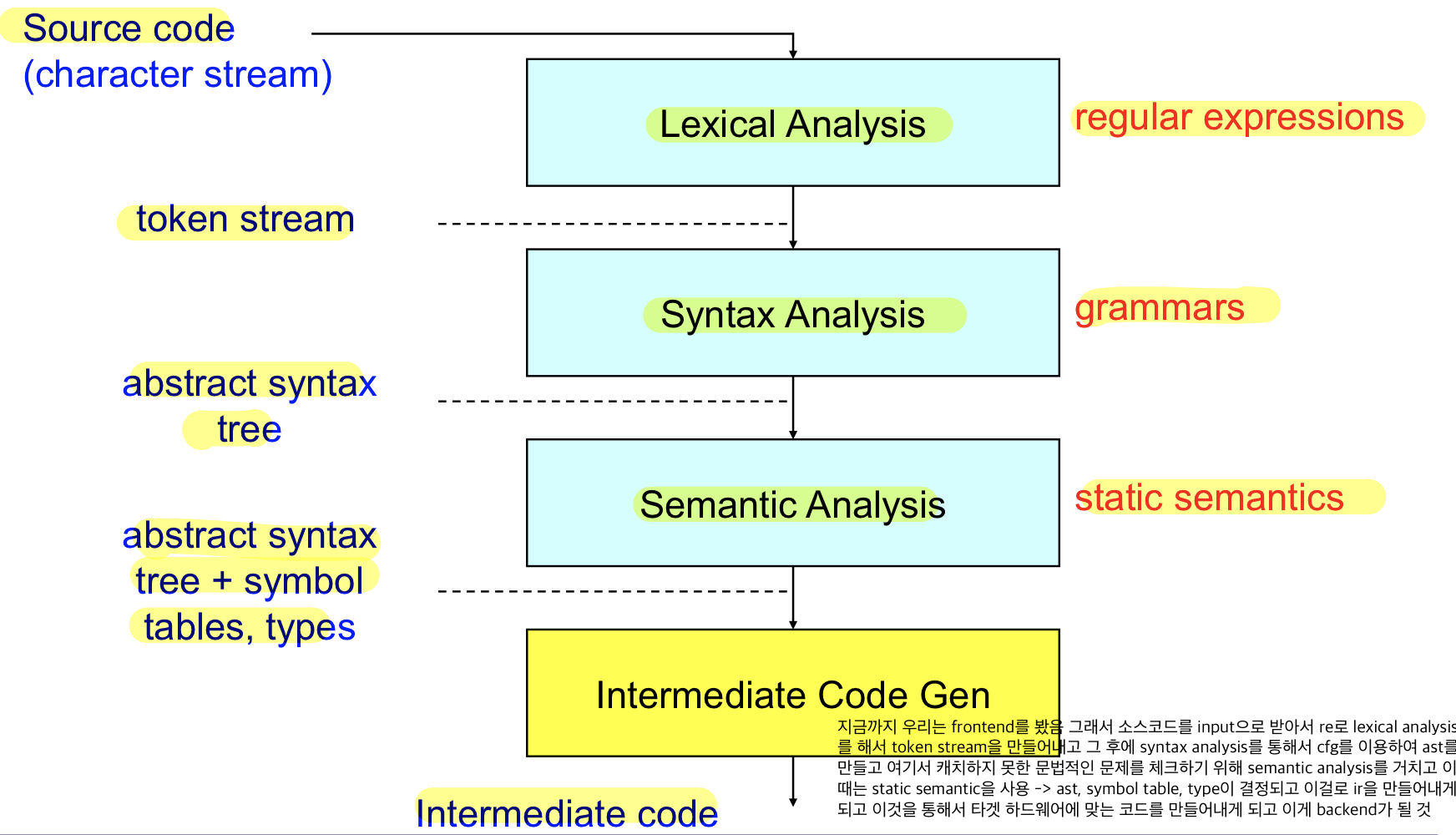
지금까지 우리는 frontend를 봤음 그래서 소스코드를 input으로 받아서 re로 lexical analysis를 해서 token stream을 만들어내고 그 후에 syntax analysis를 통해서 cfg를 이용하여 ast를 만들고 여기서 캐치하지 못한 문법적인 문제를 체크하기 위해 semantic analysis를 거치고 이 때는 static semantic을 사용 -> ast, symbol table, type이 결정되고 이걸로 ir을 만들어내게 되고 이것을 통해서 타겟 하드웨어에 맞는 코드를 만들어내게 되고 이게 backend가 될 것
→ 프로그램에서 프록래밍 언어의 featrue을 걷어내고 프로그램의 알고리즘이 machineindependent assembly(타겟 하드웨어와 상관없는 컴파일러가 알고있는 어셈블리 규칙에 따라서 프로그램이 저장됨)
Intermediate representation(IR)
- the compilers internal representation
-
language- independent and machine independent
타겟 언어의 independent하고 실제 바이너리를 만들 떄에도 타겟 하드웨어에도 independent함
1) 언어적인 feature이 존재하지 않고 프로그램의 알고리즘만을 가지고 있음
2) 레지스터나 리소스(메모리)의 개수가 무한개임인 것
-
컴파일러가 프론트엔드에서 마지막에 결과에 나오는 ast를 IR로 만들기 위해 코드의 스펙을 나타낸 것
- 컴파일러가 가지고 있는 어셈블리의 스펙(자신만의 instruction으로 저장)
