스토리지는 가장 느리며 빠르게 구동시키기 위해서는 자주 사용하는 변수는 레지스터에 저장한다. 자주 사용하는 것을 분석하는 것을 locality를 본다고 한다
cf. 캐시를 언급하지 않는 것은 직접적으로 접근할 수 없고 주소를 특정할 수 없으며 데이터의 주소들이 디램에 있기 떄문
2 Class of storage in processor
Variable을 어떻게 저장하는지 어떤 곳에 어떻게 저장하는지에 대해서 알아보자
- 컴퓨터 시스템 프로세서에서는 두가지 소토리지가 존재
1) 레지스터 : cpu에 존재
- fast access, but only a few of them
- address space는 programmer에게 보이지 않는다
-
pointer access를 지원하지 않음
레지스터는 작은 메모리이고 cpu옆에 있기에 빠르게 접속할 수 있지만 용량이 작음, 그리고 레지스터의 address는 사실 프로그래머는 알 수 없다. 그 의미는 레지스터는 포인터로 접속할 수 없다
2) memory : dram이 기본
- slow access, but large
- supports pointers
-
storage class for each variable은 HIR에서 LIR로 맵핑 시 대부분 결정
하지만 메모리는 logical address로 접속이 가능, 하지만 스토리지 보다는 작지만 레지스터보다는 메모리는 크고 느린 디바이스임. 어드레스별로 접속할 수 있기 때문에 포인터를 support한다
데이터들이 디램에 있다고 생각하고 디램과 레지스터를 이용해서 variale을 assign하게 된다
→ 메모리와 레지스터에 적절하게 variable을 아니면 constructure들을 배치할 것
(자주 쓰고 작은 데이터는 레지스터에 자주 쓰지 않는 거는 메모리에 저장)
Storage class slection
프로그램에 다양한 구조체, 변수들은 어떻게 저장할 것인가?
1) standard (simple) approach
- globals, statics - memory
- locals
- composite type(structs, array…) - memory
- scalars
- access via & operator - memory
- rest - virtual register
- 기본적으로 virtual register에 저장하고 virtual이라는 것은 레지스터의 개수가 무한개라고 생각하는 것을 의미
-
모든 변수를 레지스터에 저장하면 하드웨어에 있는 레지스터보다 훨씬 많은 레지스터가 필요하게 된다. 나중에 ir 레벨에서는 virtual register로 우리가 원하는 변수의 개수만큼 레지스터에 저장하고 나중에 실제로 타겟 하드웨어에 맞는 코드를 만들 때 새로 레지스터 맵핑을 한다. 사용하는 변수의 수가 하드웨어 레지스터 수보다 크면 메모리에 저장하는 경우가 있는데 그 경우는 spilled to memory이라고 한다
: 이러한 과정을 virtual to physical register mapping(code generation에서 register allocation)이라고 한다.
cf. Virtual register는 abstract machine에서 레지스터 수가 무한개임을 가정하는 것이고 Physical register는 실제 타겟 하드웨어에 존재하는 레지스터를 의미함
local variable은 자주쓰고 바로 읽어야하기 때문에 메모리에 있으면 가져오는데 시간이 걸리므로 레지스터 파일에 있는게 좋음
- 스탠다드 접근이 기본이며 심플하기에 이걸 기본으로 생각할 것
2) all memory approach
- 모든 variable를 메모리에 집어넣고 몇개를 레지스터로 맵핑
→ 이 과목에서는 스탠다드 접근방법을 기본으로 할 것
cf. register spill
r1=r2+r3 R4=r5+r6 R7=r8+r9← 지금의 실행시점 R10=r1+r4 R7=r7+1 Q. r10 실행하기 전까지 우리는 r1,r4,r7값이 레지스터에 있어야 한다. 이때 만약 레지스터가 두개밖에 없는 프로세서에 이 코드를 맵핑하려면?? 바로 쓰지 않을 값을 메모리에 저장, 여기 시점에서 store r4를 해줘야 한다. 왜냐면 r7을 저장할 location을 확보해야 하니까! 그다음에 store r7을 하고 load r4를 해야하므로 속도가 엄청 느려지므로 register allocation이 매우 중요 : register spill, 레지스터의 값을 보존할 수 없어서 메모리에 보내는 경우 스필이 있다면 load, store이 생겨서 느려지게 된다.
→ 레지스터를 동시에 많이 사용하지 않도록 줄이는 것이 매우 중요, 가장 중요한 저장소가 레지스터이기 때문
4 Distinct Region of Memory
메모리에 프로그램을 로딩할 때, 프로그램을 올릴 때 사용되는 4가지 영역
1)code space
- 프로그램 instruction을 저장하는 공간, read only.
이유는 프로그램을 디램에 올리고 프로그램을 구동시키는 중간에 포인터가 잘못되어 code space에 있는 데이터를 변경하게 되면 프로그램이 제대로 돌지 않을 수 있으므로 코드 스페이스는 read only로 둔다. 고칠 시 report
2) static region(or Global)
-
프로그램이 디램에 로딩된 후에 프로그램이 끝날 때까지 그 값을 가지고 있는 variable을 저장한다
Static, global variable이 해당
3) stack
- varaible that is only as long as the block within which they are defined
-
스택이라는 메모리 공간이 있는데 얘는 프로그램 실행 시 local variable이 저장됨.
