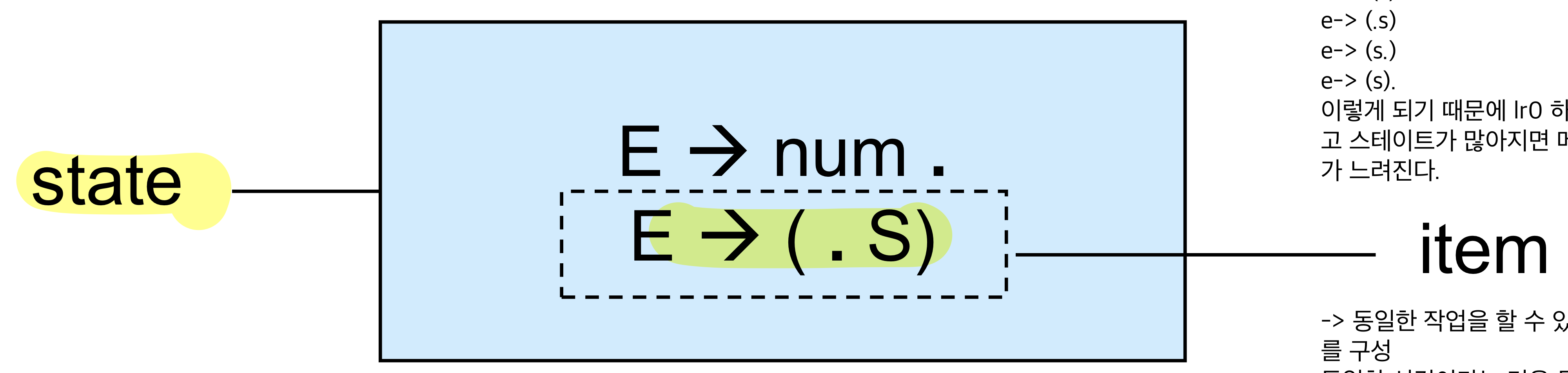
- substring before “.” : stack에 이미 들어있다
- substring after “.” : 우리가 보게 될 것
Q. TOS만 보면 왜 안될까?
A. 제일 위만 보다보니 과거에 저장한 것들을 보지 못하므로 state를 같이 저장
Q. state는 모든 history를 보여주는가?
A. no, reduce를 할 수 있는 parer string에 대한 history, 처음부터 끝이 아니라 reduce를 할 수 있으려면 어디까지 지금 지행해왔는지 어디까지 파싱을 할 수 있는 건지를 말한다. 전체 히스토리가 아닌 그 때 그 때의 parsable한 상황만을 나타냄. 물론 state를 같이 저장하기에 스택을 두배씩 사용하여 부담이 되지만 이렇게 해야 히스토리를 알 수 있음.
Q. LR(0) item만 가지고 parsing table을 만들 수 있는가?
A. 만들 수는 있지만 table의 사이즈가 매우 커지게 될 것