- 컴파일러 내부에서 사용하는 intermediate code를 위한 스펙
- 컴파일러 고유의 중간코드를 저장하는 규약
- HIR은 hhl와 비슷하게 저장하는 것이고 LIR은 어셈블리 형태로 가지고 있으며 요즘 컴파일러는 주로 LIR을 사용
-
IR는 ast를 컴파일러가 저장 시 어셈블리 형태로 혹은 중간 코드형태로 저장 시 코드의 규약으로 지정되어 있음, 컴파일러는 AST를 IR 형태로 input program을 저장하고 저장된 코드로 최적화 후 타겟 하드웨어에 맞도록 코드를 생성한다
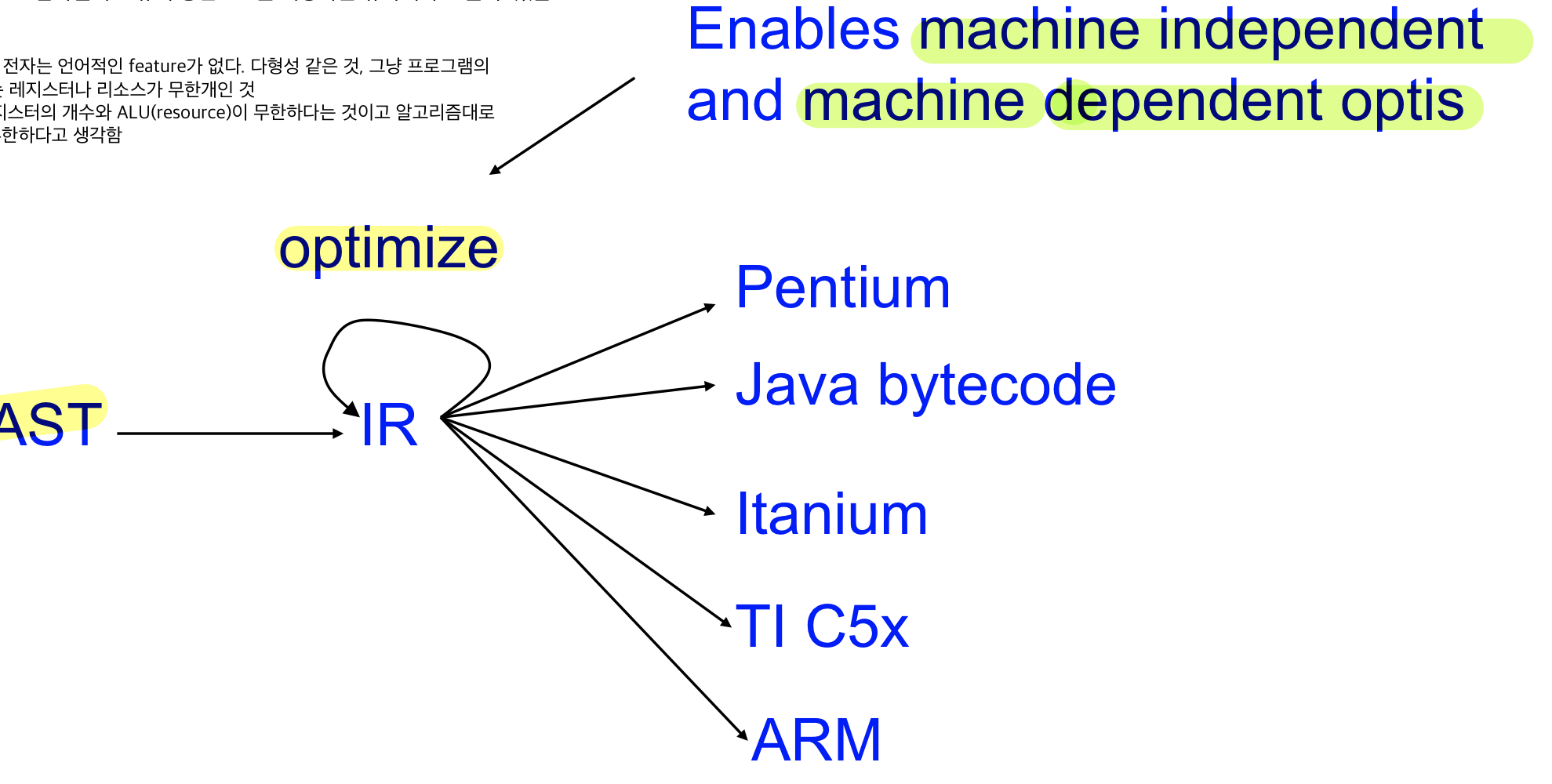
code generation 시 IR에서 ARM 으로 바꾼다는 거은 instruction set을 맞춰준다는 의미, opcode mapping, register mappping을 해준다
cf. machine independent한 상황이라도 dependency가 존재하기 때문에 모든 프로그램이 한 사이클 안에 수행되지는 못한다.
What makes a good IR?
1) hhl에 중요한 구성요소들을 저장할 수 있어야 한다(captures hhl constructs)
- AST로부터의 변환이 쉬워야 한다
- high level optimization을 지원해야 한다
-
loop같은 구조를 쉽게 저장해서 최적화를 할 수 있는 것
ex) Hhl에서는 loop를 키워드로 가지하기가 쉬운데 low level에서는 backedge를 찾아야 하기 때문에 hl optimization 수행하기 low level에서는 어려우므로 high level구조를 가지는 것이 좋다
cf. loop detection을 통해서 loop를 빠르게 돌려야 성능향상에 도움이 됨
