Loop Unrolling,루프를 펼친다
- 가장 많이 알려져 있음
- 루프에 있는 바디, 루프안에 있는 bb를 n-1번 복사해서 n개로 만들어서 Iteration count를 1/n으로 만드는 것
- loop unrolled n times , nx unrolled
- 다른 iteration에서 사용하는 operation을 합칠 수 있음
- ILP를 증가시킴
기본적으로 컴파일러에서 최적화는 bb안에 instruction 수가 많을 수록 성능이 좋아지는데 두배로 늘리게 된다면 최적화될 수 있는 여지가 많아지고 cpu에서 구동 시 좀 더 빠르게 병렬화를 이용해서 병렬적으로 수행할 수 있어서 속도가 빨라질 수 있다. Branch가 성능 저하의 요인인데 50번만 branch를 수행하면 되니까 된다.
→ bb 두개가 사실은 하나의 Bb가 되어서 Instruction 수를 늘리고 바디를 키우고iteration count를 줄인다
ex) 어떠한 BB가 있다면 이게 100번 수행된다면 동일한걸 한번 더 만들어서 50번 돌도록 바꾸는 작업을 의미
- 세가지 종류
- unroll multiple of know trip count(언제 끝나는지 알고 파라미터 값을 알고 있을 경우)
-
unroll with remainder loop(언제 끝나는지는 알고 몇개의 파라미터를 모르는 경우)
ex) 123번 도는데 4의 배수로 나눠떨어지지 않는 경우
- while loop unroll(언제 끝나는지 모르는 경우, while에서 조건이 끝나면 나가는 경우)
(장점)
- trip count가 줄어서 좋음 브랜치가 많으면 pipelined processor에서는 성능이 낮아진다. Loop unrolling하면 브랜치를 실행하는 횟수가 줄어들기 때문에 성능이 더 조아짐.(branch instruction 실행 수가 줄어들어서 좋다)
- loop body(basic block)가 커져서 좋은 것 어떠한 프로세서가 한사이클에 4개의 instruction을 동시에 수행하려면 얘네들 사이에 data dependency가 없어야 한다.기본적으로 루프 바디는 작기 때문에 큰 사이클에 여러개 Instruction을 수행할 수 있을 때. Bb단위로 최적화를 하면 instruction 수가 작기 때문에 동시에 도는 Instruction이 적음. 하지만 bb가 크면 potential하게 instructions 수가 늘어난다, Preprocessor정도의 역할이 unrolling임 하드웨어어에서 동작시킬 때 동시에 시행하도록 instruction의 조합을 만들 때 instruction이 많으면 좋으니까 추후의 최적화효과를 위해서 수행하는 것, gcc를 봐서도 무조건 loop unrolling을 할 수 있으면 하는 경우가 많음
