compiler backend instruction
- Compiler backend는 어셈블리 레벨(machine independent하지만 low assembly한 언어)에서 시행되고 두가지를 생각한다
- 2가지 고려
- how to make the code faster
-
machine independent optimization : 알고리즘 최적화는 아니며 Instruction 수를 줄여야 하며 오래 걸릴 것 같은 instruciton의 latency를 줄여주는 instruction으로 변경. 각각의 strength를 줄여준다 : strenth reduction(오래걸리는 것을 줄여주고 instruction의 중요도를 줄여줌)
ex) *2 → «1
- machine dependent optimization
- program을 분석하고 behavior를 이해해서 훨씬 efficient form으로 바꿔준다
-
-
map program onto real hardware
IR level code는 virtual register라고 생각해서 레지스터의 수가 무한개라고 가정하면 virtual resource로 생각해서 리소스도 무한개라고 하지만 기본적으로 백엔드 code generation 과정에서는 Virtual한 요소를 physical한 요소로 바인딩하게 한다
- limitations of processor를 고려
- virtual to pyhsical binding(resource binding)
→ 실제 프로세서에 레지스터 개수에 맞춰서 어셈블리를 만들게 되고 실제 프로세서에 존재하는 리소스에 수에 맞춰서 instruction과 Opcode를 만들고 스케줄링을 한다
- code size
- 코드 사이즈를 최소화하는 것도 목표 중 하나이기는 하지만 여기서는 중요하지 않음. 다만 임베디드, 사물인터넷, 이런 저런 다양한 작업을 수행할 수 있는 엣지 디바이스는 큰 코드를 저장할 수 없기 때문에 코드 사이즈를 저장하는 것도 중요함
- how to make the code faster
code generation : 실제 하드웨어에 맞춰서 instruciton을 만들고 Instruciton 순서를 조절
compiler backend structure
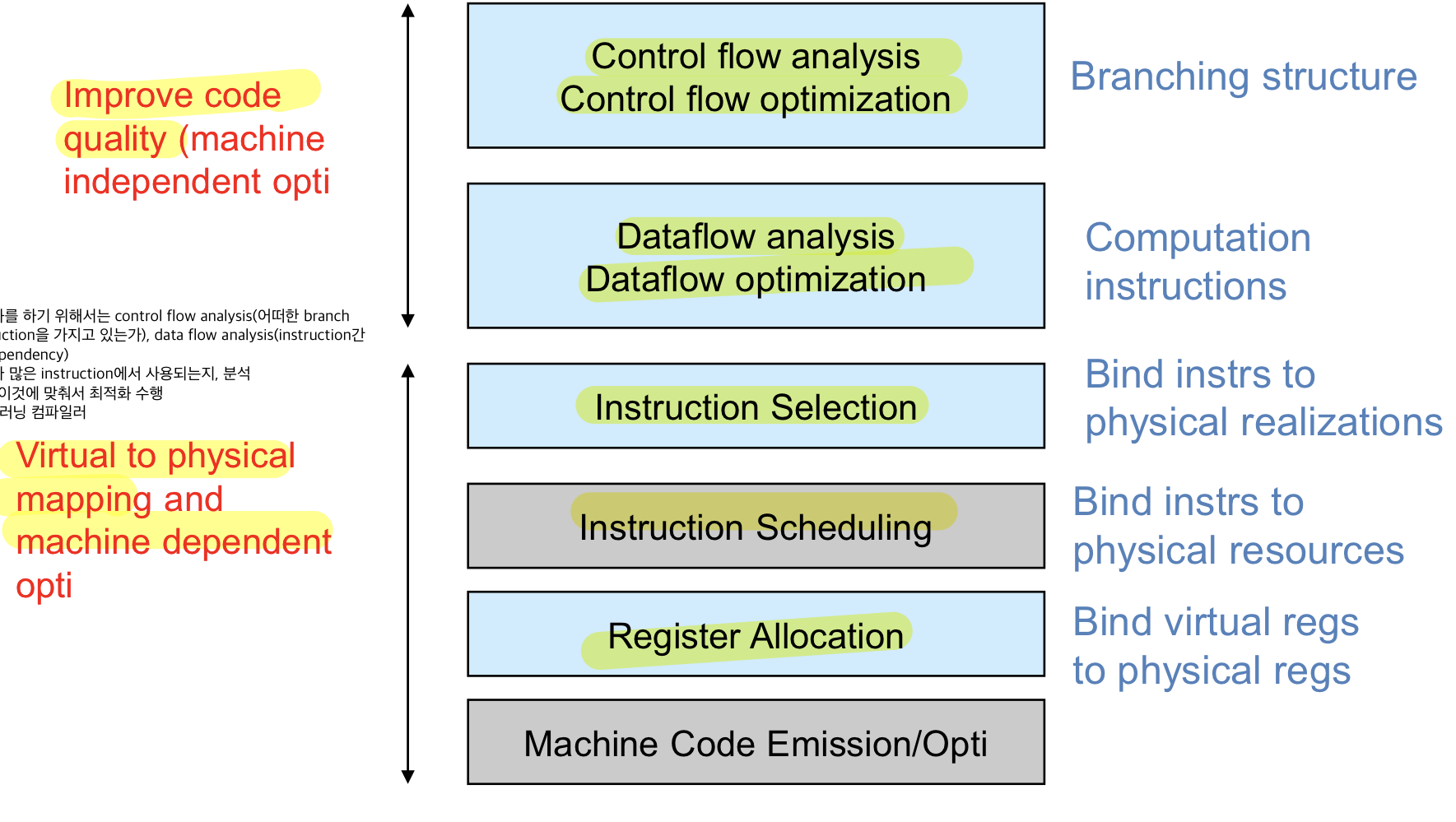
- 최적화를 하기 위해 control flow 분석(어떠한 branch instruction을 가지고 있는가?)과 최적화를 하고 dataflow 분석(instruction간의 dependency)과 최적화 과정을 통해서 코드의 퀄리티를 높여준다.