2) low level machine featrure을 가지는 것도 좋다(captures low level machine features)
- assembly로의 변환이 쉬워야 한다
- machine dependent optimization을 지원해야 한다
- 어셈블리와 비슷하게 add, sub, mul 등의 어셈블리 레벨의 ir을 만든다면 어셈블리로 변환하기 쉽고 각각의 타겟에 dependent optimization하기 쉽다
→ 하지만 대부분은 lowl level ir을 가지는 편
3)IR을 만들기 위해서는 instruction의 개수를 조금만 가지는 것이 좋다.
- 간단한 구조의 IR을 만들어야 최적화하기도 쉬움
-
retarget(다양한 타겟 하드웨어에 맞는 코드를 만들기)도 쉬운 편
Ex) 하드웨어마다 add만 가지고도 variation이 많기 때문에 컴파일러 안에 있는 machine language(프로그램을 저장하기 위한 IR은 machine independent, language independent해야 하기에 아주 간결한 구조로 만드는 것이 좋다. 최적화도 쉽고 타겟 하드웨어에 맞는 코드르 만들기도 쉽다)
→ High level feature을 알기 위해 HIR로 최적화한 후 LIR로 바꿔서 최적화하는 것이 좋음
Multiple IRs
대부분의 컴파일러는 두개의 IR을 가지고 있다
- High-level IR(HIR) : language independent하지만 language에 가까움
- Low level IR(LIR) : machine independent하지만 machine에 가까움
- 중요한 건 both naguage and machine independent!