Local variable – 함수 안에서 선언되고 함수가 끝나면 사라지는 변수를 의미
- 스택은 런타임마다 function call에 따라서 크기가 달라질 수 있으므로 dynamic함
4)heap
- malloc,new와 같은 system storage allocator를 통해서 정의되는 변수
- 프로그램에서 구동 시 어떠한 메모리 영역을 힙영역으로 두고 dynamic a location으로 할당되는 메모리 공간을 갖게 되는 부분을 의미
- 할당하고 첫번째 주소를 리턴하고 포인터 변수를 이용해서 접속함. 동적할당으로 할당되고 사용되는 오브젝트들을 힙영역에서 만들어주게 된다. Malloc이나 new 를 이용해서 수행
✏️Memory Organization
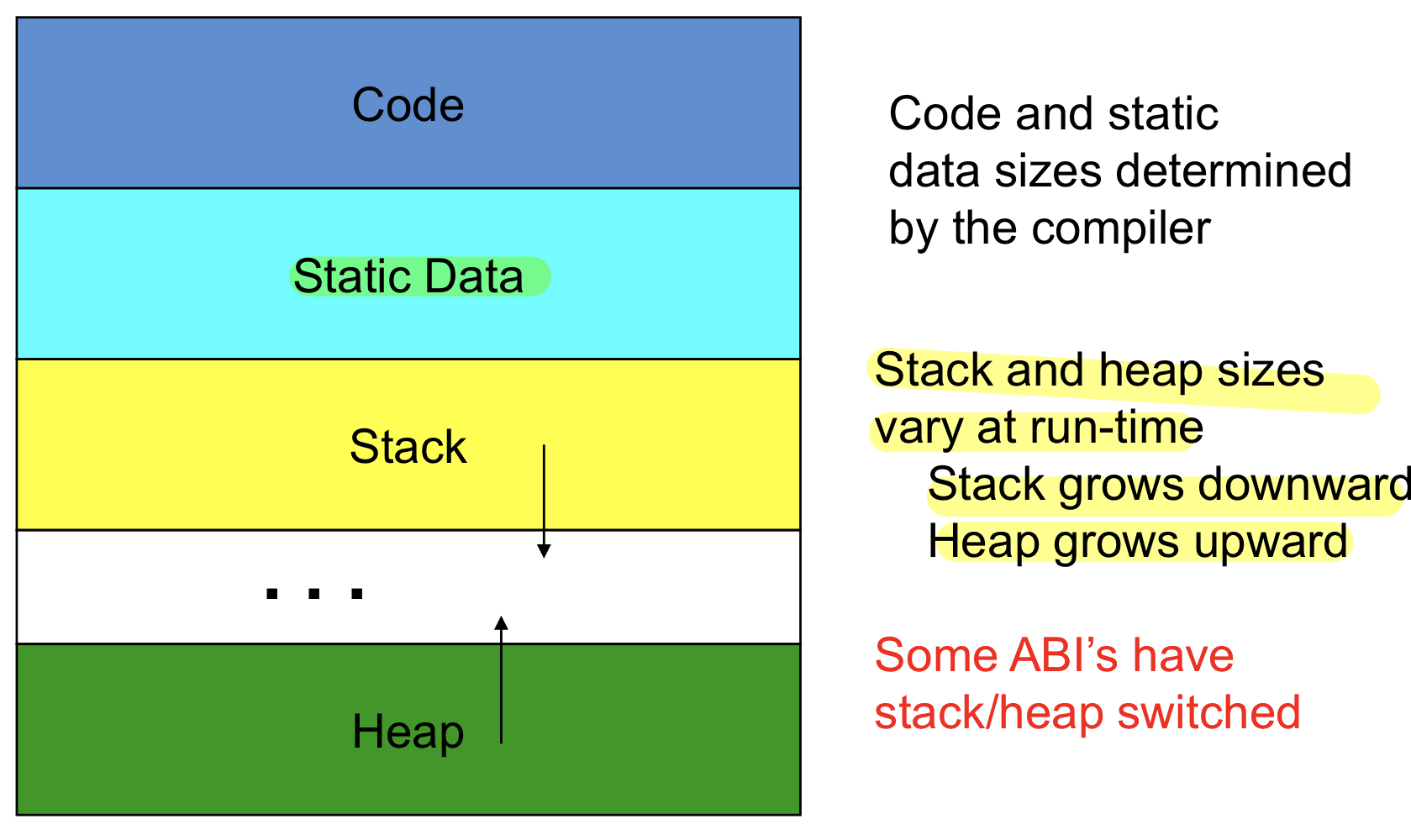
실제로 프로그램이 ssd에서 dram으로 로딩되면 이런 구조로 만들어지게 된다. 코드가 제일 위, static data가 있고 나머지를 스택과 힙으로, 스택과 힙은 데이터를 더 많이 할당할수록 반대로 커지는 편,스택은 위에서 아래로 힙은 아래에서 위로 증가하는 편
- 스택은 로컬 변수가 저장되고 function이 수행될 때마다 증가되고 recursion이 너무 많으면 스택 오버플로우발생 : 힙영역을 넘겨서 사용가능한 영역을 넘어갈 때 말함
- 스택은 로컬 변수를 저장, 힙은 동적할당으로 선언한 변수를 관장하는 영역
- 스택과 힙의 사이즈는 런타임마다 달라지고 효율적으로 쓰기 위해 반대방향으로 사용, 스택과 힙 중에서 무엇을 더 많이 사용할지 모르기 때문, 절대적인 방향은 중요하지 않고 반대인 것만 알면 됨
cf. segmentation fault는 허락되지 않는 메모리 접근 시 발생
Variable Binding
Variable과 memory location을 매칭하는 것을 의미
- Definitions
- environment : name과 storage location을 맵핑하는 함수
- state : storage loctaion에서 value를 맵핑하는 함수
- storage location S with a name N == N is bound to S
어떠한 이념을 가진 variable이 어떤 location s에 할당이 되었다는 것은 어떠한 n이 s에 바운드되었다라고 표현
Static Allocation
- static storage는 fixed allocation이기 때문에 program execution동안 변하지 않는다
- used for
-
global variables, constant, all static varibles in C
글로벌, 상수, static variable이 static allocation을 이용하고 static region에 저장됨
-
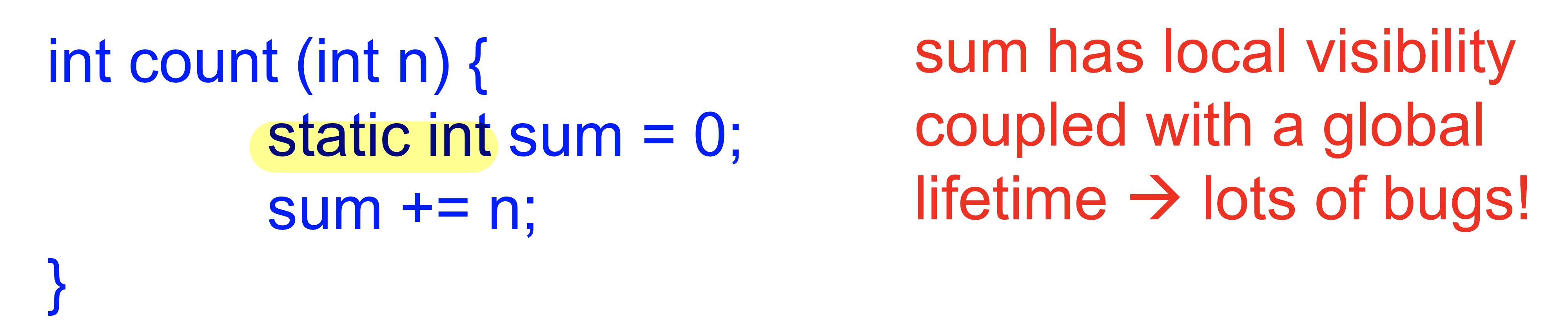
Static int라고 하면 한번만 초기화되고 다시 초기화되지 않는데 얘가 static allocation으로 할당되었기 때문
Heap allocation
-
continuous storage를 조각조각 짤라서 메모리 오브젝트를 만들어 쌓는 것
사이즈를 지정해서 allocate하면 공간을 할당해서 첫번째 피스를 리턴하고 그 포인터로 접근
-
piece들은 순서 상관없이 deallocate될 수 있다.