- 이후에 실제 타겟 하드웨어에 맞는 instruction을 만들어내는데 instruction selection, scheduling, register allocation으로 이루어져 있다
- virtual register를 실제 register로 맵핑해주는 것을 code generation이라고 하며 여기서도 최적화 수행 가능
Compiler backend IR
- low level IR(intermediate representation)
- machine independent assembly code, 무한개의 register, ALU를 사용하며 주로 세개의 operand와 하나의 opcode를 이용해서 4개의 요소로 계산
- r1 =r2+r3 or equivalently add r1,r2,r3
- opcode
- operands(3개로 구성)
- virtual register : infinite number of these
- special register : stack pointer, pc, fp ..
-
literals : compile time constants, no limit on size
immediate value는 constant value값에 제한이 있기에 포함되지 않는 것
- symbolic names : start of array, branch target
low level IR을 이용해서 backend process를 수행한다.
Control Flow
프로그램이 계속 sequential한 순서로 시행되지 않고 중간에 시행 순서를 바꿔야하는 경우가 있을 때 control action이라고 하며 control flow는 해당 프로그램의 control action에 관련된 정보를 고려한 것을 의미함
프로그램이 있을 때 branch instruction에 의해서 분기가 일어나는 것을 말함
- control transfer = branch(taken/점프한다 or fall through/점프를 하지 않는다)
- control flow
- branching behavior of an applicaiton
- instruction의 branch instruction에 의해서 실행 순서가 어떻게 변하는지 표현
- exectuion → dynamic control flow
- 특정한 branch의 방향
- 런타임에 브랜치 instruction의 testing 조건에 따라서 점프를 하거나 안할 수도 있기에 런타임에 방향이 결정→ 쉽지 않은 편 : 프로파일링 수행
- compiler → static control flow
- 프로그램을 실행하지 않고 control flow가 어떻게 구성되는지 파악, static하게 branch를 보고 점프할지 안할지를 선택
- 어떻게 실행될 지 모른다는 단점 존재
‼️Basic Block(BB)
-
group operations into units with equivalendt execution
control flow를 표현할 때의 기본 유닛으로 instruction의 모임
같은 exectuion condtion을 가지는 instruction의 그룹을 의미
-
Basic block : flow of control에 들어가면 중간에 멈추거나 분기되지 않고 끝까지 진행되는 연속적인 operation의 연속
연속된 instruction의 sequence이고 첫번째로 flow가 들어오면 이 마지막 instuciton을 통해서 나갈 때 까지 무조검 모두 실행되는 것을 말함
- straigth line sequence of instructions