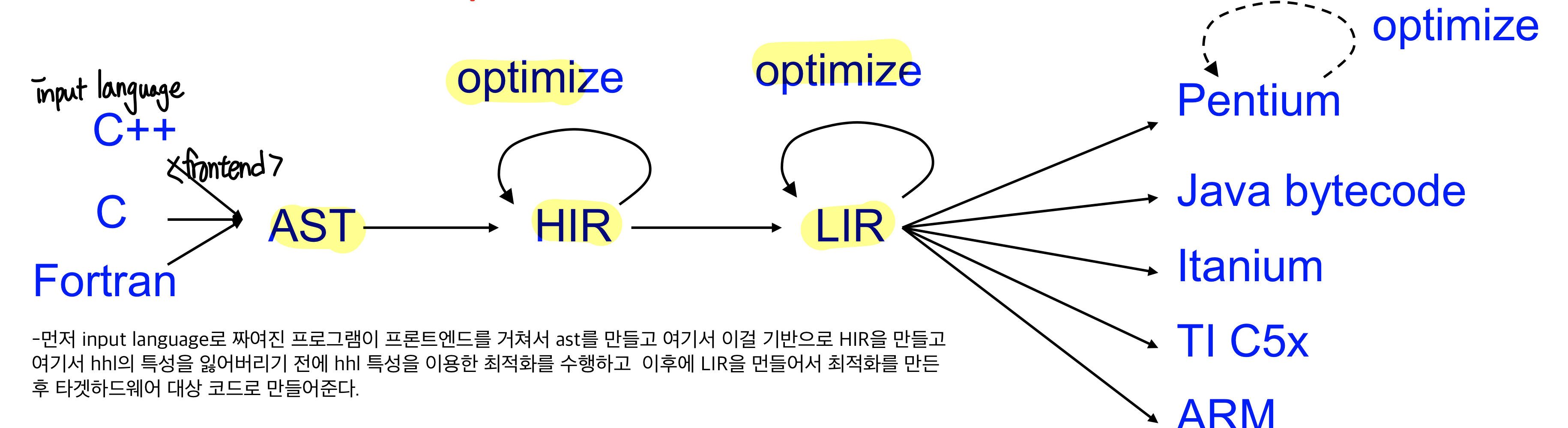
- 먼저 input language로 짜여진 프로그램이 프론트엔드를 거쳐서 ast를 만들고 여기서 이걸 기반으로 HIR을 만들고 여기서 hhl의 특성을 잃어버리기 전에 hhl 특성을 이용한 최적화를 수행하고 이후에 LIR을 먼들어서 최적화를 만든 후 타겟하드웨어 대상 코드로 만들어준다.