Q. N을 n/2로 줄였는데 브랜치를 줄이고 싶으면 n/n으로 하면 되는데 안하는 이유?? 프로그램의 크기가 커지는 것도 있지만 두가지 문제가 존재
- lop unrolling을 할 수 있는 경우도 있고 아닌 루프도 있는데(얼마나 iterate할지 모를 경우, iteration count가 input에따라서 달라질 경우, 3의 배수인지 4의 배수인지 모르기 때문에 쉽지 않음)
Unrolling code 코드를 보면 루프 unrolling을 할까말까를 고민많이 함. 최적화가 있으면 gcc나 llvm이나 딥러닝 컴파일러에서 보면 최적화 기법이 많은데 어떻게 적용하나도 재밌지만 최적화를 적용할까말까 할 수 있을까를 고민하는 과정이 무조건 존재,
- 너무 많아지면 서치스페이스 조합이 너무 커져서 가장 좋은 순서가 있는데 그걸 찾기가 어려움. 퀄리티가 좋아지지 않음. 백만개이면 최적의 경로를 찾지 못하기 때문
- Instruction들이 많아진다면 레지스터를 많이 사용한다는 의미가 됨 레지스터는 몇개 없는데 그중에서 4,5개는 프로그램 핸들링을 위해서 사용(pc,return, sp,fp) 근데 프로그램이 너무 길어서 레지스터를 20개정도를 사용해야 한다면 중간에 레지스터가 부조거해서 레지스터를 쓰려고 경쟁하다가 밀린 애들이 메모리로 가면서 느려지게 된다
type 2
몇번 도는지 알고 모든 파라미터 값을 알고 있는 경우
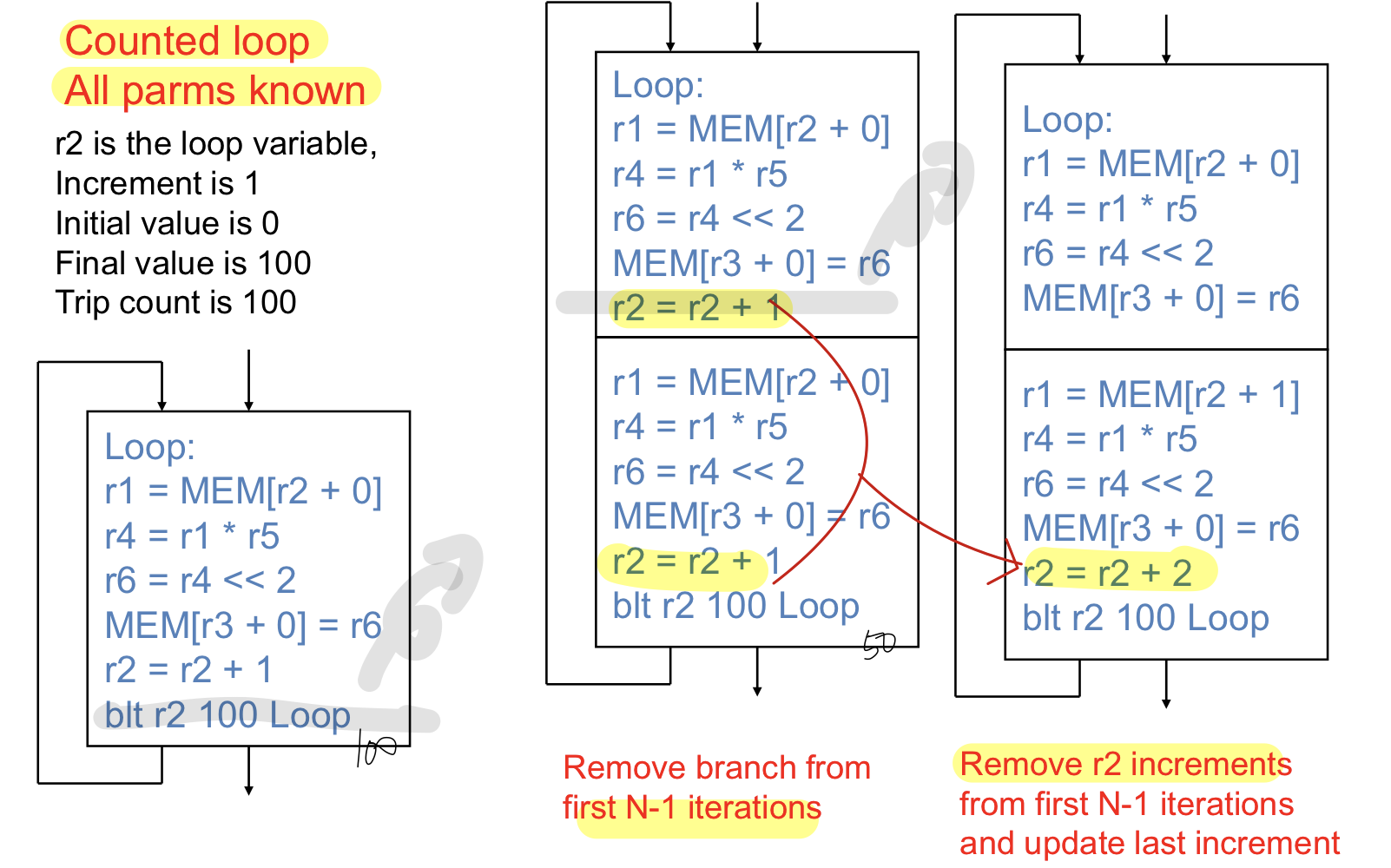
bb가 bb2 → bb2 -2(branch + induction varaible)
- insstruciton 개수도 둘고 Pipeline으로 돌리면 branch miss penalty가 줄어들어서 더 효과적
루프 바디를 복사하고 branch를 없애준다. R2가 두개인데 한개로 합친다
Type 2
-
몇번 도는지는 알지만 파라미터는 모르는 경우, 컴파일타임에는 모르고 런타임에 알게 되는 경우
Increment x가 먼지를 모르는 것, r2가 얼마나 되어야 y가 Final value가 얼마인지를 몰라서 trip count를 알수가 없음.