원하는 순서대로 만들게 되고 힙에 할당된 variable은 할당이 해제되는 것도 랜덤하게 가능
-
heap is global(프로그램 전체에서 사용되기 떄문)
-
item은 명시적으로 free될 때까지 존재
어느 정도의 크기가 있고 free를 하지 않으면 영역을 사용하지 않아도 자동으로 사라지지 않게 된다.
-
garbage collection을 지원한다면 no one point일떄까지 존재
-
스택에서 사용하는 local variable은 실행될 때 생기고 해제되면 자동으로 메모리에서 사라지기에 메모릭 관리가 필요없지만 동적할당으로 된 경우에는 직접 해제하지 않는 한 사라지지 않는다. 오브젝트의 delete, free를 짝에 맞춰서 잘해야한다. Free하지 않은 동안 존재하고 garbage collection을 하게 되면 자기가 알아서 없애는 경우도 있지만 쉬운 일은 아님
accessing static /heap variable
Static, heap으로 만들어진 변수를 어떻게 접근?
- static
- compiler가 알고 있는 주소를 이용(linker가 할당)
- compiler backend는 symobolic name(label)을 사용
Static은 컴파일러가 위치를 알고 있음. 지정된 위치에 만들기에 그 레이블을 어딘가에 저장하고 맵핑되는 이름으로 접속 가능
- heap
- unnamed locations
- address를 가지고 있는 dereferencing variable을 통해서 접근 가능
힙은 이름이 없고 포인터만 알기 떄문에 어드레스로 데이터에 접근하게 된다(pointer)
💯Run-Time Stack(매우매우 중요)
Function실행 시 사용하는 로컬 변수를 저장하는 부분
Run time stack은 새로운 함수가 call되고 또 부르고 리턴되고 등등을 구현하기 위해 call 할떄마다 커지고 return할 때마다 작아진다. 용량이 런타임마다 달라지기에 런타임 스택이라고 한다
- 매 function execution마다 frame(activation record)생성
- function이 동작하는 execution environment를 표현
- definiton마다 하나가 아니라 호출마다 생성됨! recursive function의 경우 호출될 때마다 frame 생성
- 콜마다 자신의 프레임을 가지게 되고 recursion이 발생하면 자꾸 자라나서 나중에 스택 오버플로우가 나게 된다.
- local variables, parameters, return value, temporary storage(register spill, 레지스터를 사용하다가 다 저장할 수 없을 때 메모리에 잠시 저장하는 경우 사용) 저장