- BB안에 든 하나의 operaton이 실행되면 끝까지 실행됨
-
finding BB’s : 첫번째는 bb를 시작하고 branch의 타겟이라면 새로운 bb여야 하며 어떠한 branch가 나와도 새로운 bb가 된다.(타겟 앞에서 짜르고 branch 뒤를 짜른다)
- first operation은 새로운 BB를 시작한다
- target of branch는 새로운 BB를 시작한다
- branch instruction 바로 다음 immediately follw는 새로운 BB를 시작한다.
-bb안에 있는 instruction은 마지막에는 branch가 올 수 있지만 중간에는 존재할 수 없다
- 어떠한 branch의 target address가 블럭 중간에 위치할 수 없다
-타겟으로 넘어가서 브랜치를 실행할 수도 있고 타겟으로 넘어가지 않고 바로 다음 instruction으로 넘어갈 수 있기에 타겟에서 새로 시작하고 브랜치 뒤에서 새로 시작한다.
Instruction들의 straight line 코드이고 베이직 블럭 안에 하나의 instruction이 실행되면 모든 instruction이 실행된다는 특성을 가짐
Q. 베이직 블럭에는 conditional branch가 들어갈 수 없다.
A. 거짓, 베이직 블럭 중간에는 올 수 없지만 맨 끝에는 존재할 수 있다.
rule 1)각 branch는 블럭 맨 끝에 위치
rule 2) 각 branch target이 bb를 시작
Control Flow Graph(CFG)
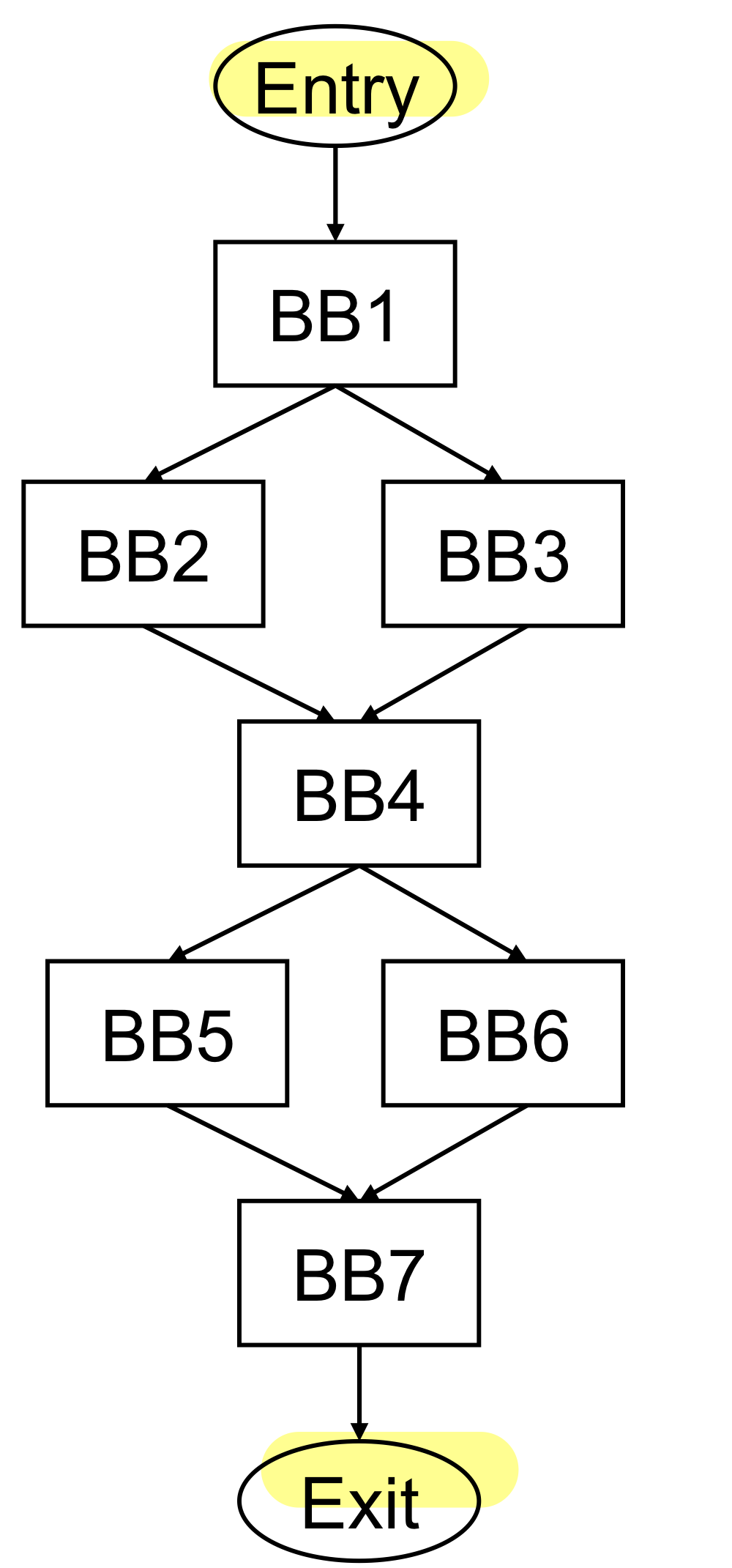
CFG는 각각의 BB를 control folw 구조에 따라 프로그램이 어떠한 구조로 흘러가는 지 표현해주는 그래프
- directed graph, vertex는 bb, edge는 immediately folow in some execution sequence
- bb는 모든 엣지에 bracnch할 수 있는 edge를 가지고 있다
- 각각의 BB의 끝이 브랜치일 것이므로 condition에 따라서 두개의 bb를 실행할 수 있을 것. Branch instruction에 따라서 다음에 실행할 수 있는 bb를 연결한 그래프를 의미
- BB를 브랜치로 끝날 때 갈 수 있는 target BB을 엣지로 모두 연결한 그래프
- standard representaion used by compilers
- pseudo vertics : entry node와 exit node
컴파일러는 처음으로 최적화를 하기 위해 CFG를 만들어서 자료구조로 저장함
weigted CFG
프로파일링을 통해서 프로파일링 정보가 CFG에 추가된 것을 의미
- Profiling : 1이상의 sample input을 이용하여 어플리케이션을 돌려서 행동을 기록, 어떠한 어플리케이션의 다이나믹한 특성을 알 기위해 몇번 구동 시킨 후 그때의 정보를 저장하는 것을 말함
- control flow profiling
- edge profile - 엣지가 몇번 수행되는가, 더 많이 사용
- block profile - bb가 몇번 수행되는가
-
control flow Profile을 CFG에 weight 표시
: weighted CFG
- profile info로 효율적으로 최적화한다
- optimize for the common case
- make educated guess
Ex) 2,3의 경우 반드시 반씩 수행되니까 둘다 함께 최적화해야하지만 5,6의 경우에는 5가 더 중요한 BB이므로 최적화 시 5를 좀 더 최적화해야 한다