-
trip count를 모를 수 있기 떄문에 나머지를 돌리는 루프와 배수를 돌리는 루프가 필요
→ Remainloop를 만들고 나머지 부분을 unrolling.
-
factor들이 언제 결정될지 모르는 경우 해결할 수 있도록 한다
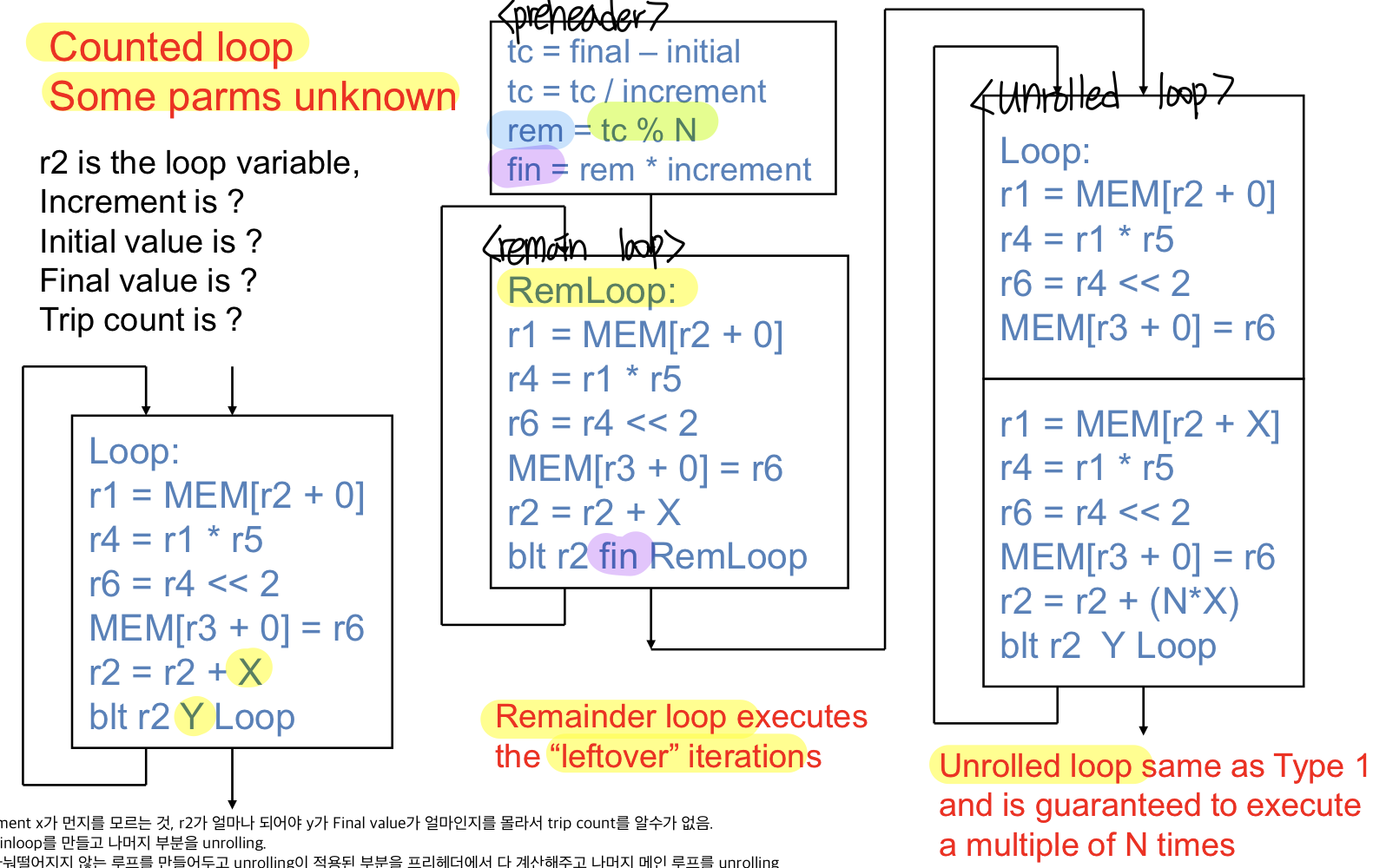
2로 나눠떨어지지 않는 루프를 만들어두고 unrolling이 적용된 부분을 프리헤더에서 다 계산해주고 나머지 메인 루프를 unrolling
Type 3
While 문처럼 몇번 도는지 모르고 파라미터도 알 수 없는 경우
- 기본적으로는 똑같은 루프 바디를 복사하고 중간에 condition이 맞지 않으면 나갈 수 있도록 한다