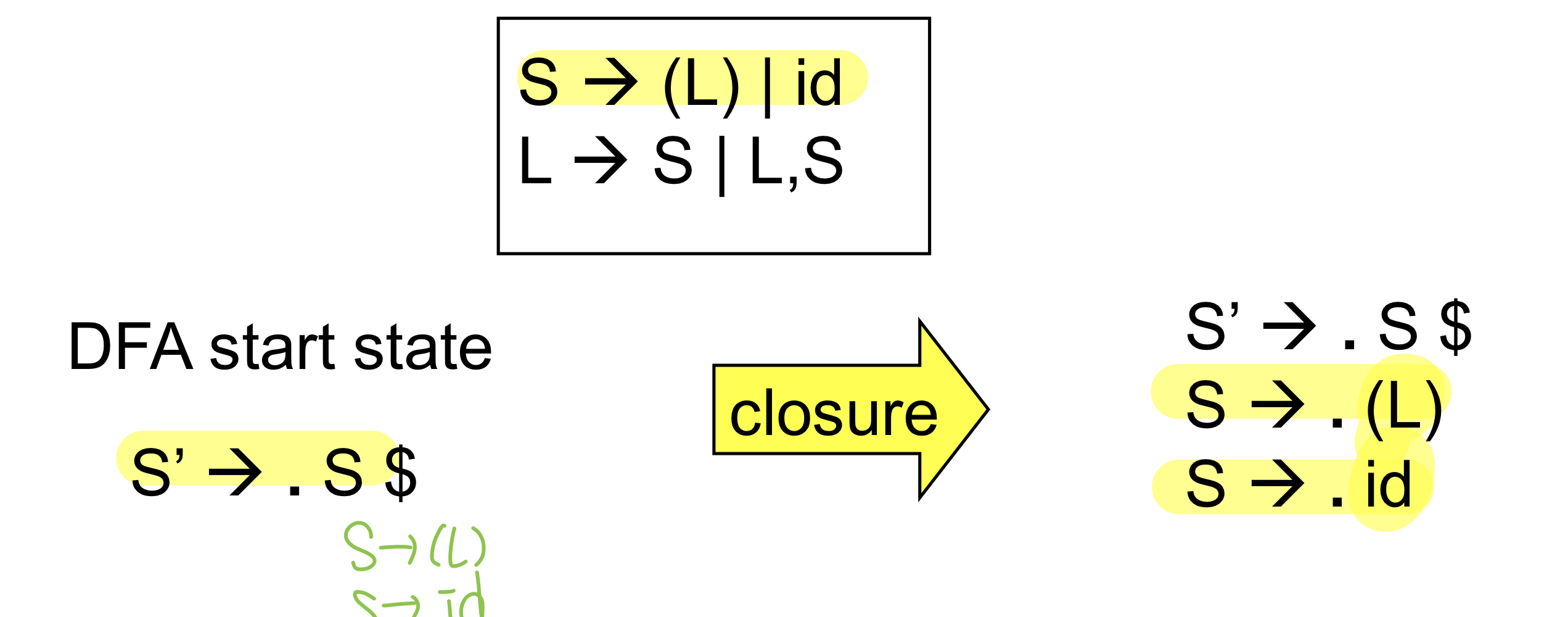
start state and closure
start state
- Production에서 start symbol을 s가 아닌 s’로 하고 s’-> s$로 시작하게 된다(augment grammar with production)
-
empty stack에서의 start state는 s’-> .s$로 시작함
cf. $는 문장이 끝났음을 의미하며 마지막에 s$를 만나면 끝내면 된다
closure of parser state
Closure는 어떠한 s가 가능한 모든 프로덕션을 말함

State s가 있을 때 s state를 넣어준 후 가능한 모든 production rule을 넣어주면 된다.
goto operation
Parser state사이의 transition을 표현
현재 state I 와 symbol이 있으면 I state에서 아이템이 존재하고 심볼 y가 있다면 아이템을 만들어주고 closure을 만들어주면 된다