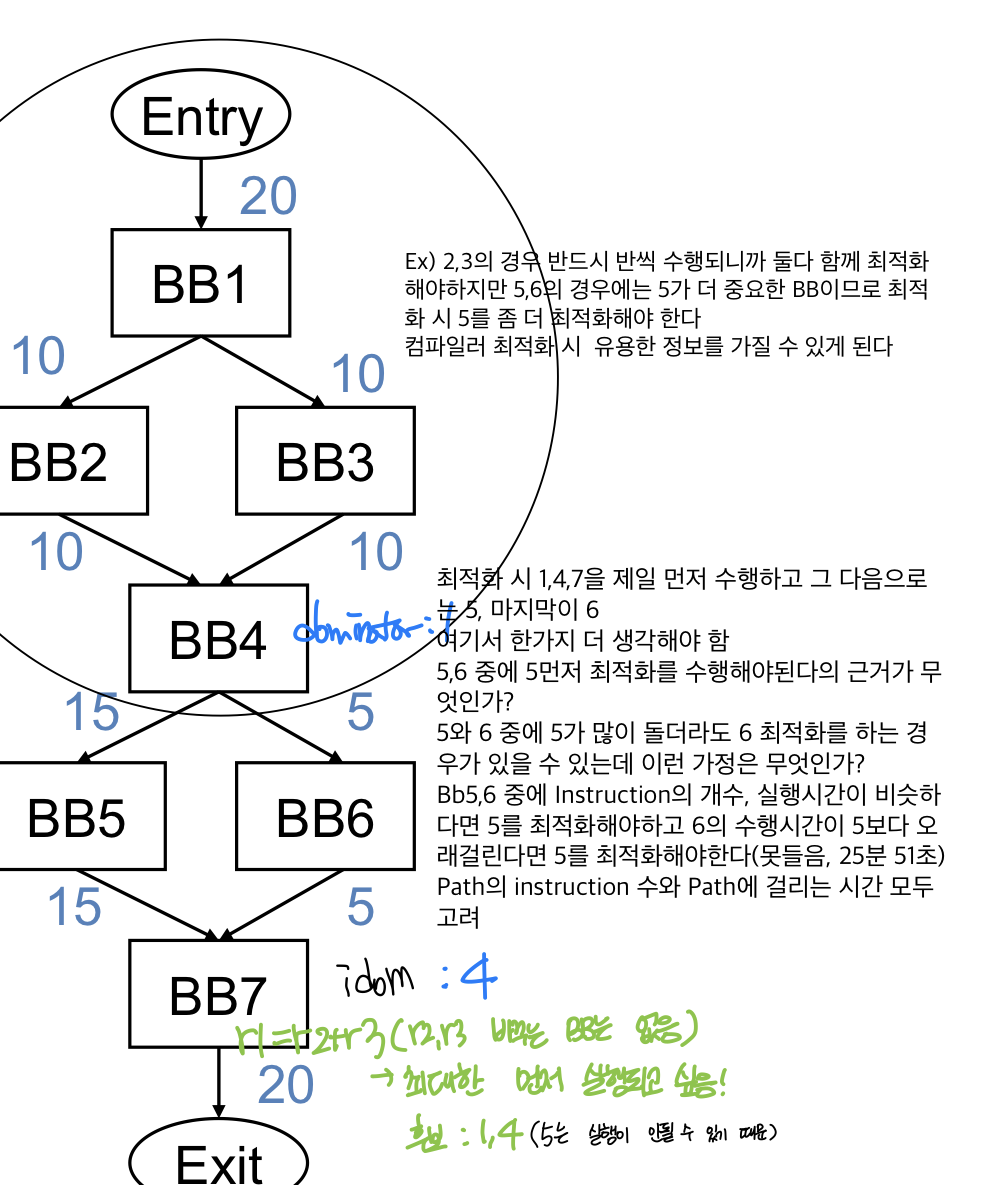
컴파일러 최적화 시 유용한 정보를 가질 수 있게 된다
Q. 프로파일링 시 가장 중요한 것
A. input value, 실행환경, 10초동안 동린다면 돌릴 Input이 프로파일링에 돌릴 데이터와 유사해야 한다.
Control Flow Analysis
- 프로그램의 branch structure에 따른 프로그램의 특성을 알아보는 것
-
Static property : 실행하지 않았을 때의 결과, branch에 의해 만들어지는 CFG를 보는 것 , not executing the code
↔ dynamic : 실제로 프로파일링을 하는 경우
- runtime branch directon과 상관없이 존재하는 특성
- CFG 사용
- 그 다음 프로파일링 정보를 추가해서 실제 CFG를 최적화
- optimize efficiency of control flow structure
-
Dominator
CFG가 만들어진 후 수행하는 control flow analysis 중 하나
Dominator : 무언가 노드와 엣지로 만들어진 CFG가 있을 때 어떠한 x노드가 y노드를 dominate한다 == entry에서 y까지 도달 시 모든 path에 x를 지나가는 경우
- dominator의 세가지 특성
- 각각의 BB는 자기자신을 dominate한다
- x dominates y, y dominates z → x dominates z
- x dominates z , y dominates z → x dominates y or y domiantes x
- 직관적으로 말하자면 어떠한 bb가 있을 때 이걸 수행하기 전에 무조건 수행되는지를 보는 것, 무조건 먼저 시행되는 블럭을 나의 dominator라고 한다
Dominator analysis
- compute dome(BBi) = set of BBs that dominate BBi
- initialization
- dom(entry) = entry
- dom(나머지) = all nodes
- initialization
-
iterative computation

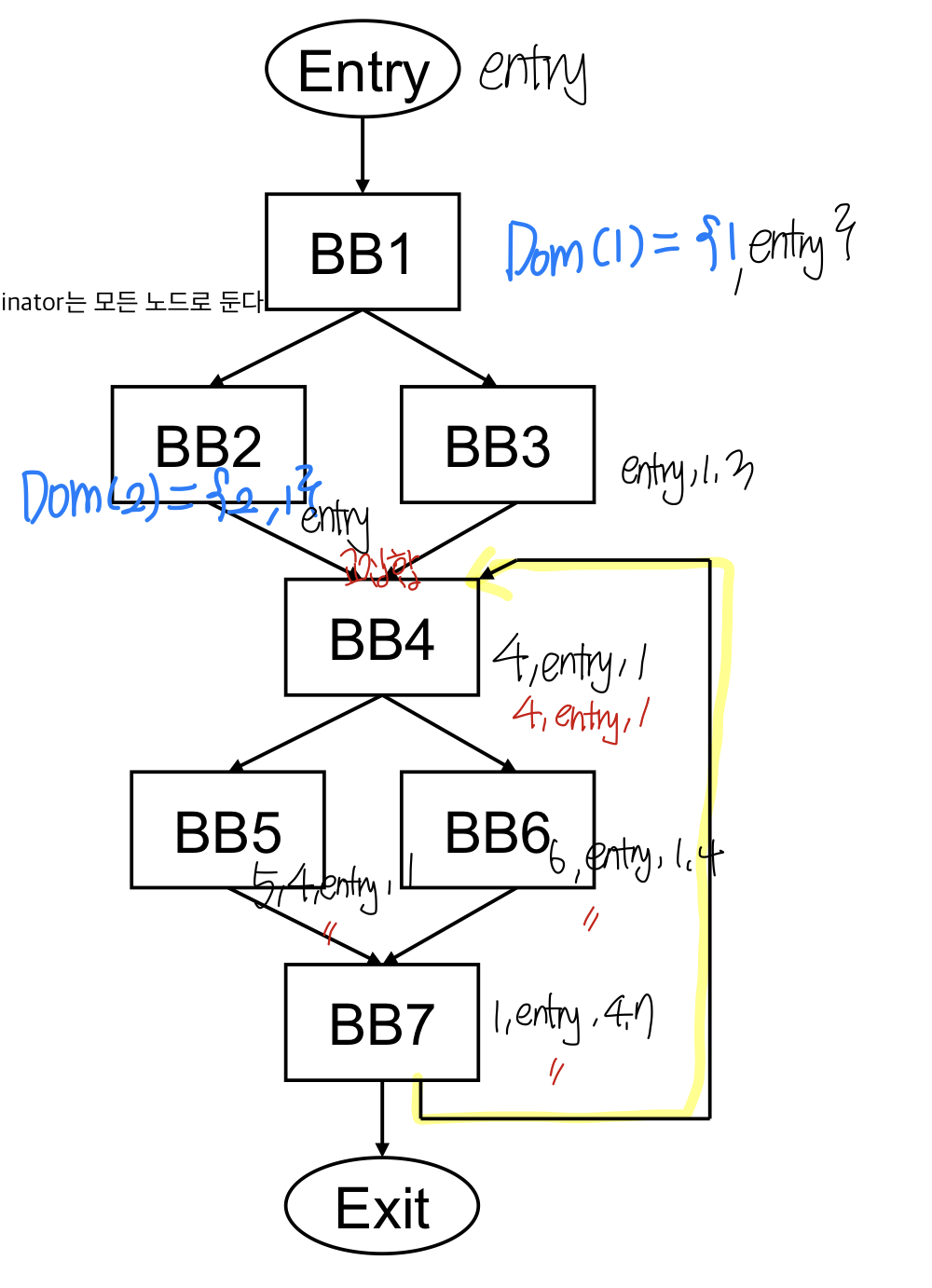