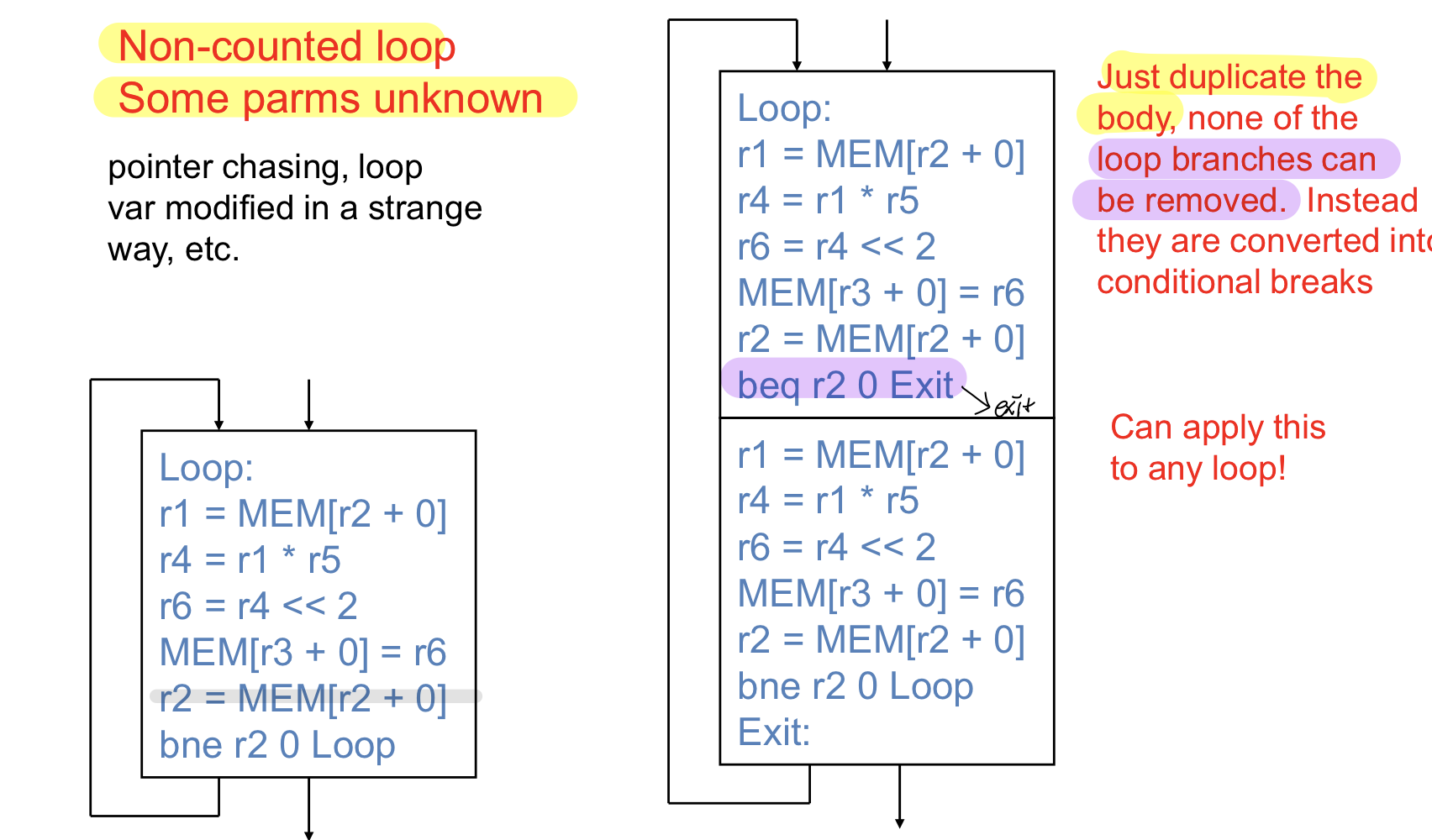
Q,실제로 성능적으로 효과가 있는가?
A. 성능효과가 크게는 없지만 그래도 그 안에서 최적화를 시킬 수 있으므로 수행할 수 있다, 기본적으로는 없지만 내가 보는 scope를 늘리는 의미에서 의미가 있음
코드가 왼쪽처럼 있는 것보다 코드를 키우고 bb를 두개로 만든다면 bb안에서 모든 최적화를 적용할 수는 없지만 여기서도 적용가능한 최적화가 있기 때문에 의미가 없지는 않다.
- 브랜치를 줄인다. 여러개 iteration이 있을 떄 overlapping한다. 동시에 구동시킬 수 있는 의미가 있다
- Data가 흘러가는 것을 보고 최적화를 할 때 bb하나만 볼 수도 여러개를 볼 수도 있는데 기본적으로 코드가 좀 더 있어야하기 때문에 의미가 있다라고 볼 수 있음
(정리)
- 1> 2> 3정도로 효과가 좋은 편
- 기본적으로는 instruction 수가 많아졌기 때문에 효과는 있음, 브랜치 수를 줄일 수 있으므로 성능을 높일 수 있음
- 여러개의 iteration을 하나의 바디에 쓰니까 좀 더 성능이 좋아질 수 있음
-
Type1이 가장 효과적임. Branch와 코드 다 날라갈 수 있고 큰 bb가 하나 생겼으니까 !! 하지만 제한적인 loop에만 적용 가능
→ 타입 1은 loop unrolling을 무조건 적용하지만 2,3는 컴파일러가 고민함.