즉 HIR, LIR이 둘 다 존재함을 알 수 있다
High-level IR
-
HIR은 본질적으로 AST임
왜냐면 프론트엔드를 거쳐서 토큰 스트림을 프로그램의 구조에 맞게 트리 구조로 구성하고 이걸 저장한 자료구조인 ast로 저장된 프로그램을 HIR스타일로 Intermediate code를 저장하는 것
- high level language construct이 유지
- structred control flow : if, whild, for, switch
- variables, expressions, statements, functions
- 기본적으로 input language에서 표현할 수 있는 특성들을 모두 표현할 수 있어야 한다. 구조들을 모두 유지해야 한다(if, while, 등등의 키워드가 토큰으로 저장-> 프로그램이 어떻게 동작할 때 execution flow가 어떻게 바뀌는지 알 수 있다. )
- source lanage의 특성을 기반으로 하는 high level optimization을 허용
- ex) function inlining, memory dependence analysis, loop transformations
function inlining : 작은 function을 straight forward한 코드를 만들어서 function call을 하지 않고 어셈블리를 넣는 형태, inline int add(a,b) = {c=a+b;} 이렇게 적으면 현재 context를 저장과 call, return의 오버헤드를 지울 수 있지만 큰 코드의 경우 어셈블리가 너무 커지고 레지스터를 더 많이 사용하기 떄문에 코드가 작고 간단할 때 사용 가능
→ function inlining을 LIR에서 수행하려면 function의 범위를 알아야 한다. return까지 찾으면 되지만 function call, return 시 콜하기 전 작업 등이 있는데 어셈블리만 보고는 찾기가 힘듦
cf.어셈블리 형태에서 이러한 최적화를 수행하기 어려운 이유는 어셈블리는 루프를 찾기 어려움. 얘는 전부 add, mov 등등으로 구성하기에 루프를 찾기 어려워서 이렇나 최적화를 수행하기 어렵지만 HIR는 키워드를 통해서 찾을 수 있고 어떤 부분인지 확인이 가능하므로 최적화를 수행하기 쉽다
Low level IR
넓은 scope을 보기는 어렵지만 타겟 머신의 Instruction과 일대일 대응이 가능하기 때문에 어셈블리 레벨에서 최적화 시 instruciton 수를 줄이면 속도가 빨라질 확률이 높다
- Abstract machine을 구동시키기 위한 instruction들의 모임(RISC)
- 추상화된 머신 : 컴파일러에서는 computation unit과 register가 무한개인 것을 의미
- 그러한 머신에서 이 프로그램을 구동하기 위한 instruction의 모임
- has low level constructs
- unstructured jumps, registers, memory locations
- types of instructions
- arithmetic/logic(a=b OP c), unary operations, data movement(move,load,store), function call/return, branches
- instruction은 굉장히 작은 job을 수행. 이러한 명령어는 어셈블리 언어와 대동소이한 편
Alternatives for LIR
LIR을 표현하는 많은 종류가 존재
1) three address code(quadruples)
- a = b OP c
- Operand가 3개 하나의 opcode로 구성
- 두 개의 input을 받아서 계산한 후 그 결과를 하나의 타겟 operand에 저장
- compiler 분석을 쉽게하고 optimization을 더 쉽게 한다
- 최적화하기 쉬운 편, 어셈블리 코드와 비슷
2) 트리 형태(tree representation)
- CISC에서 가장 유명, machine code만들기 쉬움
3) 스택 형태(stack machine)
- ast로부터 생성이 쉬운편, 자바 바이트코드같은 형태
→ 우리는 1번만 다룰 예정
Three address code(quadruples)
- a = b OP c
-
instruction은 최대 3개의 address 와 operand를 가진다
Operand 3개와 opcode 1개로 구성된 코드를 의미
ex)
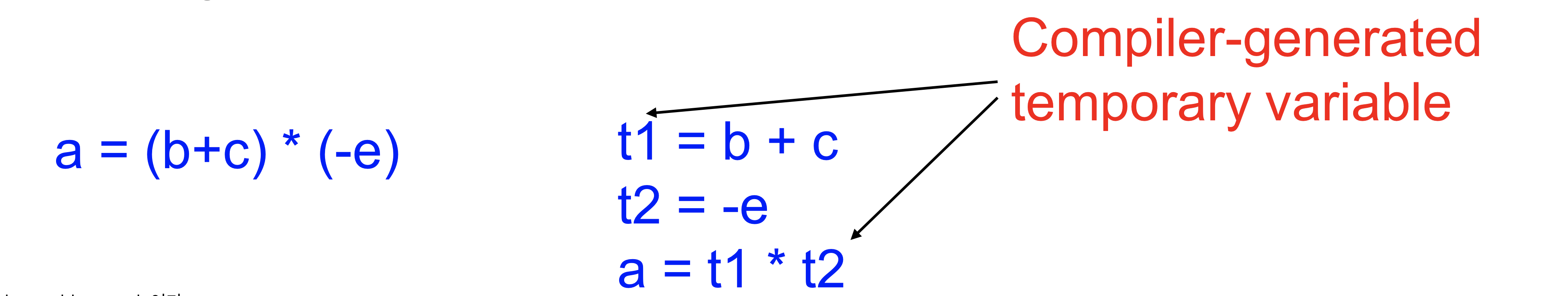
Operand가 1개밖에 못들어가기 떄문에 insturciton이 많아진다.