- function이 동작하는 execution environment를 표현
- run-time stack of frames
- program이 function을 호출할 때 f의 frame이 Push
- f가 return될 때 stack frame이 pop
- top frame = 제일 위에 있는 프레임, 현재 실행하고 있는 function의 frame
Q. runtime stack은 하나의 function을 수행할 때 커질 수 있을까?
A. register spill로 인해 커질 수 있다.
stack poiner
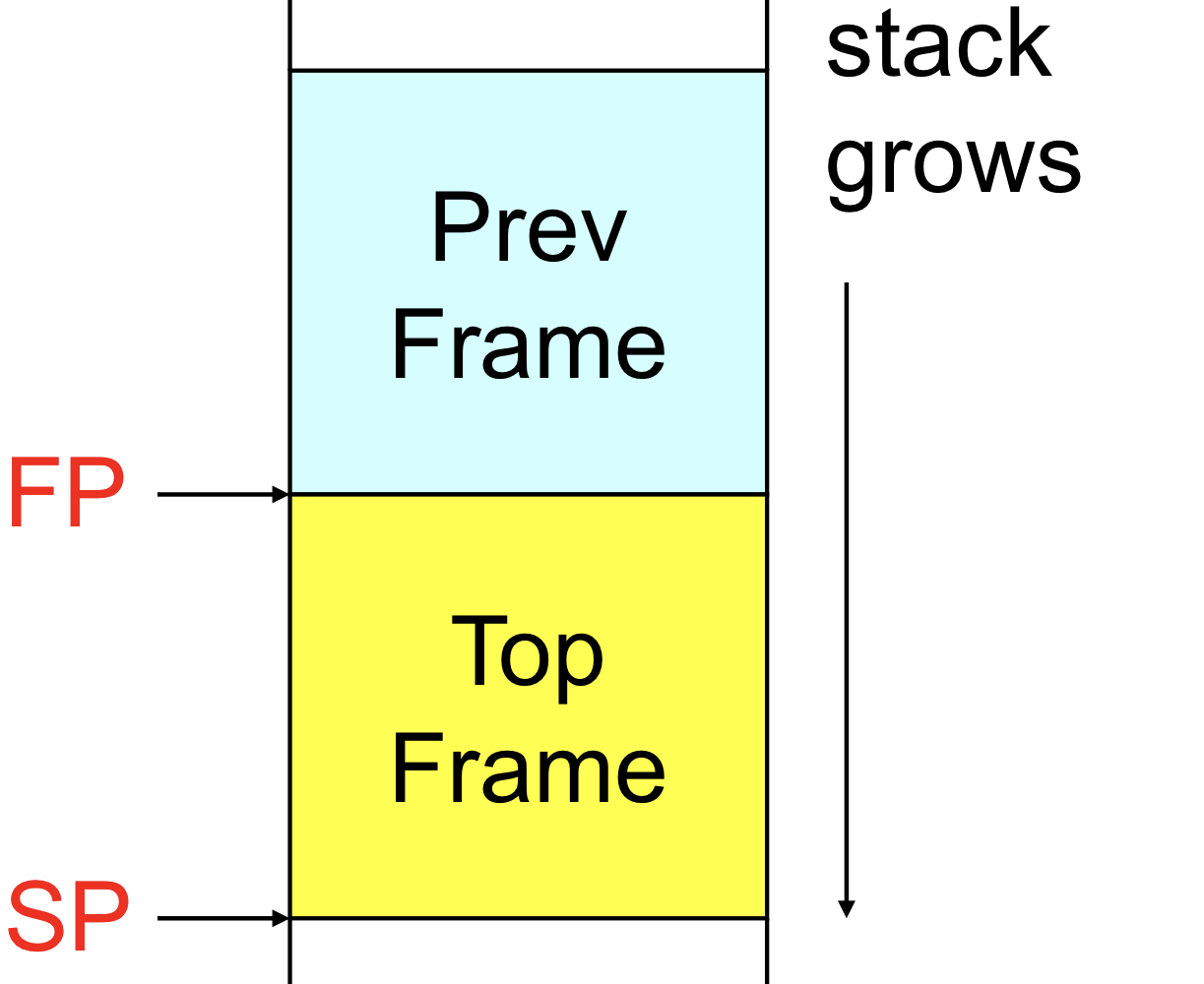
- 가정 : 스택은 아래쪽으로 커지며 address가 커진다고 가정
- value of current frame accessed using 2 pointers
- stack pointer(SP) : frame top을 가리킴,Runtime stack의 top 위치를 가리키는 포인터
- frame pointer(FP) : frame base를 가리킴, 현재 실행하고 있는 function frame의 based address
- variable access : use offset from FP(SP)
스택 프레임을 관리하기 위해 두개의 포인터를 가짐
Stack = first in last out, 저장하는 메모리와 push/pop이라는 오퍼레이션, tos stack pointer가 필요, 스택은 tos를 저장하는 것이 중요하므로 항상 하나씩 존재함
- 프레임이 들어오게 되면 가장 위의 위의 주소가 stack pointer이고 frame pointer는 현재 내가 실행하고 있는 function frame의 첫번째 위치가 된다
Top frame에는 여러개의 local 변수가 있고 access를 하기 위해서는 fp를 이용해서 얼마나 먼지를 가지고 접속하게 된다
Q. 왜 fp를 가지고 왜 fp로 접근하는가???
A. 스택 포인터를 프로그램 동작이 커졌다 작아졌다가 가능하기 때문, 변하지 않아도 변수와 멀수 있기 때문에 절대로 변하지 않는 fp를 기반으로 계산한다
Why 2 stack pointers?
- keep small offsets
Offset을 작게 만들고 싶어서 주로 fp에 변수에 가깝기 때문
literal의 사이즈가 제한되어있기 때문
- real reason
- 스택 사이즈가 항상 컴파일타임에 아는 것이 아니라 커졌다 작아졌다가 가능하므로 기본 based address가 변하면 제대로 동작하지 않을 수 있기 때문에 fp를 기준으로 데이터를 접속
- register spill이나 alloc가 추갖거으로 필요할 수 있기 때문