- Type2는 counted loop니까 어느정도 의미가 있고 iteration count가 줄어들고 remainder loop가 추가하지만 대부분의 시간에는 메인루프를 돌기떄문에 괜찮음
- Type 3도 효과적일 수도 있긴 함 제한적으로 최적화 가능, 항상 할 수 있으니까 좋다
Loop unrolling을 볼 떄 프로파일링을 할 수 있음. Average trip count를 모를 떄, 루프에 들어갈 때마다 두번만 실행하면 unrolling할 필요가 없는데 적어도 60번을 돌아야 한다면 4배로 뻥튀기 하는데 의미가 있을 수 있다-> 프로파일링을 많이 해보는 편
Loop Peeling
- P개의 iteration을 추출해서 preheader에 넘겨주고 메인 바디에 iteration count를 줄여주는 방법
→ preheader에 Instruction이 많아지니까 최적화 가능하고 메인 바디에서 나머지 최적화가 가능
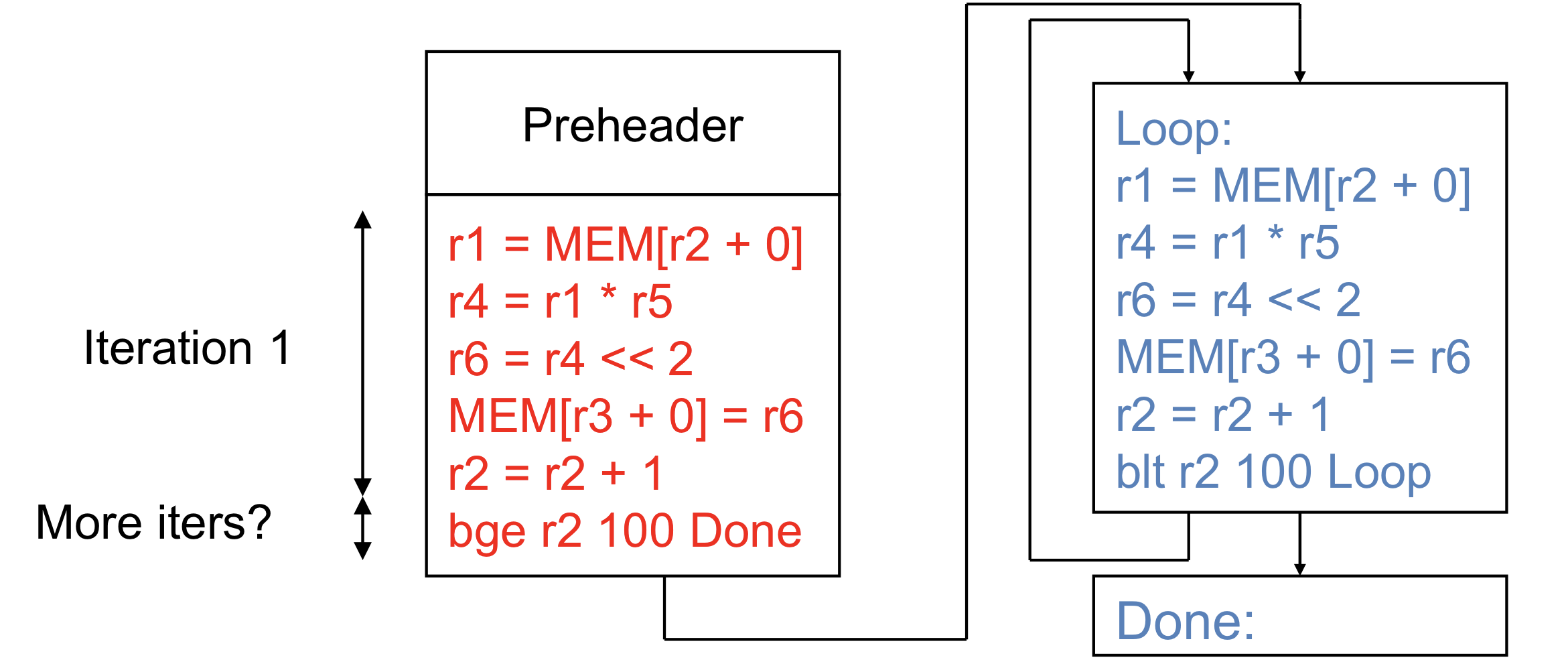
- 생각보다 많이 돌지 않는다면 효과적일 수 있 음
Control flow optimization for acyclic code
지금부터는 루프가 아닌 sequential code의 control flow 최적화에 대해서 알아보자!