중간 값을 저장하는 변수가 필요하기 떄문에 변수도 늘어남
IR instructions

1) Assignment instructions
작업 후 타겟 operand에 값을 저장
Binary operation은 input operan가 두개인 것
Unary operation은 input operand가 하나인 것
Copy는 input operand값을 output operand에 저장
Load : input operand가 가리키는 주소에 있는 데이터를 타겟에 넣는 것
Store : input operand의 값을 어떠한 다른 operand가 가리키는 메모리 주소에 저장
2)flow of control
Flow를 바꾸는 것
바로 다음 instruction을 수행하는 것이 아니라 다른 곳에 있는 명령어를 수행
Execution flow를 바꿔주는 명령어
Label와 점프, cjump(충족되었을 때에만 점프)
3)Function call
이러한 instruciton은 많이 쓰이는 하드웨어의 set과 동일하지만 abstract machine을 타겟으로 정의되고 훨씬 간결하다는 점이 존재
IR operands
- the operands in3 -address code can be :
- program varaibles
- constants or literals
- temporary varaibles
- temporary variable = new locations
- intermediate value를 저장
IR은 항상 three operand를 가지고 있으므로 프로그램의 변수이거나 상수나 오리지널 코드가 복잡해서 three address. Code로 바꾸는 도중 생기는 중간값이 존재
Translating High IR to Low IR(시험에 나올 가능성 o)
컴파일러는 HIR와 low IR을 가지는데 나중에 백엔드 프로세스 전에 Low IR을 만들어야 하므로 ast -> HIGH IR -> 최적화 -> LOW IR 과정이 존재
- may have nested language constructs(while, nested, within, if statement)
- need an algorithic way to translate
- → solution
-
start from the high IR representation → define translation for each node in high IR → recursively translate nodes