Anatomy of a Stack frame
stack frame에 들어가는 데이터
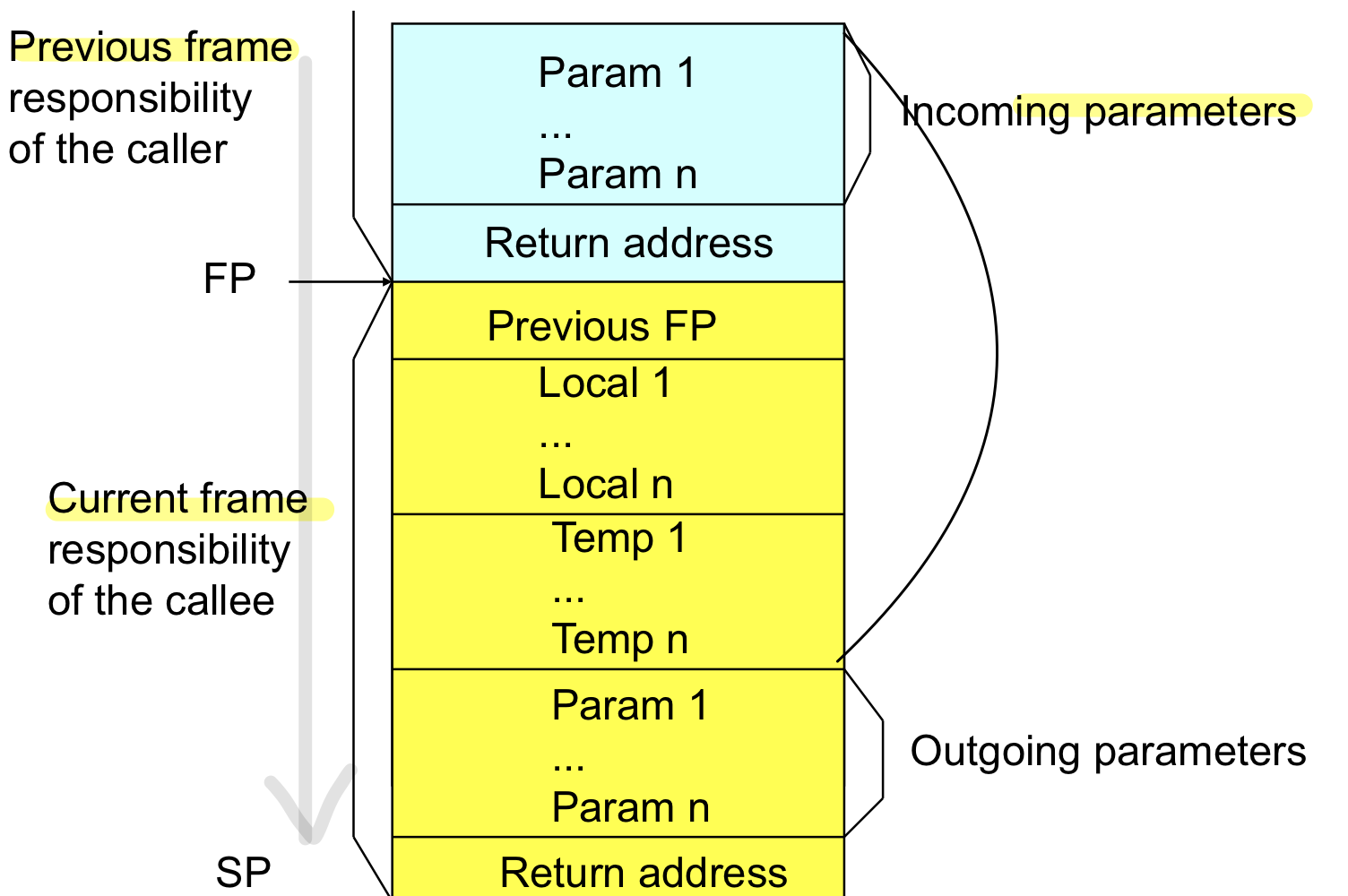
현재 tos frame을 보면 fp부터 시작하는데 이전의 fp과 local 변수와 temporary가 저장되고 파라미터가 저장되는데 파라미터는 나의 파라미터가 아니라 내가 부르는 함수의 파라미터이고 return address도 내가 새로 부르는 함수의 return address임
현재 사용되고 있는 데이터는 그 전 프레임의 파라미터와 return address + 노란색 temp까지
function call하기 전에 파라미터와 Return address를 저장한 후 지금 수행하고 있는 함수가 존재한다면 이전의 fp값을 저장하고 local, temp 등을 저장하고 다음 호출할 function이 사용할 값들을 저장해준다.
cf. 아키텍처마다 fp,sp의 지점을 다를 수 있음.
‼️Stack Frame Construction Example(매우매우매우매우 중요)
예시 중요, 스택이 어떻게 커지는지 알아야 함
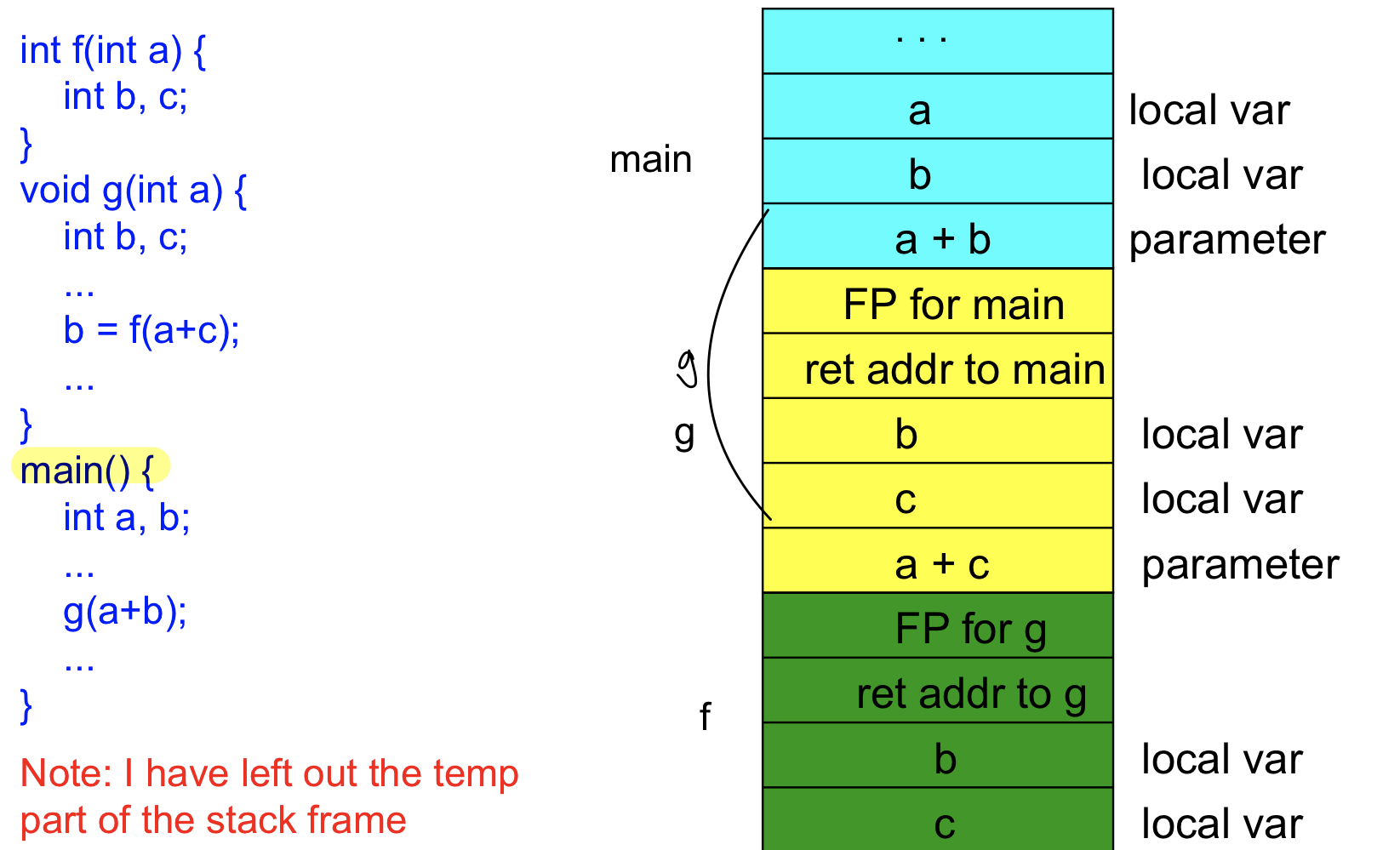
메인함수가 있고 local 변수 a,b가 있고 function call하게 되면 a+b가 파라미터로 가게 된다. 그 뒤에 main의 fp가 저장되고 main의 return address 후에 b,c,가 저장됨
나를 부른 function의 fp를 저장하는 이유는 return이 될 때 두개의 포인터(sp,bp)를 이전의 상태로 되돌리기 위함
Class problem-중요
- 스택에 들어가는 프레임이 어떻게 사라지고 생기는지 보면 좋을 듯
Saving Register
스택에 레지스터 정보를 저장해줘야 한다
-
problem : execution of invoked function may overwrite useful values in register
하드웨어적인 이슈가 존재, cpu는 각 함수마다 레지스터를 이용해서 동작하게 됨. 하나의 함수가 실행될 때 다음 함수에서 이전에 사용되고 있던 레지스터를 다시 사용해야 하는 경우 존재
: 이전에 동작하던 함수가 끝나지 않았으므로 백업을 해줘야 한다, Temporary data를 저장해줘야 한다
→ generated code must :
- save registers when function is invoked
- restore registers when funciton returns
- 가능한 방법(Callee(call을 당하는함수), caller(call하는 함수))
- callee saves(add가 저장)/ restores registers(add가 리턴되기 전에 복구)