목적은 다이나믹 branch 수를 줄이는 것! 그리고 큰 bb로 만드는 것과 코드 사이즈도 줄일 수 있다면 줄일 것
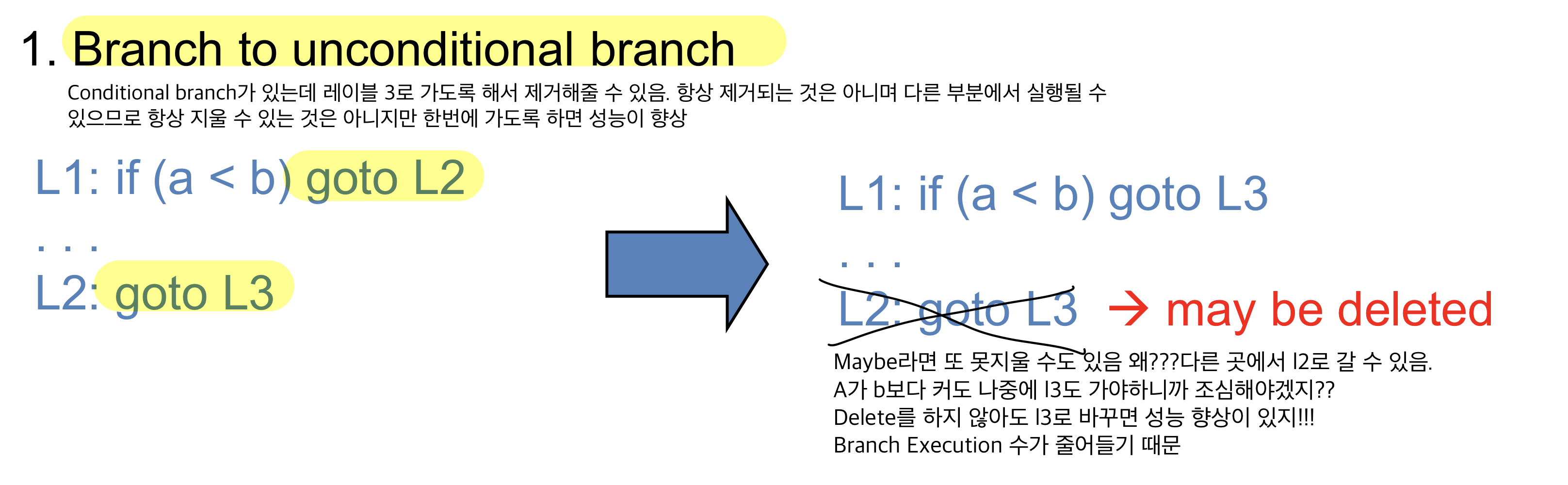
Conditional branch가 있는데 레이블 3로 가도록 해서 제거해줄 수 있음. 항상 제거되는 것은 아니며 다른 부분에서 실행될 수 있으므로 항상 지울 수 있는 것은 아니지만 한번에 가도록 하면 성능이 향상