각각의 BB에서 어떠한 temporary bb의 set은 나의 bb와 내가 실행하기 전에 모든 BB의 교집합을 추가해주면 temporary set이 되고 이게 현재의 dominator과 다르다면 dominator set을 업데이트해주면 된다. Dominator analysis를 여러번 수행하는 것, 루프들이 있을 수 있으므로 한번 한다고 다 알 수는 없고 모든 dominator 정보가 코드를 한번 수행시 바뀌지 않을 떄까지 수행해야 한다
cf. successor과 predecessor : 나에게 input을 주는 애, 나의 output을 사용하는 애
immediate dominator
어떠한 블럭에서 가장 가까운 dominator를 의미
initial에서 n으로 가는 Path 에서 last dominator
- closest node that dominates
Ex) dom(7) = 1.4.7인데 내가 아닌 노드 중에서 가장 가까운 BB는 4가 된다 IDOM(7) = 4
Post dominator
Dominator와 동일한데 반대의 의미
- CFG가 주어져있을 때 x post dominates y== y에서 exit으로 가는 모든 Path에 x가 존재
- intuition
- 어떠한 bb가 있을 때 내가 실행된 후에 무조건 실행되는 BB가 post dominator이다
Post Dominator Analysis
- pdom(BBi) = set of BBs that post dominate BBi
- initializaiton
- pdom(exit) = exit
- pdom(나머지) = 모든 노드
-
iterative computation

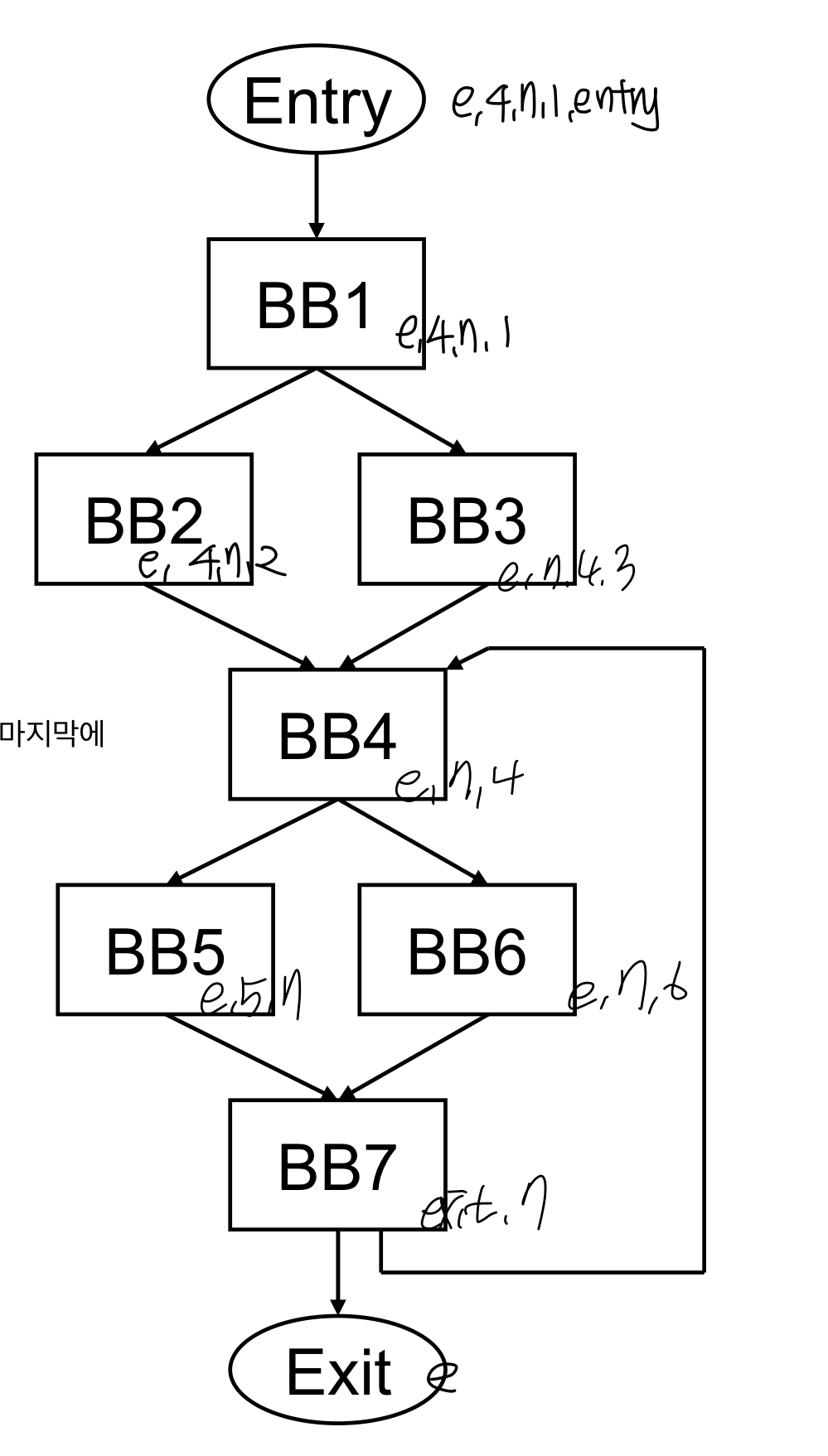
post dominator는 어떠한 instruction을 되도록 마지막에 실행하고 싶을 때 사용, exit부터 시작해서 뒤에 있는 pdom의 교집합으로 계산
Immediate post dominator
나를 post dominator하는 것중에 나와 제일 가까운 노드
Why do we care about dominators?
Control flow analysis를 통해서 dominator로 뭘 얻으려고 하는 건가?
