지금까지 Lexical analysis로 character stream-> token stream이 나오게 되고 syntax analysis으로 문법이 틀리지 않았는지 확인
→ 이제 바이너리를 만들어도 되겠다! Ast를 최종적으로 만들게되고 Machine independent한 어셈블리 구조로 Binary를 만들게 됨
Semantic analysis
- but, Lexical analysis, syntax analysis에서 문제가 없더라도 추가적인 문제가 있을 수 있음
- lexical analysis와 syntax analysis는 variable을 잘 사용하는 것 , function을 잘 사용하는 것에서 모든 에러를 잡아줄 수 없기 때문에 powerful하다고 볼 수 없다.
-
Variable 사용은 언어마다 특이한 경우가 있어서 문자열만 가지고 확인이 불가능
Ex) 이 변수가 어떤 타입인지 알아야 하는데 syntax에서는 나오지 않음. 이전에 define이 되었는지 선언되어 있는지 등등에 대해서 체크해줘야 한다. 이건 위 두개가 할 수 없음
-
⇒ semantic analysis : 프로그램이 usage of programming construct(variable, objects, expression, statement)에 관련하여 set of rule을 만족하는 것을 보장, 추가적인 오류를 체크해주는 것
- 의미적으로 프로그램이 correct하게 문제가 없음을 체크하는 것, 프로그램의 구조체 사용 시 사용법과 관련해서 적합한 룰을 지키면서. 프로그램이 잘 짜여 있는지 확인 여기서 구조체는 변수, 오브젝트, 수식 구문 등을 의미
Ex)
int a ;
a= 1.0;
integer로 지정되었는데 Floating point로 사용될 수 없다면 에러가 있을 수 있음 : maybe semantic error, 정수타입인 변수에 floating point 수를 넣었기 때문, tight하게 type 체크를 한다면 문제가 생길 수 있다, 문법적으로는 문제가 없지만 실제로 사용할 때 문제가 생기기 때문
semantic analysis의 카테고리
구조체들을 사용하는 룰을 지정해줘야 한다.
Examples of semantic rules
-
어떤 변수가 있을 때 사용되기 전에 define되어야 한다
← 이건 syntax에서 체크 불가능
- 어떠한 변수는 여러번 define되면 안된다
- 어떤 변수에 값을 assign할 때 변수와 수식은 결국 같은 타입이어야 한다
- If statement에서 test하는 수식은 항상 Boolean type으로 output이 나와야 한다
2 Major categories
1) semantic rule regarding types
Type(변수의 데이터 타입)과 관련된 룰
2) semantic rules regarding scope
scope(타입 정보가 얼마나 길게 어떠한 영역에서 효과를 나타낼 수 있는지)와 관련된 룰
1) Type information/checking
Type Information
여러 구조체에서(variable, statement, statement, expression) 어떠한 종류의 값들을 가질 수 있는지 설명해주는 것을 type information이라고 한다

변수는 int a 이면 정수일 것이고 구문은 bool이 나와야 하고 floating point가 저장될 것이다라는 정보를 알 수 있다 pow는 리턴은 Int고 Parameter로 int,int임을 알 수 있음
Type Checking
프로그램에서 각각의 구조체들이 실제로 정해진 타입의 룰(type consistency)을 잘 따르고 있는지 체크하는 rule의 set
ex) 어떠한 타입, expression이 bool로 나와야 하는데 bool이 나오지 않으면 type checking 때 에러가 나올 수 있고 혹은 int 변수에 fp를 저장하려고 하면 에러가 날 수 있게됨
2) Scope Information
- 각각의 identifier가 program에서 어떤 부분에서 사용될 수 있는지와 identifer의 declaration을 characterize한다.
example identifer : variable, function, object, labels
Identifier 4가지가 어떠한 영역에서 사용될 수 있는지 체크하는 것은 scope information이라고 한다.
lexical scope
- textual region in the program
- 코드를 보는 것, 프로그램 코드에서 Region이 정해져 있는 것
exampes : statement block, formal argument list, object body, function or method body, source file, whole program
위의 예시는 scope가 프로그램 안에 지정이 되어있음
- scope는 사실 Lexical scope으로 많이 지정됨
Scope of an identifer
실제 identifer의 선언, 타입, identifer를 어디까지 사용될 수 있는지 등을 lexical scope레벨에서 체크하는 것, 코드 상에서 알 수 있음
ex) 지역변수는 function 시작부터 function 끝까지만 사용, local variable은 function 안!