- caller saves(call하기 전에 main 저장) / restores registers(돌아와서 main 복구)
→ 이러한 레지스터 세이브하고 복원하는 것을 둘다 할 수 있고 이건 컴파일러가 결정
ex)
main(){
int a,b,c;
add();
c=a+1;
메인이 있고 add 함수를 동작시킬 때 이전에도 r5를 사용하고 add 후에도 r5를 사용하며 add함수에서도 사용된다면 스택에 r5값을 저장해놔야 한다 그다음에 add에서는 사용한 후 끝날 때 r5를 다시 복원한다면 add를 리턴하고 나서도 자유롭게 사용 가능
- caller는 main, callee는 add
}
int add(){
}
- 새로 콜된 함수 실행시간동안 원래있던 레지스터 중에 나중에 사용하는 변수를 overwrite 할수 있으므로 콜하기 전에 스택에 미리 저장해놓는다. 컴파일러는 콜 될 때 레지스터값들을 저장하고 다시 복구하는 코드가 추가되어야 한다. 또한 추가되는 위치도 다를 수 있음
- 콜할 때마다 모든 레지스터를 저장 -> 너무 속도가 느리니까 필요한 레지스터들만 저장 -> 메인 함수에 레지스터를 많이 사용하지 않고 add도 많이 사용하지 않다면 저장하지 않을 경우도 있음 Function call return 시 레지스터를 저장하는 오버헤드가 크니까 add function이 작다면 function call보다는 inline 키워드를 붙여서 줄여줄 수 있음. 대신 인라인을 쓰면 function call return overhead는 줄여주니만 code size가 커지며 register pressure가 커져서 좋지 않음. 큰 함수라면 메인 함수가 킵해야하는 레지스터의 개수와 add함수가 킵해야하는 레지스터 수를 합해서 문제가 생길 수 있음 → Inline은 함수 사이즈가 작을 때 유용 실제로 function call을 하면 register management해야하는데 이러한 코드는 컴파일러가 만들어줘야 한다.
Q. call하기 전에 레지스터를 저장하는 이유?
A. 레지스터를 callee에서 사용할 수 있기 떄문, 레지스터가 공유되고 있기 때문에 메인 함수에서 돌아왔을 때 의미있는 값들만 저장하면 됨
Q. 어떻게 알 수 있을까?
A. data flow anlysis를 통해서 각 Local variable의 life ragne를 분석해서 저장유무를 결정 가능
Q. 무조건 저장해야 할까?
A. A에서 사용되지 않는 경우라면 메모리에 저장되지 않아도 된다. 컴파일러가 결정
Calling Sequences(꼭 따라해볼 것)
(calling convention)
실제로 function call이 일어날 때 어떻게 프레임을 만드는 코드를 만들어 낼 것인가?