- Loop detection
- Loop를 찾을 수 있다(이게 제일 중요), 어떠한 프로그램을 수행하면 대부분의 시간은 loop에 해당하는 코드이므로 루프를 최적화하는 것이 가장 중요 -> 루프를 찾는 것이 가장 중요하고 이부분을 최적화하는 것이 중요 . hhl에서는 키워드로 루프를 금방 찾을 수 있지만 CFG로 한번에 찾기는 어려워진다. -> 루프를 찾기 위해 dominator analysis를 한다
- dominator
- 이전에 실행되는것을 보장
-
redundant compution : domintaing bb에서 comput된다면 redundant할 수 있다
ex) 어떠한 instruction이 1,4 둘다 존재한다면 하나의 instruction을 지우는 등의 최적화를 할 수 있다. 1와 4를 함꼐 최적화의 대상으로 볼 수 있으므로 좀 더 많은 instruciton들을 가지고 최적화를 수행할 수 있으므로 중요함
- most global optimization은 dominator 정보를 사용
- global optimization : 여러개의 bb에서 사용
- local optimization : 하나의 bb안에서 사용
→ 좀 더 많은 instruction을 가지고(여러개의 블럭을 통틀어서 생각 가능) 최적화를 수행할 수 있음
- post dominator
- 그다음에 수행되는 것을 보장
- make a guess(2 pointers do not point to the same locn)
- check they really do not point to one another in the post dominating BB
ex) 4에 load, store명령어가 있는데 기본적으로 로드는 빨리 시행하는 게 좋고 store은 나중에 실행하는 것이 좋음->bb4를 빠르게 수행하기 위해서 bb1로 옮겨서 수행 가능, 왜냐면 bb가 시행되면 bb1도 반드시 수행되기 떄문-> 성능적인 이득을 얻을 수 있다
다만, 항상 되는 것은 아니고 dependency를 봐야 한다
Store은 되도록 늦게 해야하니까 7으로 옮겨서 좀 더 늦게 수행되도록 할 수도 있다
이때, store을 5,6에 옮길 수 없는 이유는 무조건 실행되지 않기 떄문
Natural Loops
Loop은 가장 중요한 최적화를 위한 region
왜냐면 대부분의 컴파일러는 루프를 최적화하려고 노력함. 하나의 코드가 여러번 수행되는 부분이 루프밖에 없고 가장 많이 실행되는 부분일 경우가 높으므로 가장 높은 점유율을 가질 것이기에 루프를 잘 찾고 최적화를 하는 것이 중요
- cycle suitable for optimization
- 2 protperties :
- single entry point(header)가 존재, header는 loop에 있는 모든 블럭을 dominate
- 반드시 iterate the loop하는 방법이 존재(하나의 Path가 loop로부터 헤더로 돌아감) : backedge
- backedge detecton
- edge x→y : target(y) dominates the source(x)
- x→y && dom(x)= {y}
루프를 detect하는 가장 큰 핵심은 back edge를 찾는 것, 어떠한 edge가 있는데 target y가 source를 dominate한다