→ 이렇게 이미 알고 있는게 lexical scope
Variable Scope
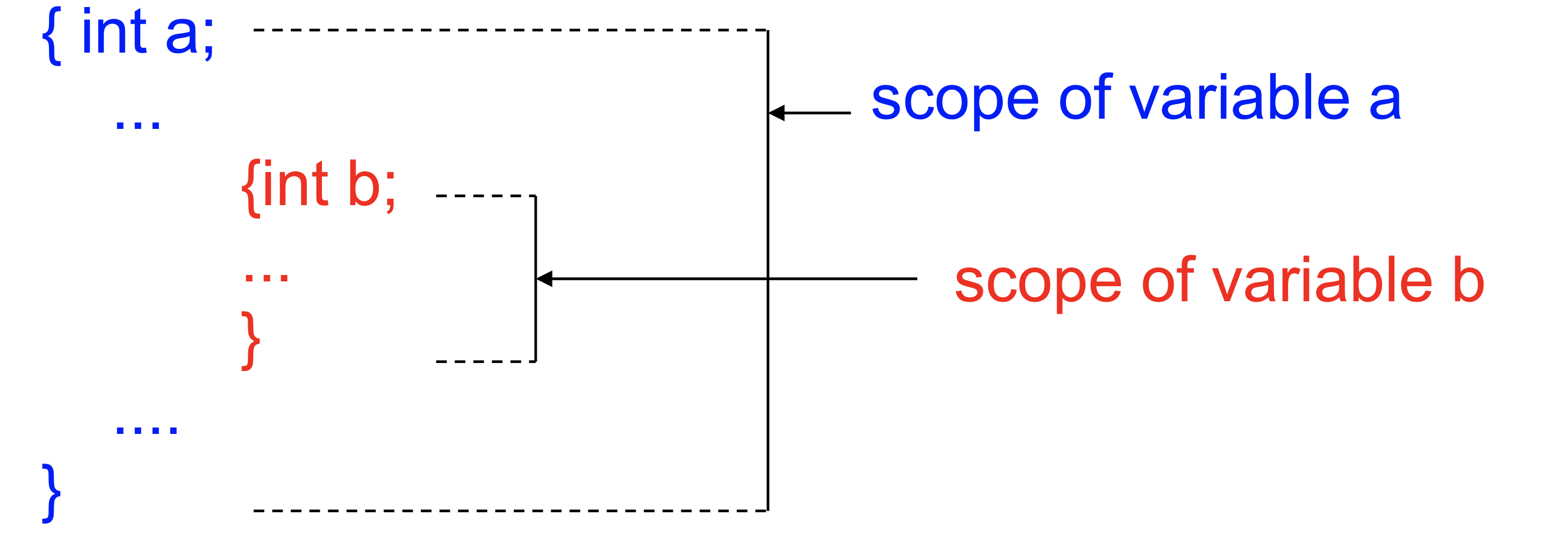
Int b는 중괄호 부분에서 사용 가능, a 범위는 파란색
- Global variable의 범위는 현재 파일
- external variable은 전체 프로그램을 의미
이런 scope은 프로그램마다 다를 수 있음 프로그램에서 지정한 대로 scope rule을 알아야 하고 그에 따라서 scope을 체크하게 될 것
Function Parameter and Label Scope
- formal arguments of function의 scope

매개변수나 local variable의 범위는 function 안