High IR에서 시작해서 각각의 노드들을 어떻게 변화시키는가에 대한 룰을 만들고 그 룰을 translate하는 것을 반복적으로 수행해서 low level IR을 만들게 될 것
Notation
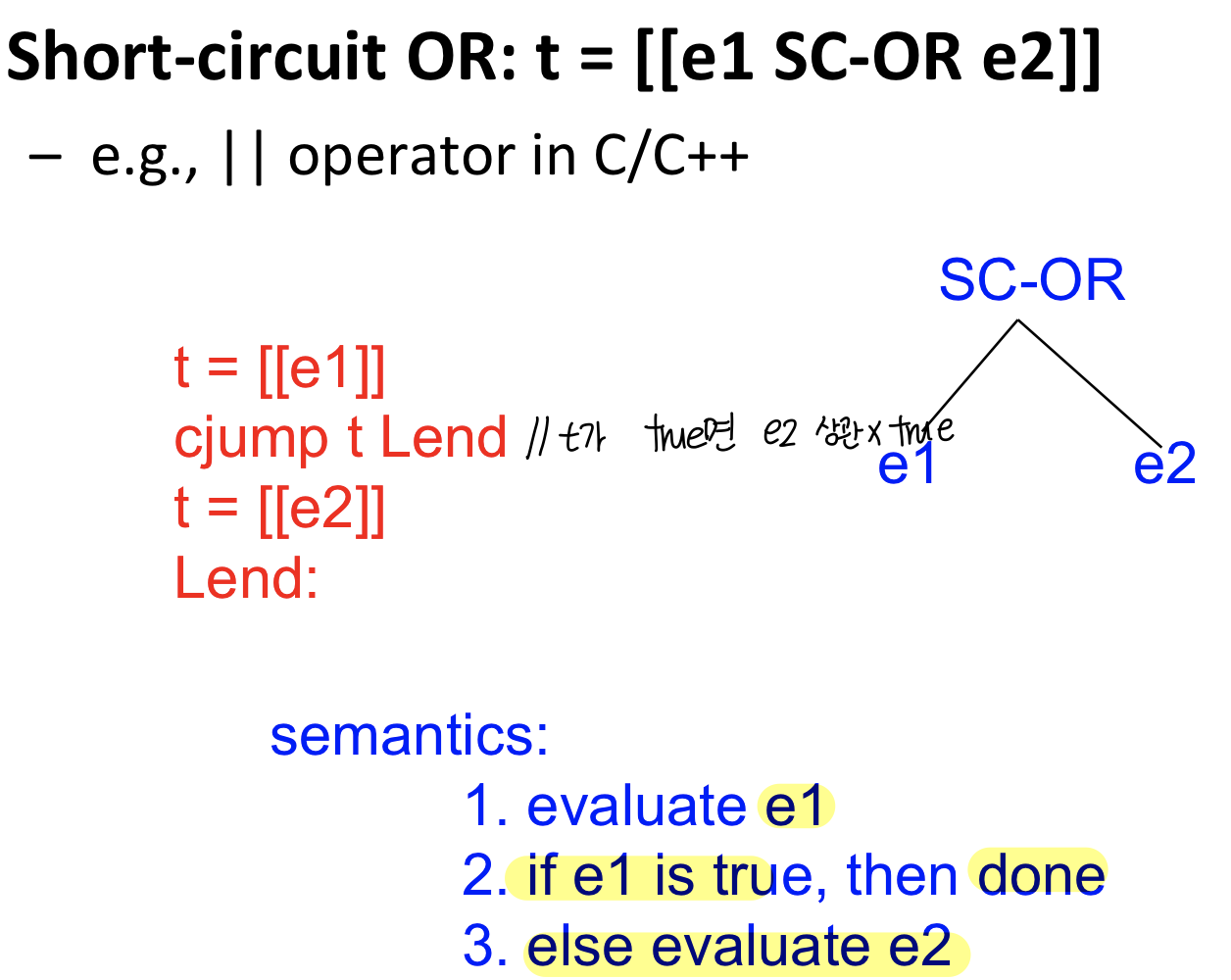
- [[e]] = low IR representation of high IR construct e(expression or statement expression, value를 표현)
- low IR instruction의 sequence
- t=[[e]]
- 어떠한 low IR들을 수행해서 하나의 값으로 만들고 그 값을 t에 저장
ex) t=[[v]] : copy instruction, v는 variable
t = v (v는 변수이기에 h IR = low IR이므로 t=v라고 적어도 된다)
Translating Expressions



array access과정 아는 게 좋음
cf. union vs struct
union - element들이 같은 주소를 공유, 즉 하나만 사용가능한 것, 따라서 선언된 변수들의 주소와의 offset은 동일하다


Q. if then else문에서 t2를 사용하지 않는다면 jump의 수가 하나 더 줄어들 수 있지만 그대로 사용하는 이유?
A. 디버깅 시 편하게 하기 위함, 어셈브리 코드와 hhl을 라인맵핑해야 하는데 최대한 코드 순서를 유지하는 것이 좋다. t2는 나중에 지워질 수 있다

Q. while do translation과 do while translation 중 어느 것이 더 효율적인가?
A. 오른쪽 코드가 더 효율적,오른쪽이 instruciton이 많지만 루프에 해당하는 코드의 수(dynamic instruction count)가 훨씬 적기 때문에 더 효율적
cf. static count와 dynamic count
dynamic count : 구동시킬 때 실제로 얼마나 돌아가는가? 다이나믹이 좀 더 중요
static count : 어셈블리 코드 자체가 작은 게 좋은 경우, 메모리가 작아서 프로그램이 커지면 안되는 경우에 중요

switch문을 구현한 부분은 잘돌아가지만 순차적으로 컨디션을 체크하기 떄문에 최악의 경우 끝까지 다 봐야 한다는 문제가 있다 → Look up table을 만들어서 레이블을 찾아가서 찾는 방법도 존재