Y를 스택에 집어넣어주면서 원래는 알파까지였는데 ay까지 추가되므로 .이 하나로 이동함
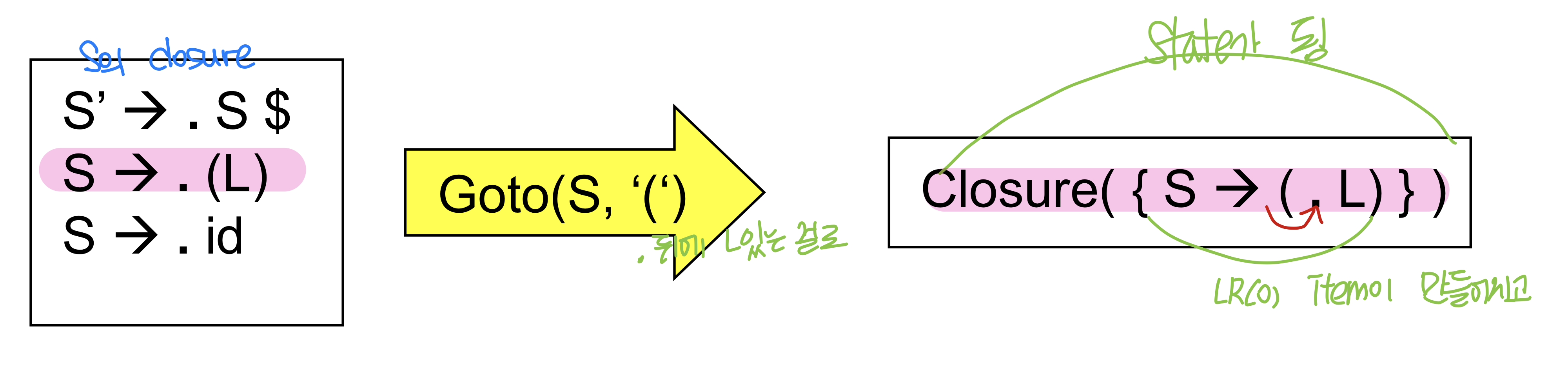
- symbol까지 스택에 넣어주고 추가한 item의 closure의 state로 이동
-
terminal symbol일 때 Goto action이 있지만 nonterminal에도 존재할 수 있다
### Goto : terminal symbols
lookahead symbol이 terminal이므로 스택에 하나씩 넣어주는 경우(shift) goto action이 일어난다
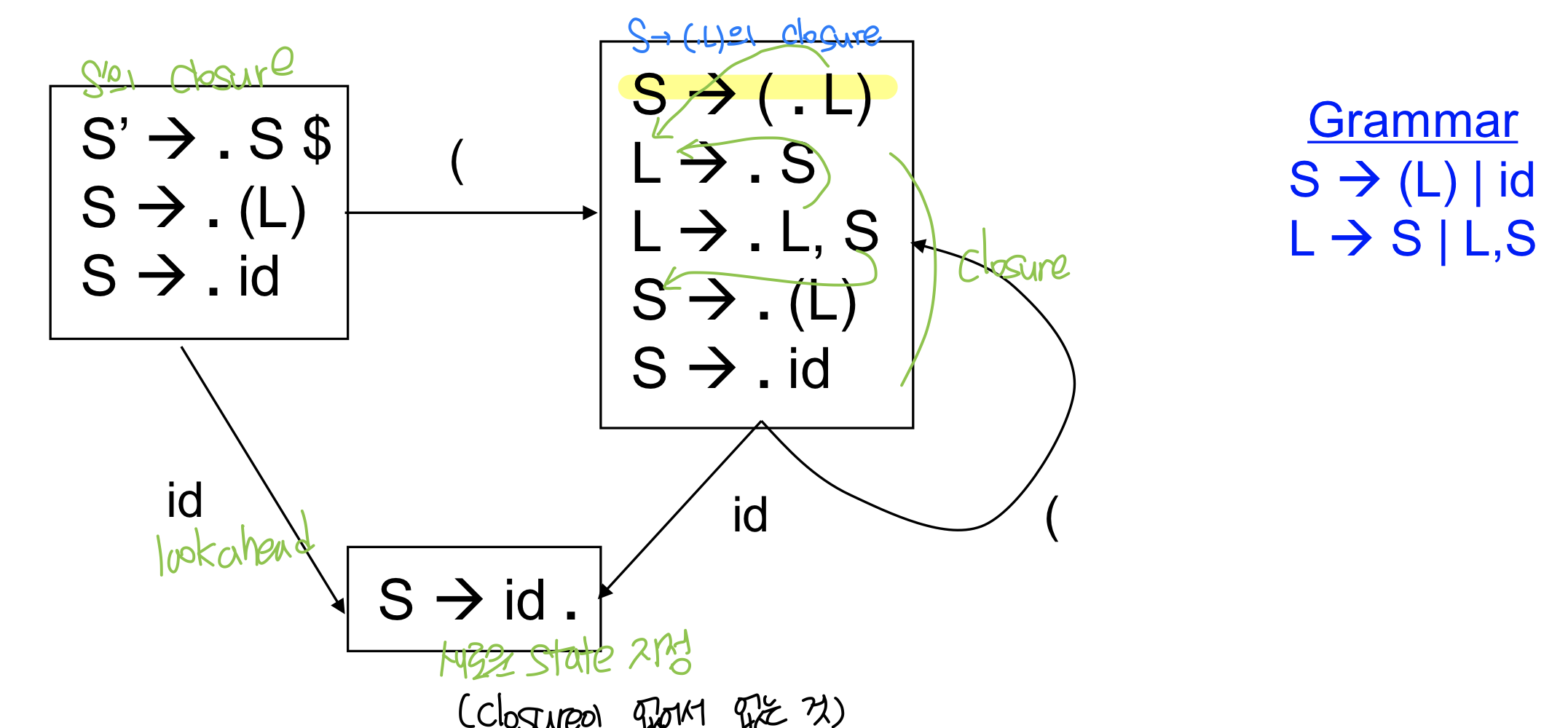
### Goto : Non-terminal symbols
input이 nonterminal일 경우는 reduce 작업 수행시 발생, reduce를 수행한다는 것은 문자열을 빼서 하나의 nonterminal로 바꾸는 것이고 top of stack을 봐서 next state를 만들기 때문에 nonterminal symbol도 봐야 한다.