- scope of labels
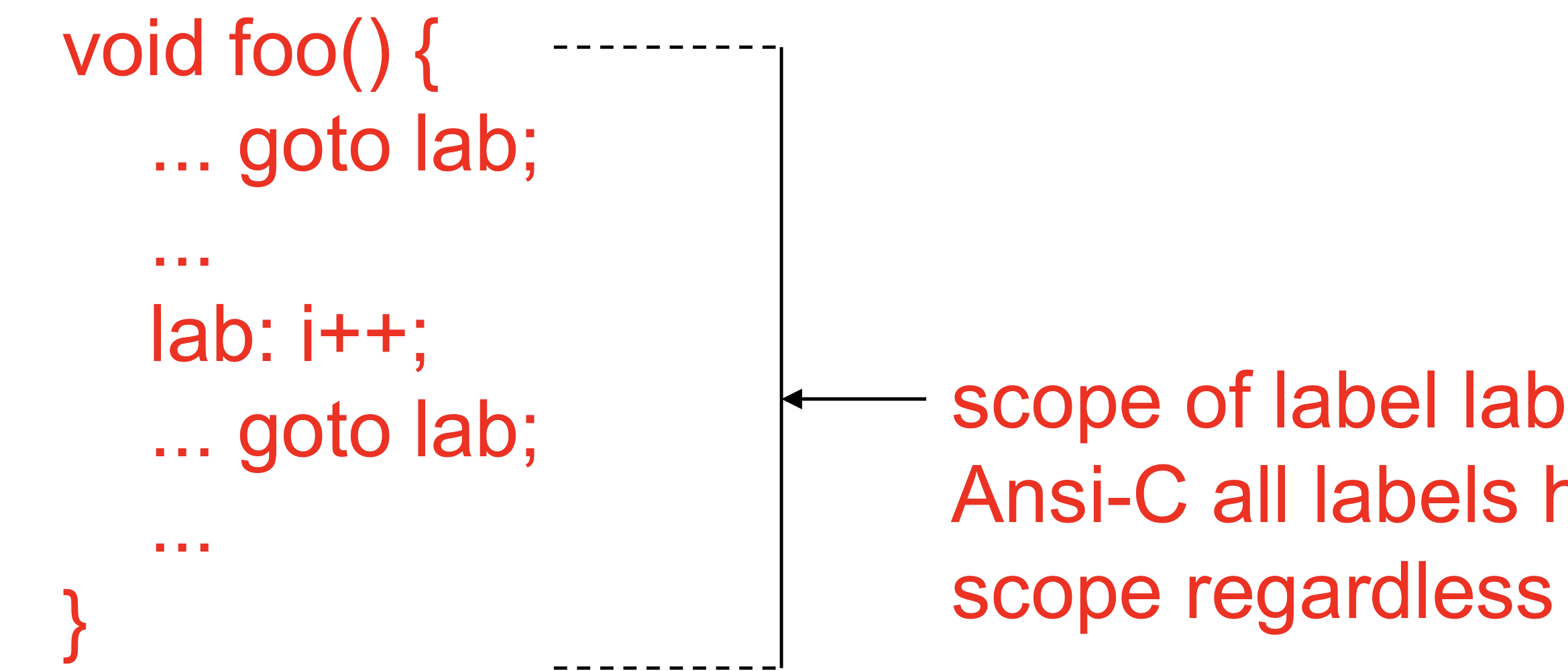
레이블은 어디에 있든 무조건 사용 가능함
-룰은 언어마다 다름
Scope in Class Declaration
- Scope of object fields and methods
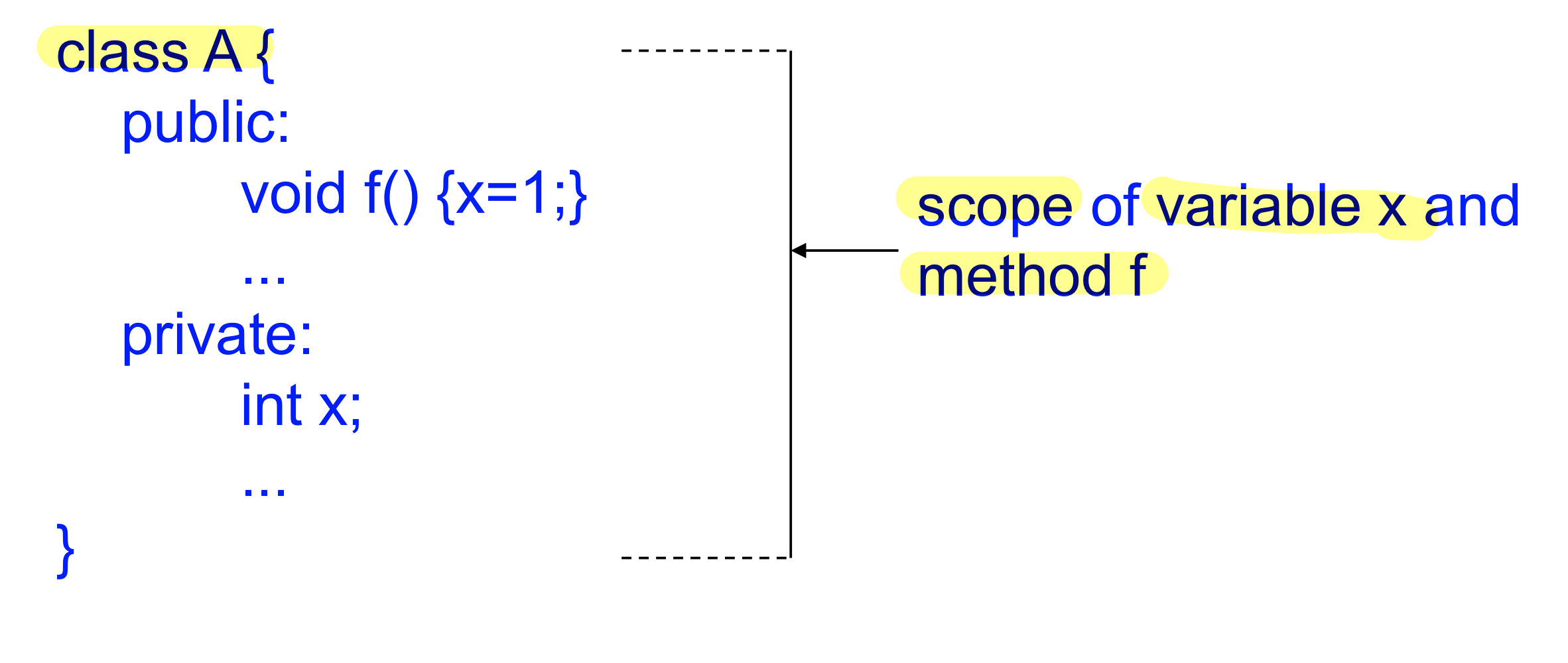
-클래스를 지정하는 모든 variable은 클래스 안에서 지정됨 public은 아무 곳에서나 쓸 수 있고 private은 그 안에서만 사용 가능
-변수나 함수의 범위를 scope 정보로 체크하게 되고 이 범위 정보는 c++ spec에 정해져있어서 semantic tool이 이 정보를 알고 있어야 한다.