- generate code which pushes value on stack:
- before call(caller responsibilities)
- at function entry(callee responsiblities)
- genearte code which pop values off stack:
- after call instructions(caller responsibilities)
- at return instructions(callee responsiblities)
Push values on stack
- code before call instruction
- push each actual parameter
- push caller-saved registers(temporary register value)
- push static link
- push return address(current pc) and jump to callee
- prologue = code at function entry
- push dynamic link(old fp)
- old stack pointer값이 new frame pointer가 됨
- push callee saved register
- push local variable
Pop values from stack
- Epilogue = code at return instruction
- pop callee saved register(restore)
- store return value at appropriate place
- restore old stack pointer==pop callee frame
- pop old frame pointer
- pop return address and jump to that address
- code after call
- pop(restore) caller-saved registers
- use return value
Example Call(예시 꼭 따라가볼 것, 몇바이트인지도 알아놓을 것)
- call foo(3,5),machine은 r1,r2 레지스터를 가지고 있고 callee save
- code before call instruction
- push arg1 : [sp]= 3
- push arg2 : [sp+4] = 5
- make room for return address and 2 args : sp = sp +12
- call foo
- prologue
- push old frame pointer : [sp] = fp
- compute new fp : fp = sp
- push callee saved register : [sp+4] = r1, [sp+8] = r2
- create frame with 3 local variabble, sp = sp + 24
→ 총 36바이트 증가
- epilogue
- pop r1,r2 : r1=[sp - 20], r2 = [sp-16]
- restore old fp : fp = [sp-24]
- pop frame : sp = sp - 24
- pop return address and excture return
- code after call
- use return value
- pop args : sp = sp - 12
→ 36바이트가 감소하므로 다시 원래대로 돌아왔음
Accessing stack variables
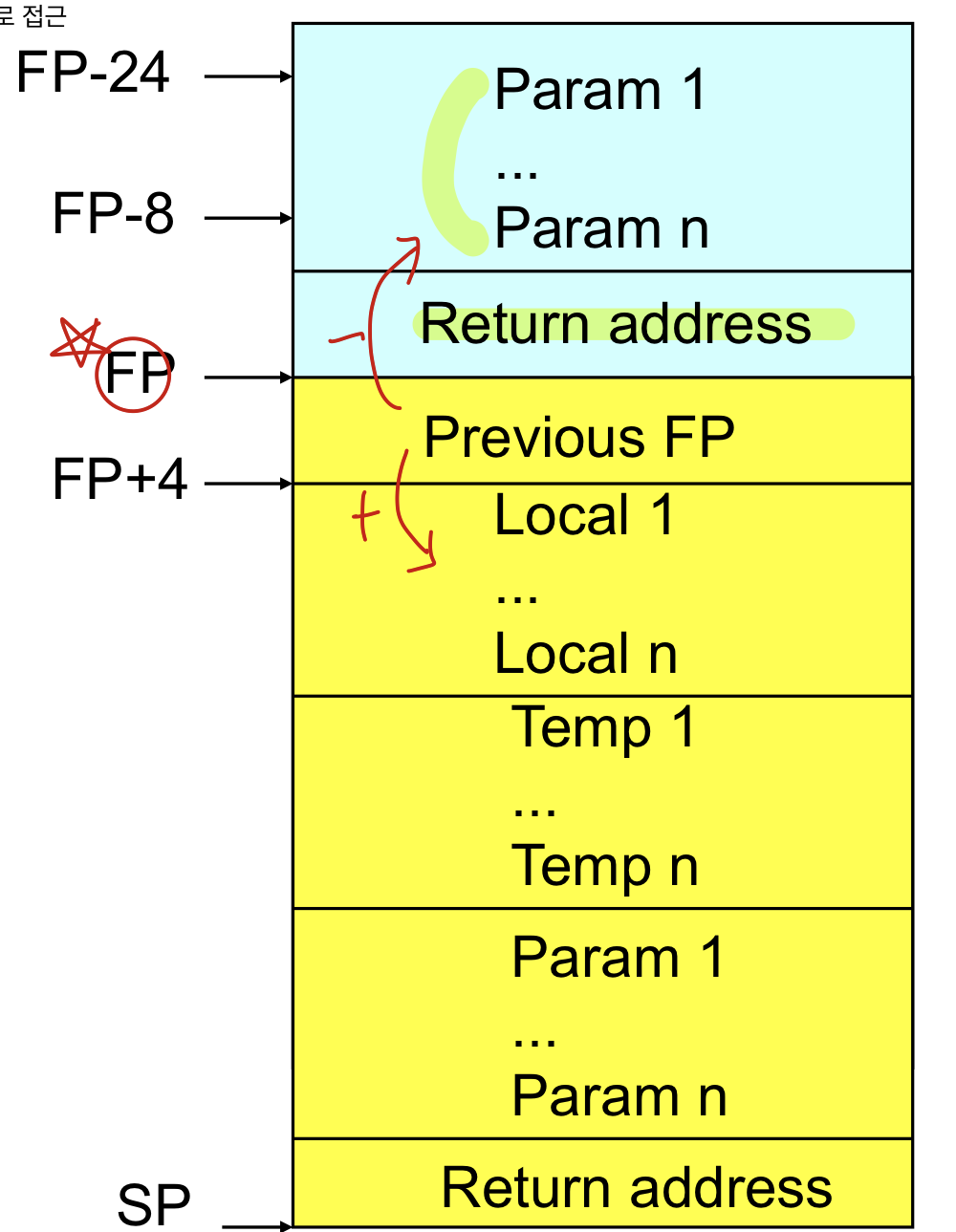
- stack variable은 fp로부터의 offset을 이용하여 접근
- 파라미터는 - offset으로 접근하고 로컬변수는 +offset으로 접근
Data layout
Composite한 data를 어떻게 저장하는가? 여기있는 것만 이해하면 됨, 데이터 레이아웃을 어떻게 할 것인가?
- naive layout strategies generally employed
- place the data in the order the programmer declared it!
-
두가지 issue : size, alignment
1 : 각각의 데이터타입의 사이즈
2 : alignment, 위치들이 잘 맞아야 한다.
size - how many bytes is the data item?
- base types have some fixed size : 각각의 아이템이 몇 바이트를 가지고 있는지
- char(1),int(4),float(4),double(8)
- composite types(structs, unions arrays)
- overall size = sum of the components(component합보다 클 수 있음. Alignment를 위해서)
- calculate an offset for each field : 각각의 첫번째 address를 offset이라고 하고 type의 맨 처음 주소를 base address라고 해서 composite type은 structure의 base address + offset으로 접근
- 사이즈에 따라서 alignment가 정해짐 만약에 character라면 0123..이 address로 저장될 수 있고 int라면 4바이트니까 0,4,8.. 등에 저장될 수 있음
ex) struct{char a; int b; double c; char d; }
기본적으로 순차적으로 저장한다면 character variable, a가 들어간다면 0번지가 a라면 integer b가 1,2,3,4 들어갈 수는 있지만 alignment가 되어야 하므로 b는 0,4,8에만 가능, a에서 지정하고 나머지는 비워야 함.