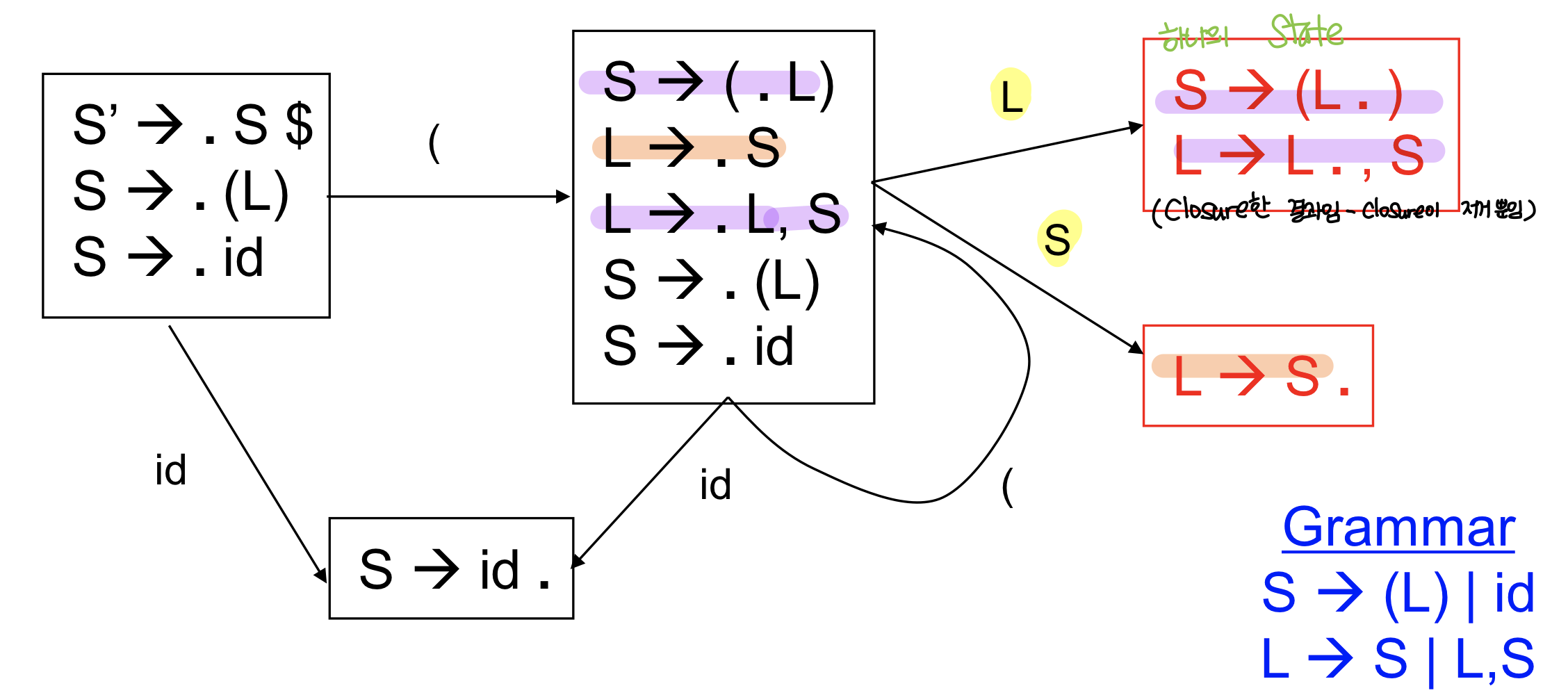
# Applying reduce actions
- 스택에 production rule의 right hand side가 모두 들어가야 하고 top에 있어야 한다.