Semantic Rules for scopes
rule 1 : scope 안에서는 하나의 identifer를 사용해야 한다
rule 3 : 같은 lexical scope에서는 같은 종류의 동일한 이름을 갖는 identifer를 여러번 declare되면 안된다

Symbol tables
컴파일러는 scope문제를 symbol table로 해결
-
semantic checks refer to properties of identifiers in the program - their scope or type
프로그램에서 identifier에 대한 정보(scope, type 정보)를 저장해야 한다
-
identifer에 대한 information을 저장하기 위한 environment = symbol table
Symbol table이라는 lookup table을 가지고 각 identifier에 대한 정보를 저장하게 됨
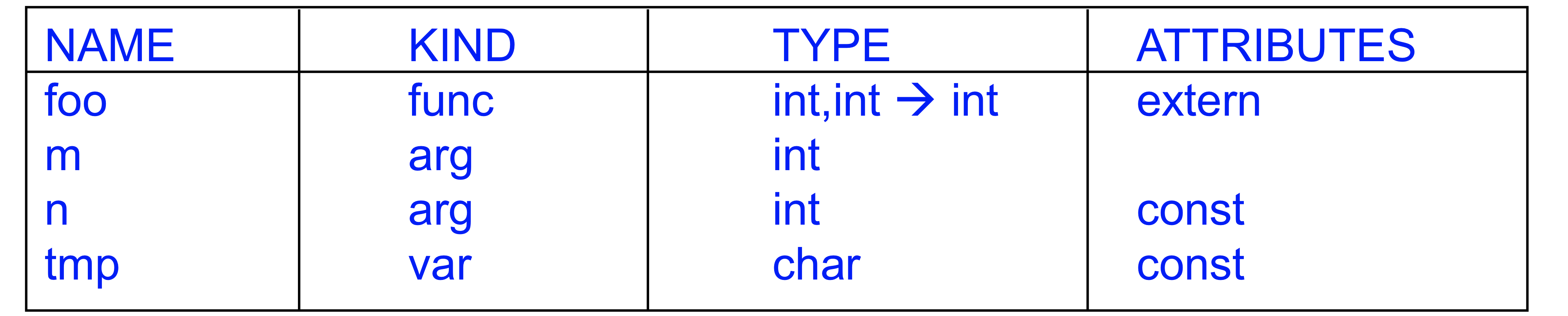
- 각각의 entry는 identifier 이름과 additional 정보를 가짐(어떤 종류인지 무슨 타입인지 상수인지? 등등의 정보를 저장)
- Identifier가 변수일 수도 있고 local variable, function,매개변수 등 일 수도 있음 -> 이거의 타입이 무엇이고 상수이거나 아님 등등의 정보를 저장
-항상 variable과 scope의 semantic 체크는 이 테이블을 사용
-Syntax analysis를 하면서 정보를 테이블에 저장하지 않기 때문에 앞에서 나온 정보를 저장하고 뒤에 있는 statement에서 나온 정보를 체크를 해야 하기 때문에 이 때 사용하는게 symbol table
이 변수가 실제로 스콥에서 사용가능한지, 이 스콥에서 지정이 되어있는지
어떤 변수를 선언하면 symbol table에 추가해주고 나중에 이용될 때 이게 선언되었는지 symbol table lookup으로 확인 가능
How to capture the Scope Information in the symbol table?
- Type check는 할 수 있지만 스콥은 알기 어려움
→ 약간 변경하면 scope information도 추가 가능
idea
- 심볼 테이블을 여러 계층구조로 만들어서 scope에 따라서 계층구조로 만들면 scope information을 체크할 수 있겠다!
- 프로그램에서의 scope에 계층이 있으니까 symbol table도 그 계층에 따라서 여러 개의 Symbol table을 만들어서 그것을 계층별로 연결해서 구조를 만들자! -> 자연스럽게 scope information을 심볼 테이블로 구현할 수 있겠다!