백엣지를 찾기 전에 dominator정보를 알아야 한다
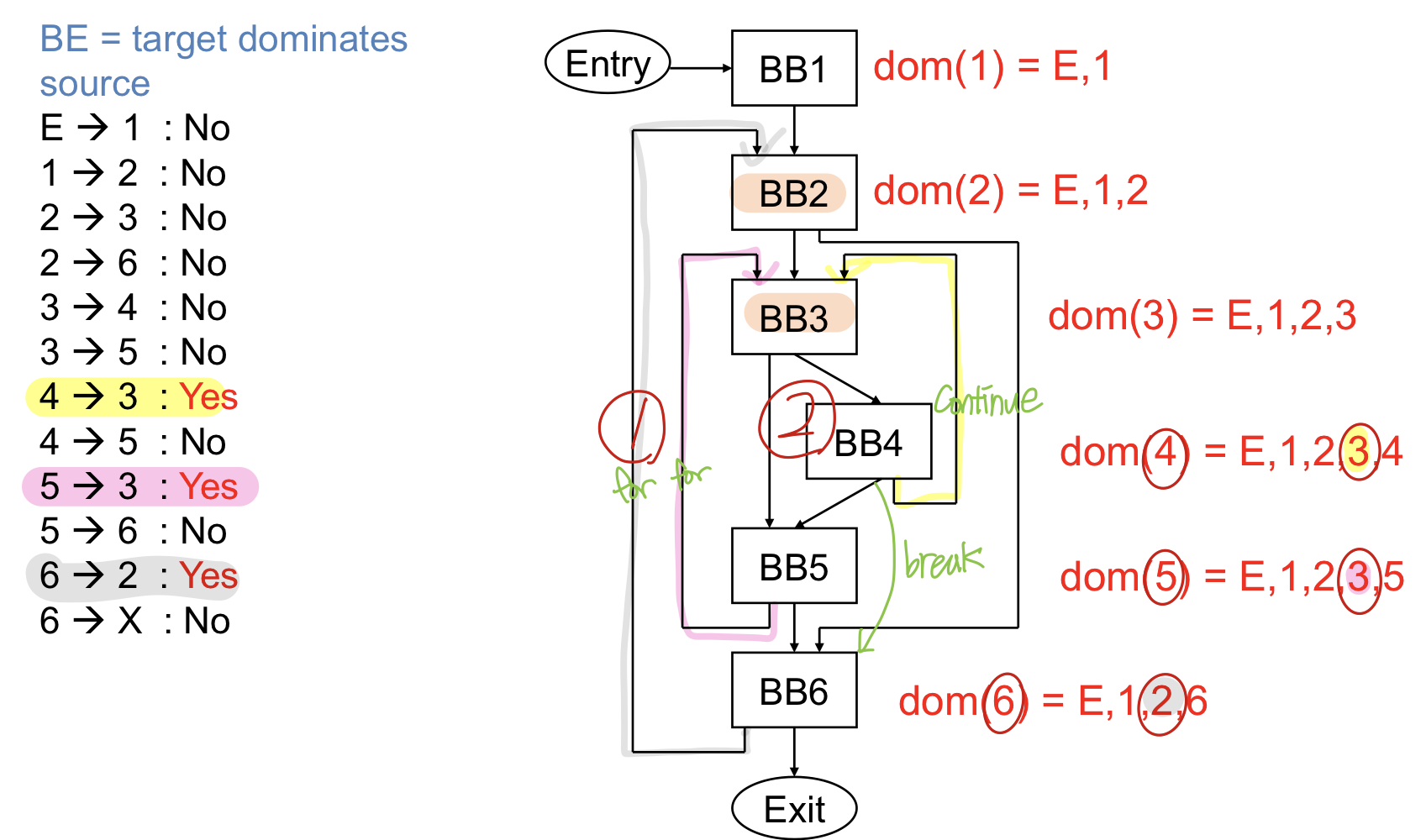
💯Loop Detection(매우매우 중요)
- dominace information을 사용하여 모든 backedge를 identify
- 각각의 backedge(x→y) defines loop
- loop header는 backedage target(y)
- LoopBB : loop를 구성하는 basic blocks들의 set, backedge에서 y→x로 갈 수 있는 모든 bb
- All predecessor blocks of x for which control can reach x without going through y are in the loop
- 같은 헤더를 가지는 loop는 합친다
- loopbackedge = loopbackedge1 + loopbackedge2
- loopBB = loopBB1 + loopBB2
ex) for문 내의 continue가 있어도 하나의 loop
- important property
- header dominates all loopBB
- 루프 안에 있는 임의의 bb를 실행하면 무조건 헤더를 거쳐와야 한다
Important parts of a loop
- header(backedge의 target), loopBB (loop를 구성하는 모든 블럭들)
- backedges(x→y, dom(x)=y), backedgeBB(backedge가 나가는 블럭)
- exitedges(루프에서 나가는 엣지), exitbb(outgoing edge가 있는 블럭)
- preheader(preloop)
- header전에 fall through되는 새로운 블럭
- loop를 시작할 떄 무조건 preheader가 실행
- iterate하는 동안에는 preheader는 실행되지 않음
- all edge entering header
- backedges - no change, 다른 edge - retarget to preheader
- postheader(postloop)- exit bb뒤에 있는 블럭
헤더는 preheader에서 나오는 엣지와 backedge를 가질 수 있음
Loop의 특성
1)nesting
루프가 중첩될 떄 가장 안에 있는 루프를 inner loop, 가장 밖에 있는 루프를 outer loop라고 하며 nesting depth로 얼마나 중첩되는지를 알 수 있다
가장 안에 있는 루프를 inermost loop라고 한다
2)trip count(average trip count)
- 얼마나 평균적으로 loop iterate를 시행하는가?
-
average trip count = weight(header) / weight(preheader)
=header로 들어오는 모든 weight / preheader에서 weight로 들어오는 값
preheader는 반복 맨 첨에만 시행되고 header는 매번 시행되므로 시행된 수로 나눠서 구할 수 있기 떄문
주로 평균을 말하며 루프가 한번 invoke될 때 몇 번 루프가 시행되는지를 찾는 것, 루프가 몇번이나 시행되는지를 알아보는 것
Ex)