→ .이 가장 마지막에 찍힐 경우 reduce가 가능하다.
- righthandside를 뺴고 lefthandside를 넣고 다시 DFA를 수행해서 DFA input으로 nonterminal을 수행해서 state를 업데이트 해주면 된다
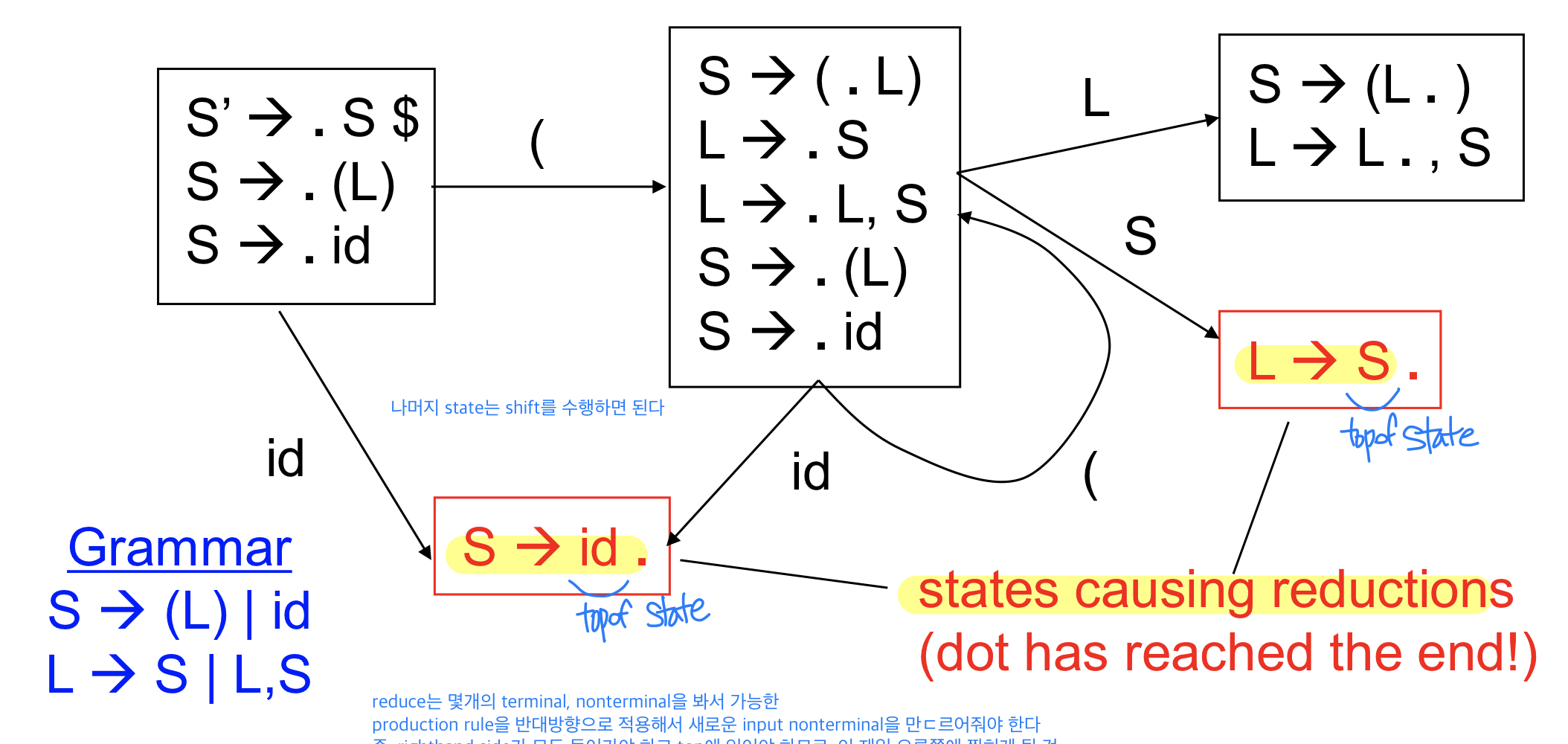
- .이 맨 뒤에 있지 않는 경우 reduce를 수행할 수 없으므로 shift 수행
Reductions
ex) on reducing X→ b with stack ab, b는 TOS
스택에 ab가 있고 b가 top이라면?? b를 빼면 a가 topofstack에 있을 것이고 그 떄의 state가 스택의 top에 있을 것 -> x를 스택에 넣은 후 DFA에 현재 state와 x를 넣어 새로운 DFA state를 지정하고 이걸 스택에 푸시해주면 된다.