- 각각의 scope마다 하나의 Symbol table을 만들고 이걸 여러개의 계층구조로 만들면 되겠다
- 각각의 심볼 테이블은 해당 lexical scope에서 선언된 심볼들에 대한 정보를 가지고 있고 이걸로 scope 정보를 제대로 심볼 테이블 구조에 저장할 수 있게 된다
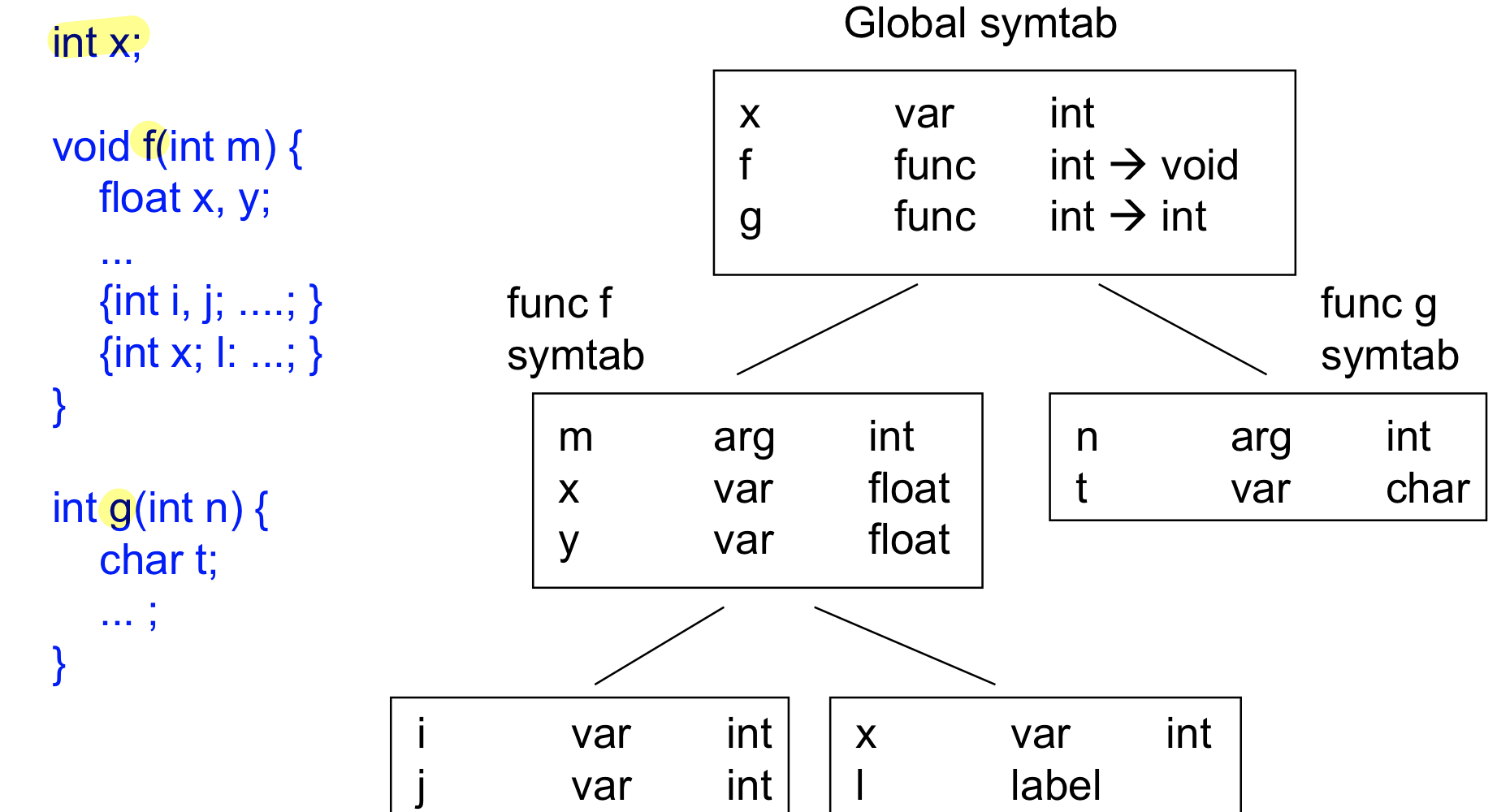
Ex)
왼쪽을 보면 글로벌하게 int x가 있고 Fun 두개 존재
그리고 f 안에 x,y라는 변수가 있고 괄호로 지정된 구문 안에 I,j,x,l이 지정되어있음
이 계층구조에 따라서 만들 수 있다
먼저 global로 지정한 후 f에 대한 symbol table을 만들어주고 f안에 작은 Lexical scope이 있고 그거에 대한 symbol table을 만들어서 내가 있는 scope에서 어떤 variable이 현재 지정되었고 상요될 수 있는지 확인 가능
Identifer with same name
- 심볼 테이블을 이용해서 해당 scope에서의 변수는 사용할 수 있는지 체크 가능 그러나 같은 이름을 가진 여러 identifier가 있다면 어떻게 적용되는지 알아보자
Ex) int I; {int I ; —}여기서 i는 무슨 i??
어떤 i를 사용할 수 있을까?