Q. 스위치문을 만들면 무조건 느릴까?
A. lookup table을 만든다는 것은 똑같은 속도로 만들 수 있지만 메모리에서 찾아고 읽어야 하기에 case1이 걸릴 확률이 매우 크다면 원래의 방식이 낫다.
속도를 보장하지 못하는 경우가 최악이기 때문에 어느 정도 똑같은 속도를 가지는 lookup table이 더 좋을 수도 있다. 특정 케이스에 걸릴 확률이 높다면 제일 위에 두는 것이 좋음

Nested Expressions
지금까지는 많은 구문에 대해서 hir- > low IR로 바꾸는 방법에 대해서 알아봤음
되게 큰 프로그램을 그럼 low IR로 어떻게 바꿀까??
- translation recurses on the expression structure

큰 부분을 조그만한 구문으로 나누고 그 중에서 high IR에서 low IR로 바꿀 수 있는 부분이되면 변경할 수 있게 되므로 최종적으로 low level IR로 만들어진 intermediate code를 만들 수 있음
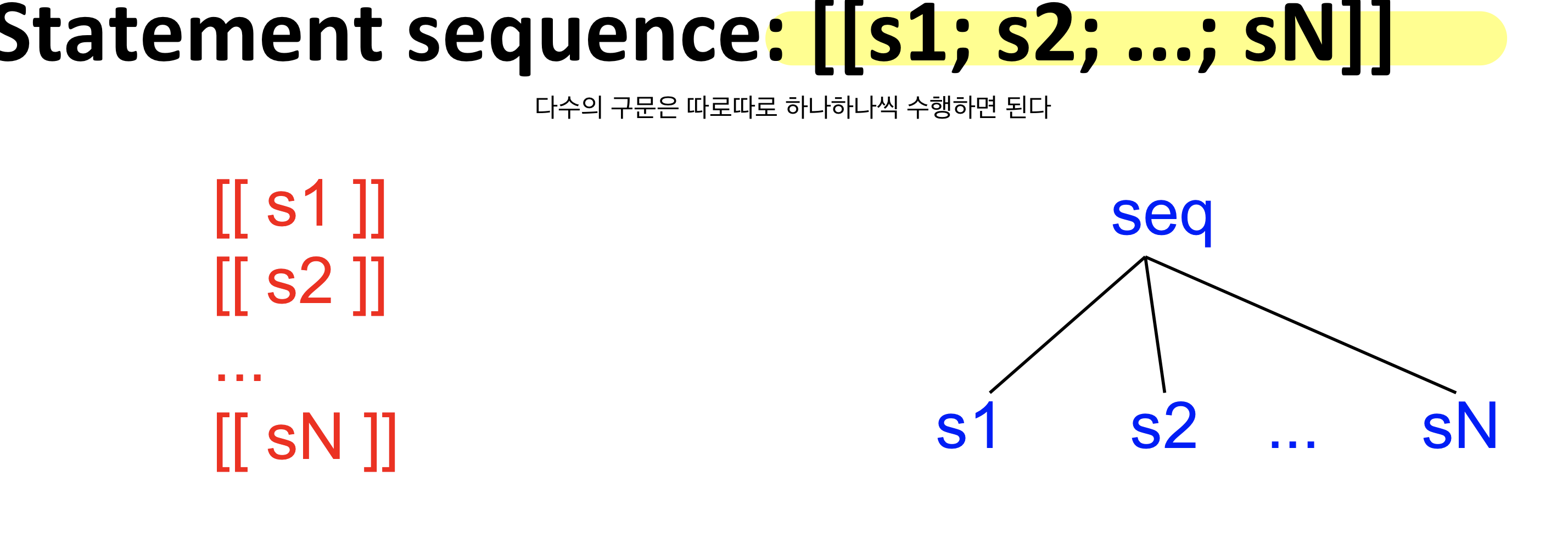
- statement(구문)에서도 동일하게 적용 가능