-b를 빼면 a만 남고 a옆에 state가 있고 x 를 넣고나서 state를 넣어줘야하는데 새로운 state는 a 옆에 있는 state와 x를 이용해서 나온 state를 넣어주면 된다. backtracking과 비슷하게 옛날에 저장한 얘를 넣고 옛날로 돌아가서 다시 진행하는 것(실수 많이 하는 부분이니까 조심할 것)
ex)
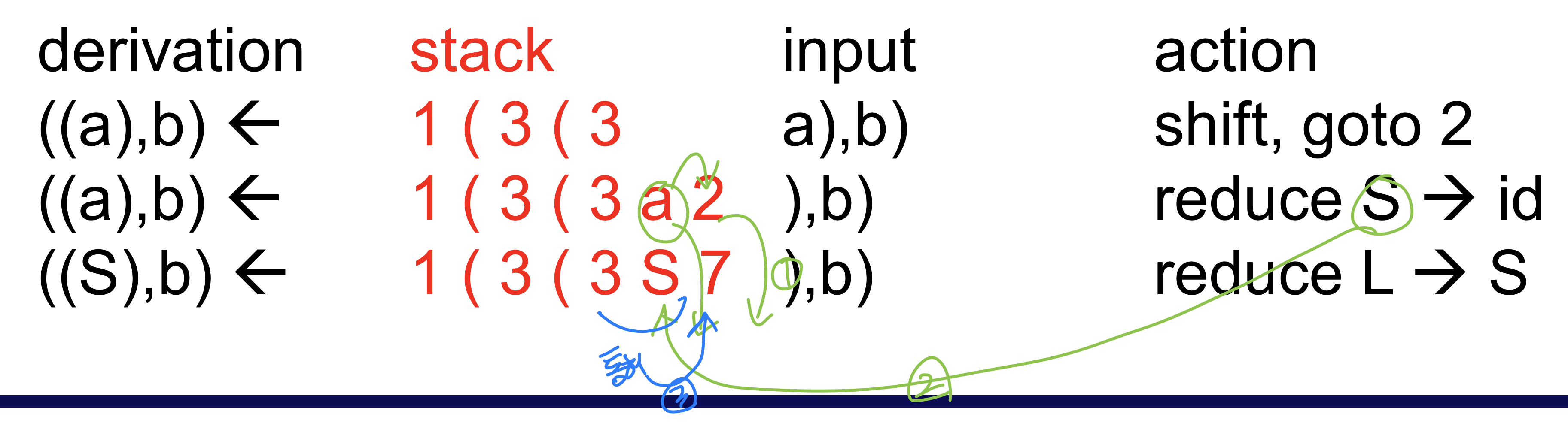
Full DFA
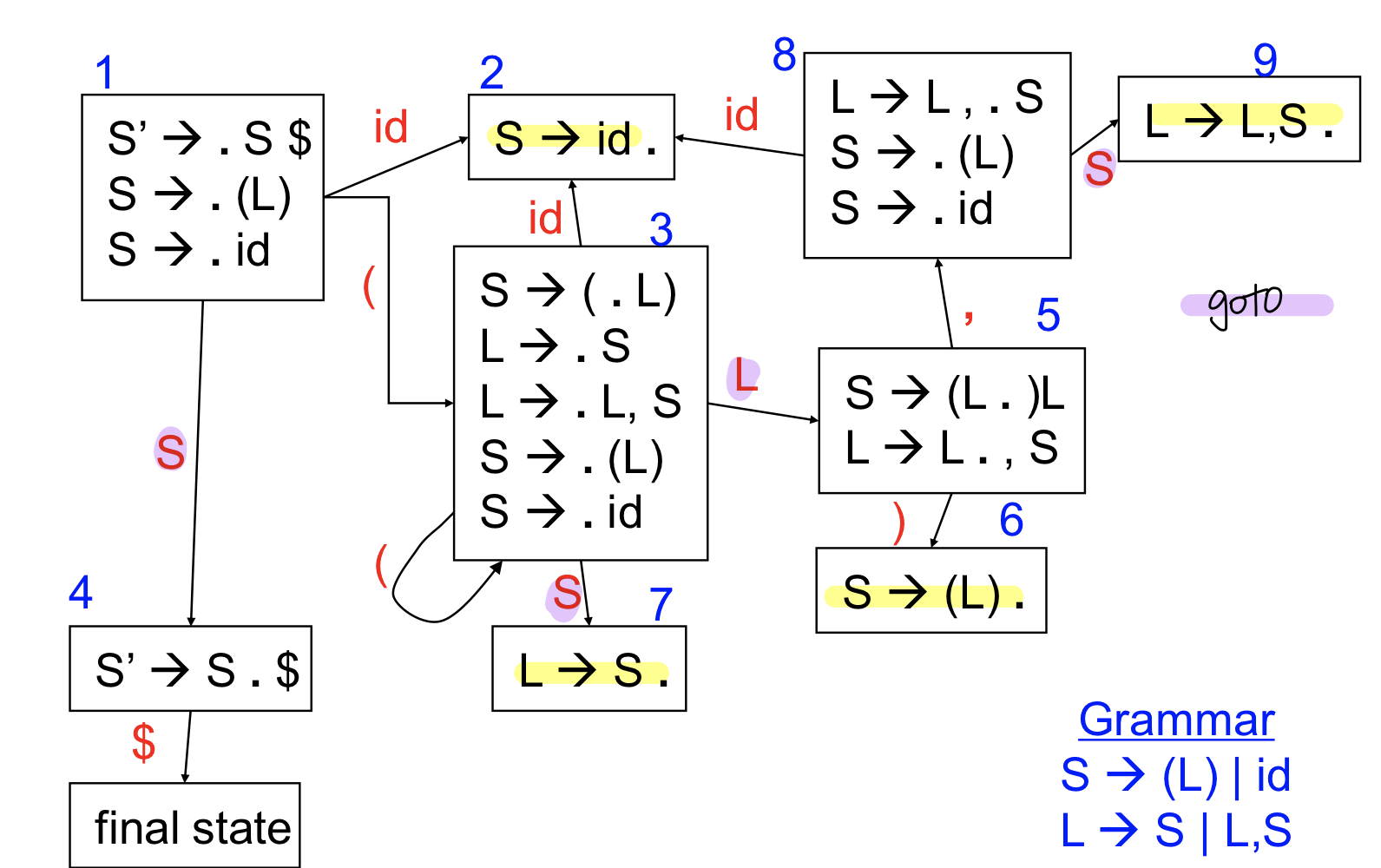

Parsing table만들기
- table의 State는 DFA의 state로 만들어준다
- S→S’ on terminal C ⇒ table[S,C] += Shift(S’)
⇒ table[S,C]에 shift(s’)를 추가해주면 된다. Termianl을 본다는 것은 토큰이니까 집어넣고 s’ state로 변하도록 한다
- S→S’ on terminal N ⇒ table[S,N] += Goto(S’)
⇒ Nonterminal이라면 goto를 하도록 한다.table[S,N]에 goto(s’)를 추가해주면 된다
주로 reduce를 한 뒤에 goto를 수행하면 된다
- S가 reduction state x→b ⇒ table[S,*] += Reduce(X→b)
⇒ Reduction을 해야한다면 s state에 대한 모든 테이블 entry에 대해서 Reduce(x→b)를 추가해주면 된다.