- 당근 안에 있는 i가 사용될 거 같지만 컴파일러는 코드만 보고 코드의 그때그때 문자열을 보고 알 수 있어야 한다
- Symbol table에서 lookup해서 할 수 있음. 이름이 똑같아서 생기는 문제를 계층구조로 바로 해결 가능 같은 이름으로 스콥이 겹치는 경우 계층구조로 만든 symbol table을 이용해서 문제를 해결하게 된다
→ 어떤 program point에서 active한 identifier를 찾기 위해서 현재 scope부터 찾아보고 여기에 없다면 이 정보를 찾을 때까지 계층구조에서 위로 올라가면서 찾다가 global symbol table까지 올라가도 찾지 못하면 에러이고 찾으면 이 스콥에서 사용할 수 있게 되는 것
Class problem)
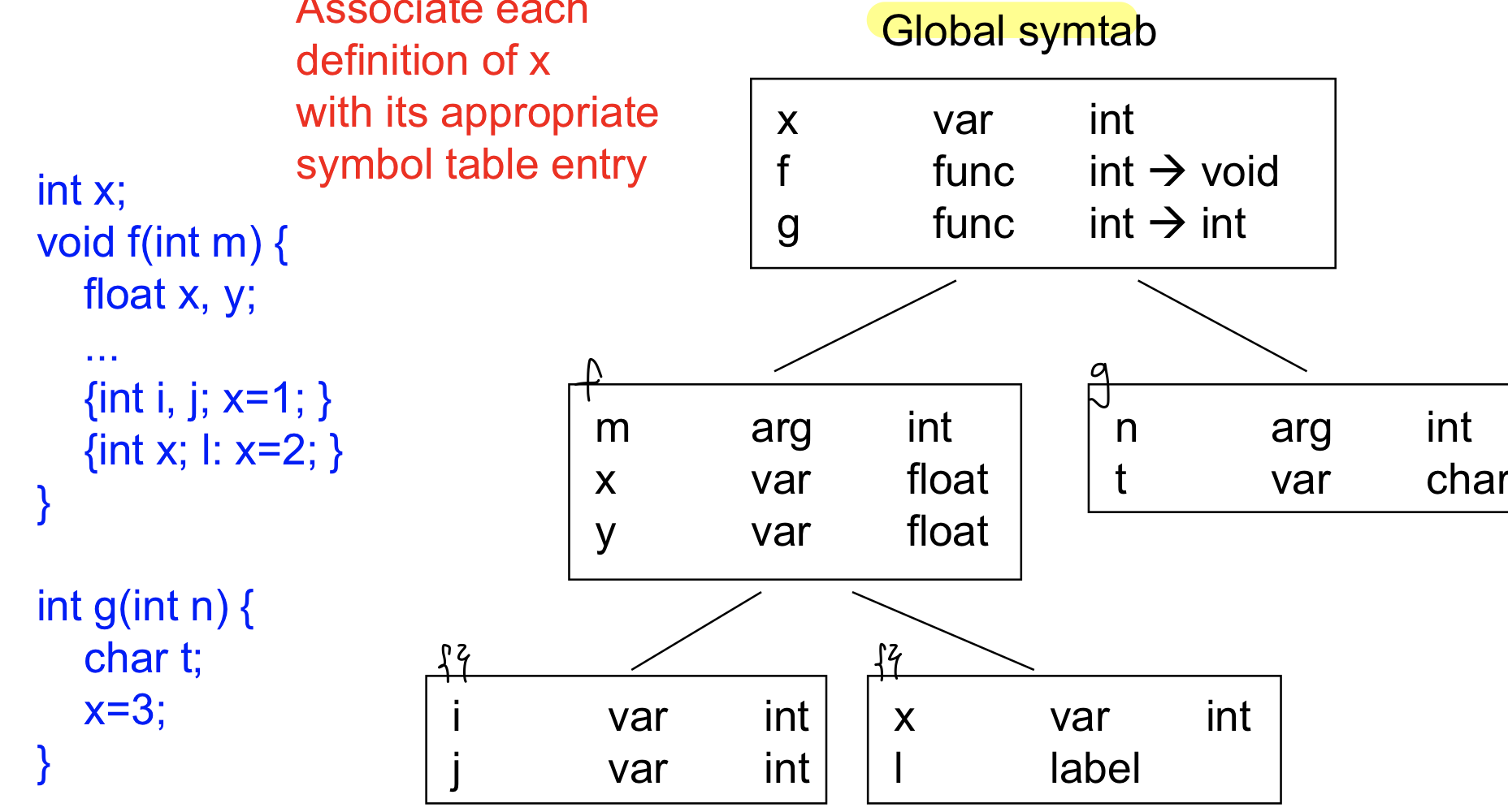
각각의 x가 어디에서 만들어지고 어디서 지정되는지 어디서 사용되는지 알면 좋을 것
이 x는 어디서 지정된게 사용되는지를 계층화된 구조를 통해서 알 수 있다
G에서 사용되는 x는 global symbol table에 있는 x임을 알 수 있다
F 중괄호 안에 있는 x는 하나 올라가서 f에서 보니까 x가 있다!
중간 x는 자신의 scope에서 찾을 수 있다
코드를 보면 바로 알 수 있지만 컴파일러는 코드 보고 알 수 없으니까 계층화된 symbol table lookup으로 찾을 수 있다.
- 각각의 x가 문제없이 찾았을 때를 말한거고 Semantic error을 찾을 수도 있다 : 내 scope부터 가장 상위 scope까지 보면서 있는지 체크했는데 없는 경우 ex) x=2가 아니라 i=2일 경우
Symbol table operations
-
두 개의 operation으로 구성
1) symbol table을 빌드할 때 새로운 identifier를 추가하는 작업 : Insert
2) 컴파일러가 프로그램을 보면서 table information을 체크하여 이 identifer가 이 scope에서 유효한지 볼 수 있다 : Lookup function
-
Symbol table을 빌드하는 것은 lexical analysis에서는 가능하지 않음, 토큰을 추출하는 것인데 얘가 identifier가 되기 때문에 알기 어렵고 얘는 syntax analysis과정에서 빌드한다
- 파싱하면서 semantic action을 통해서 추가하면서 만들어진다, 파싱하면서 하나씩 identifier가 detect될 때마다 저장한다.