Q. 만약 캐릭터가 하나 있어서 빈 자리에 들어가면 좋을 거 같은데??
A. Structure을 효율적으로 만들기 위해 순서를 바꿔서 저장할 수는 있지만 순차적으로 하는 것이 기본이라서 뒤에 들어갈 것, 시험문제에도 alignment에 맞춰서 쌓고 컴파일러는 변수의 순서를 바꾸지 않을테니 코드의 순서를 바꾸던가 컴파일러가 바꾼다고 가정해서 효율적으로 Structure 사이즈를 줄이도록 해봐라 물어볼 수 있음
Memory Alignment
- cannot arbitarily pack variables into memory
→ alignment를 고려해야 한다
- golden rule— address of variable is aligned based on the size of the variable, variable 사이즈에 맞춰서 align되어야 한다
- 캐릭터는 0,1,2,3,… 이고 short는 0,2,4,6,8 이고 int는 0,4,8 ..
- 컴파일러마다 다르므로 시험에서는 여기서 얘기한대로 변수 순서에 맞춰서 하거나 컴파일러가 메모리의 사이즈를 줄이기 위해 순서를 바꾼다 가정해서 쓰면 됨
structure alignment(for c)
- Declare된 순서로 layout하는데 이때 golden rule(자기 사이즈따라서 address 지정)을 잉해서 지정
- identify largest field, 가장 큰 필드가 먼지 알아야 한다
- 각각의 structure은 가장 큰 필드의 alignment가 맞게 지정되어야 한다.
- size of overall struct는 Largest field의 배수이다
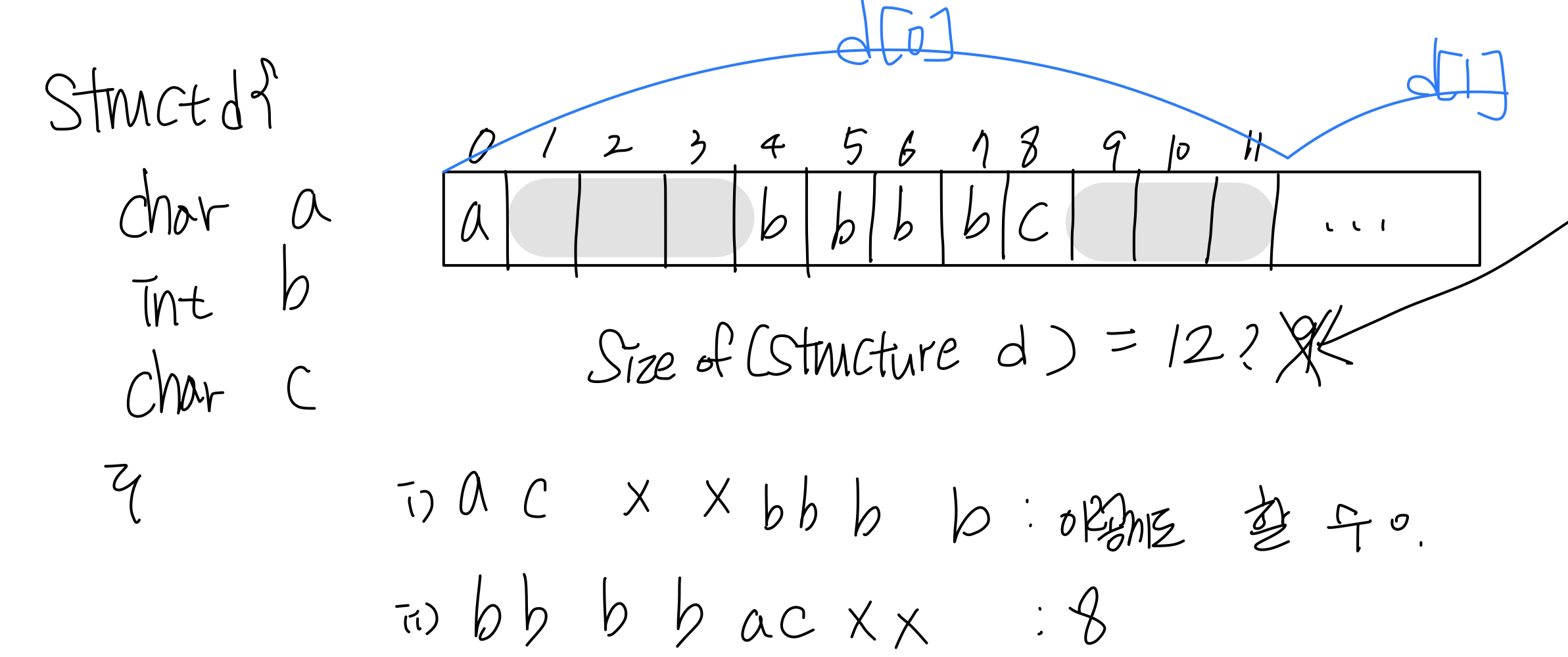
B가 largest field를 정의한다면 12가 됨. 왜냐면 가장 큰 필드의 integer b의 offset과 같이 가기 때문에 사용되지 않는 부분들이 존재
D[1]은 12부터 시작한다는 의미, d[1]의 char이 9,10에 들어갈 수 없다는 의미!
가장 큰 필드의 b의 offset값과 같이 가야하기 때문에 사용되지 않는 값이 존재할 것
시험문제도 이런걸 낸다고 한다면 오늘 얘기한 거정도로만 나올 것
- golden rule이 있고 (alignment 맞춰야 한다), declare된 순서로 레이아웃하고 가장 큰 field에 align이 맞도록 첫번째 address에 맞아야 한다. 컴파일러가 선언 순서를 바꾼다면 더 줄일 수 있다
Cf. b가 제일 먼저 와도 상관은 없음
Cf. alignment가 들어온 것은 사이즈끼리 붙게 되면 하드웨어적인 문제가 존재, 32비트라면 32비트 단위로 데이터를 접속하게 되는데 align이 잘못된다면 두번의 load가 필요하기 때문
Largest filed가 4바이트이고 그대로 맞춰야 한다
Int가 아니라 double이라면 d[1]은 16부터 시작하는 것