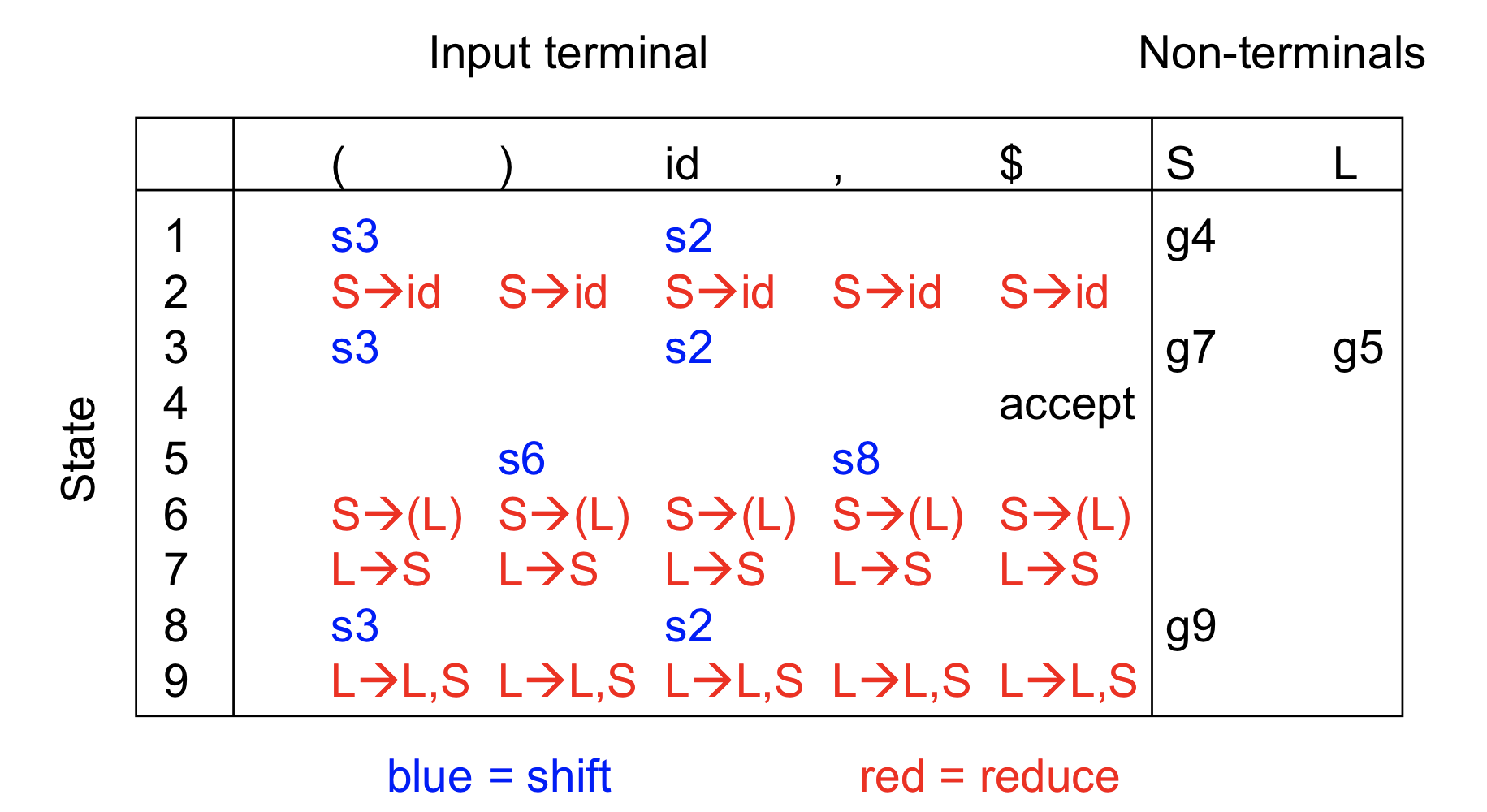
LR(0) Summary
LR(0) parsing recipe
- LR(0) grammar로 시작
- LR(0) state를 계산한 후 DFA를 만든다
- closure operation으로 state를 계산
- goto operation으로 transition 계산(terminal, nonterminal)
- LR(0) table을 만든다
Lr(0)grammar로 시작하고 이걸로 dfa를 만든다면 자동적으로 만들 수 있다.
cf. reduction state에서는 아무런 lookahead를 보지 않는다.left associative는 대부분 되지만 해봐야 안다