- ast가 나온 뒤에 다시 만들 수 있다.
Forward references
ex) i=2; int i;
- 어떤 variable이 이용되는데 뒤에서 선언이 되는 경우인데 이게 가능한 경우도 존재
- 먼저 사용된 후 symbol table이 아직 안만들어져서 문제가 되는 경우가 있지만 프로그램에서 사용이 먼저되지만 사실 있는 경우
⇒ 문제가 되지 않을려면 ast를 만든 후 이걸로 Symbol table을 만들고 나서 scope check를 나중에하는 2 stack방법으로 한다면 될 것

어떤 Identifer를 사용하는데 이걸 먼저 declare되기 전에 사용되는 것 : forward references
이걸 허용하기 위해서 컴파일러가 정보를 테이블을 만들기 전에 symbol table lookup을 해볼 수 있으니 문제가 생길 수 있다 -> 컴파일러가 symbol table을 다 construct한 후 table lookup을 수행하도록 만들면 문제가 되지 않음
Back to type checking
- 타입은 도대체 멀까?
타입 : 어떠한 프로그램에서 value를 identifier에서 사용가능한 value를 말함
-값을 예측할 수 있다 ex) int x → -2^31 ≤ x < 2^31
type error
프로그램 동작 시킬 때 어떤 operation이 잘못되게 동작하거나(잘못된 볌위로 동작), value의 특성이 계속 바뀌는 경우
type safety
type error가 없는 시스템
How to Ensure Type- safety
다양한 구문들이 존재할 때 type safety를 체크하는 방법은 두가지 프로세스로 수행됨
- 어떤 변수나 구문, 수식의 타입을 지정하고 그 타입을 체크하는 방법
- 1) type binding
-
어떤 구조(variable, function)에 대한 타입을 프로그램에서 먼저 지정
- 명시적으로 혹은 암시적으로 지정
type consistency(safety) : correctness with respect to the type bindings, 어떠한 구조에 binding된 타입이 제대로 사용되는지를 체크하는 것
- 2) type checking
-
어떤 프로그램에서 어떠한 구조체가 type binding에 따라서 올바르게 사용되고 있는지를 체크하는 것
Type checking rule에 의해서 체크, 굉장히 다양한 편, 어떤 변수가 int라도 fp라면 변환해서 저장한다거나 아니면 strict하게 에러로 말하거나 수준이 다르게 만들어질 수 있다
Type Checking
- semantic checks to enforce the type safety of the program
Semantic check라고 하며 type safety를 체크하는 과정을 말함
ex)
- 어떤 operator가 있을 때에는 operand가 올바르게 들어와야 한다
- Func이 있을 때에는 Argument가 같은 숫자의 올바른 형태의 타입으로 들어와야 한다
- Return타입 맞아야 한다
- Assign시 같거나 호환가능한 게 지정되어야 한다
Compatible : 두개가 호환가능하다. 호환가능한 정도는 언어마다 다름, int i= 1.0할떄 이걸 compatible하다고 생각하기도 하고 다른 언어에서는 에러라고 지정해 줄 수 있다