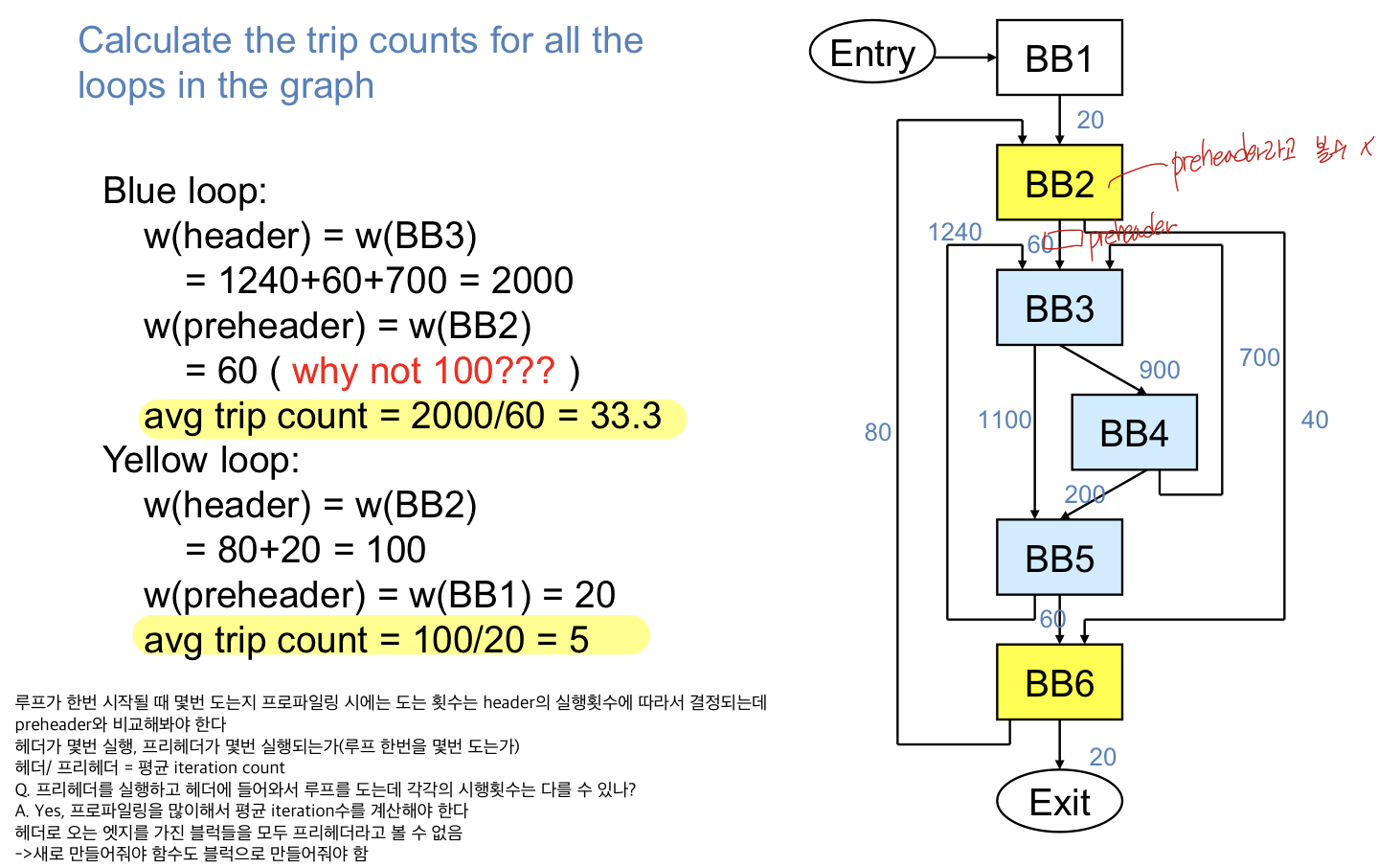
Q. preheader를 통해서 header로 들어와서 루프를 돌 떄 각각의 수행횟수는 다를 수 있나?
A. yes, 프로파일링으로 평균을 구한다
loop induction variable
I=i+1;처럼 loop의 iteration을 관장하는 제어하는 변수를 말함.
- induction variable : 이러한 변수는 루프가 돌 때마다 매번 값이 바뀌고 그중에서 상수값으로 증가하거나 감소하는 변수를 말함
- basic induciton varaible : induction varaible 중에서 j=h+/- c(상수)형태인 변수
- primary induction variable : Basic 중에서 실제로 루프에 execution을 실제로 관장하는 변수를 primary라고 한다
- derived induction variable : Basic induction variable의 linear function으로 만들어지는 변수를 의미
→ 루프에 따라서 상수로 변하면 induction, 그 중에서 자기자신의 값이 바뀌면 basic induction, 그 중에서 루프의 executation을 컨트롤하면 primary induciton, basic의 linear function으로 표현되면 derived induction
Ex) basic = i++
Derived = j = i*2;
backedge coalescing example
Ex)
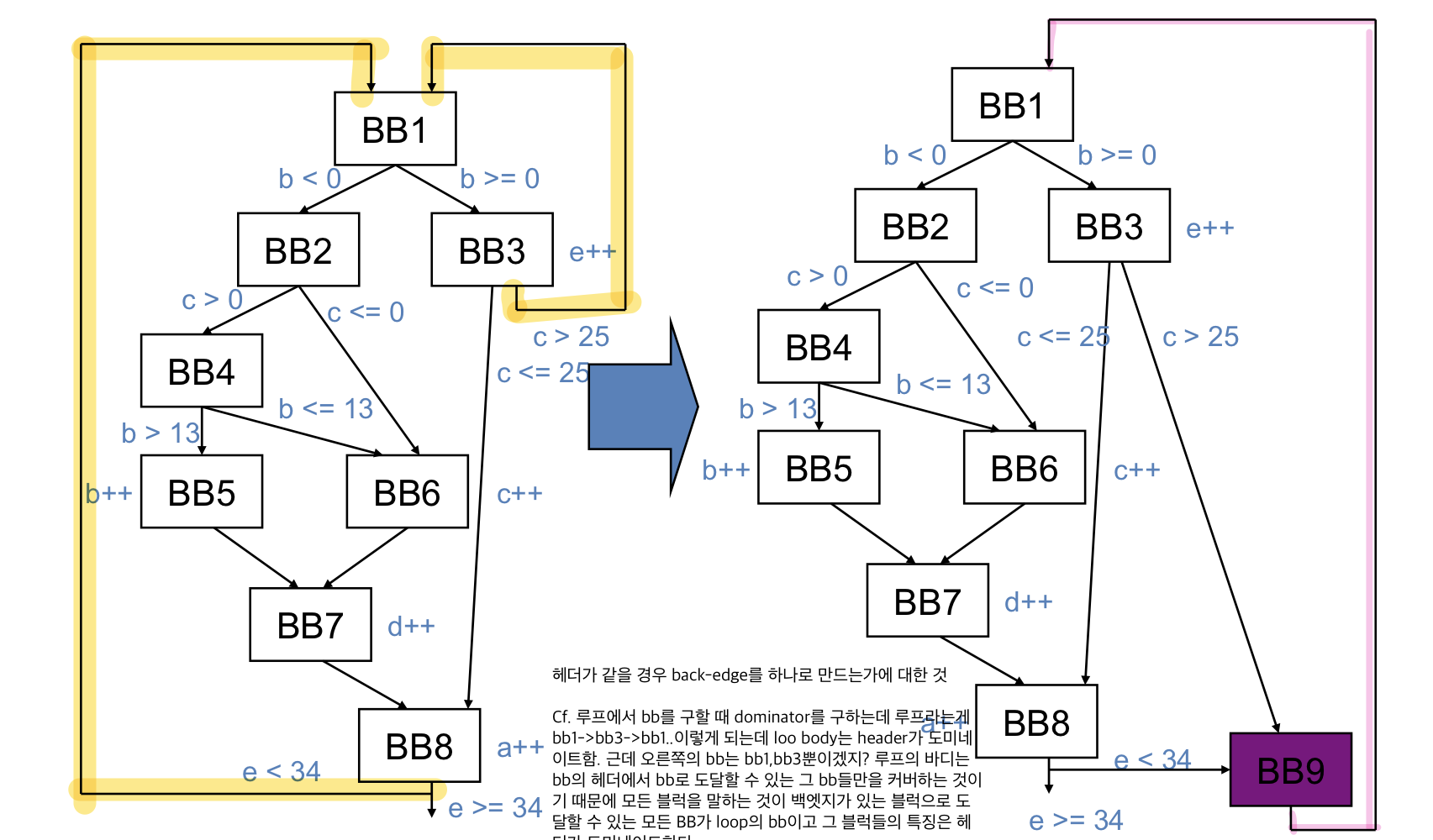
어떠한 두개의 backedge가 있고 하나의 헤더라면 하나의 루프로 만들 때 하나의 backedge로 합칠 수 있고 이 과정을 backedge coalescing이라고 한다
하나의 bb를 새로 만들어서 언제나 가게 해서 하나의 backedge를 만들어주면 하나의 큰 루프로 만들어 줄 수 있다