- Left hand-side의 타입과 호환가능해야 한다라는 룰이 필요, 호환정도는 언어마다 다르다
4 Concepts related to Types/ Languages
언어마다 다름
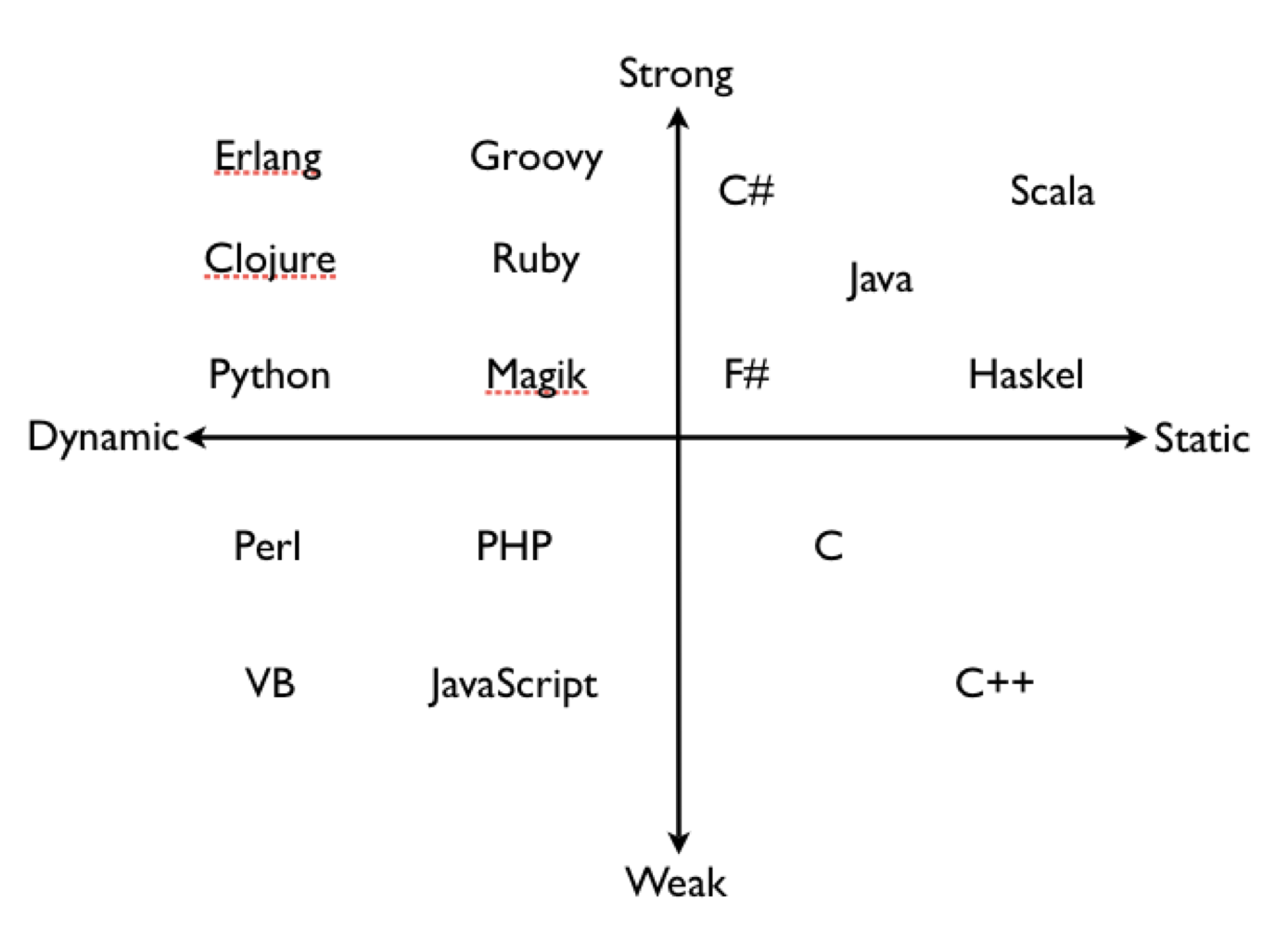
-
Static vs Dynamic checking
type checking을 언제?
-
Static vs Dynamic typing
type binding을 언제? 언제 타입을 define하느냐?
- Strong vs weak typing
type error를 얼마나 정밀하게 체크?
Int에는 int : strong
Int에 float 가능 : weak
- Sound type systems
모든 타입 에러를 static하게 잡을 수 있는 시스템을 의미
- ex) c는 static checking,typing하는 언어
-
다 지정되어있고 데이터 타입을 다 지정하며 weak type을 사용함, compatibility가 높은 편, 유도리있게 에러를 리포트하지 않음, 모든 것을 컴파일 타임에 지정
ex) 요즘 나오는 언어들은 dynamic하게 지정 < - script language, assign하는 값에 따라서 타입이 그때마다 다르게 지정되는 언어도 존재
오른쪽에 있는 그래프를 잘 보고 이해하는 게 좋을 것
C#,java, pyton 등등이 왜 저기 있는지 알면 좋을 것
1) static vs dynamic checking
언제 type checking을 하는가?
C는 전자인데 컴파일 타임에 Type checking을 하고 프로그램이 어렵지만 runtime에 type checking overhead가 없어서 속도가 빠름
하지만 후자는 compile 시간은 작고 프로그램 짜기도 쉬운 편, 하지만 런타임에 매번 타입 체킹을 해야 하니까 성능저하가 생길 수 있음
2) static dynamic typing
Type define을 언제하는가?
컴파일에 한다고 생각하지만 dynamic하게도 가능, 어떤 변수에 타입을 지정하지 않아도 assign되는 거에 자동으로 타입이 정해지는 언어도 존재, 런타임에 지정되는 언어도 요즘 존재함
3)strong vs weak typing
Type checking을 얼마나 엄격하게 하는가?
Strong은 프로그램 짜기 어렵지만 후자는타입 에러를 가져도 원인정도로 생각하고 호환되게 컴파일되게 해준다
Soundness
- sound type systems
어떤 프로그램이 statically 컴파일 타임에 타입문제가 없음을 보장해주는 시스템을 말함
Strong type을 의미하며 쉽지 않음. Static analysis로 type safety하다는 것을 보장하는 것은 어렵기에 어려운 편
파이썬 루비, rust 등등 이런 저런 언어가 어떤 typing rule을 쓰는지 알아보자
왜 static checking을 사용??
Static checking을 수용한다면 실제로 런타임에 체크하면 느리게 되고 c는 다 static하게 수행하는 편, 그리고 static한다는 것은 프로그램 동작 시 문제가 없다고 보장하기에 안전한 편 하지만 soundness system을 만드는게 어렵기에 수동적인 정책을 취할 수 밖에 없음