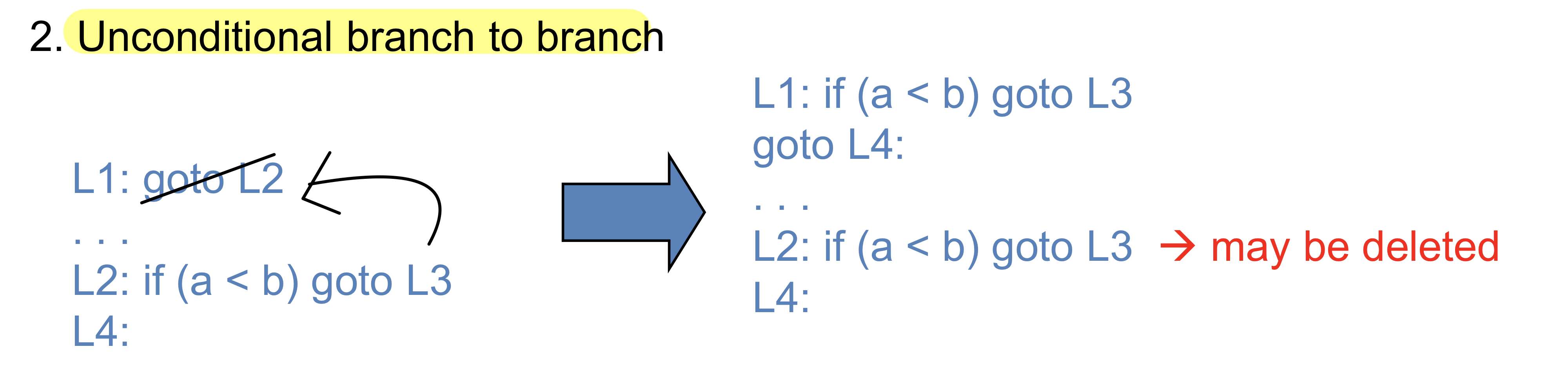
L1에서 l2 코드를 그냥 추가해주면 된다
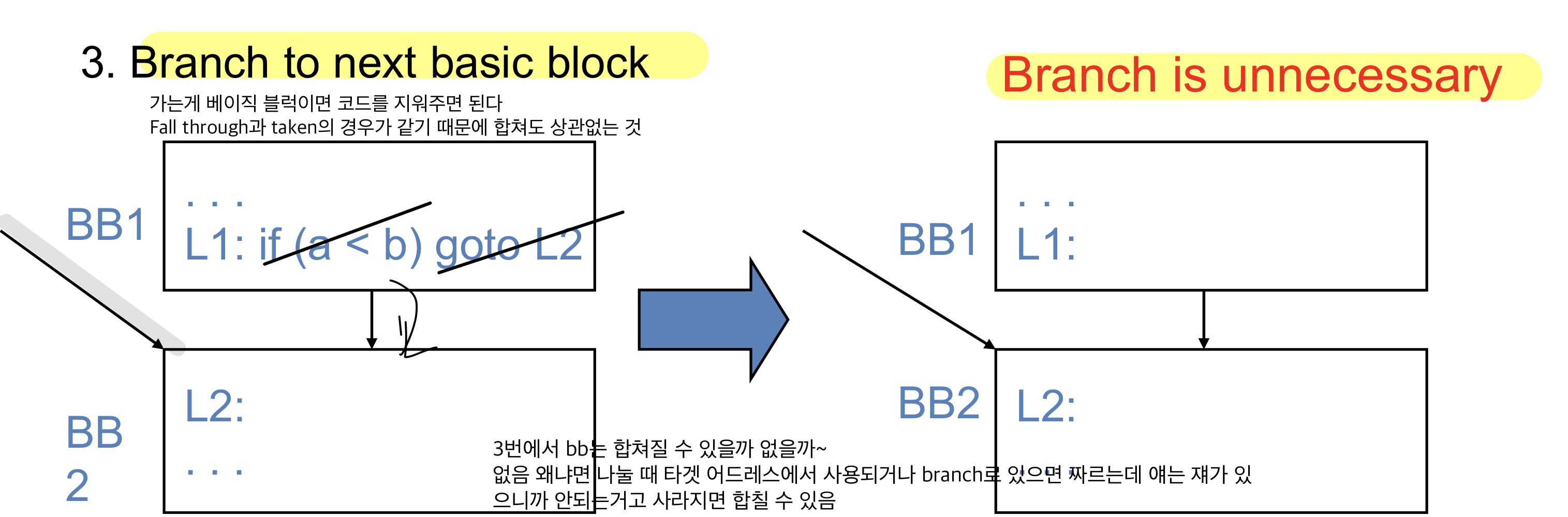
가는게 베이직 블럭이면 코드를 지워주면 된다
bb2가 target address인 곳이 있기 때문에 묶을 순 없다
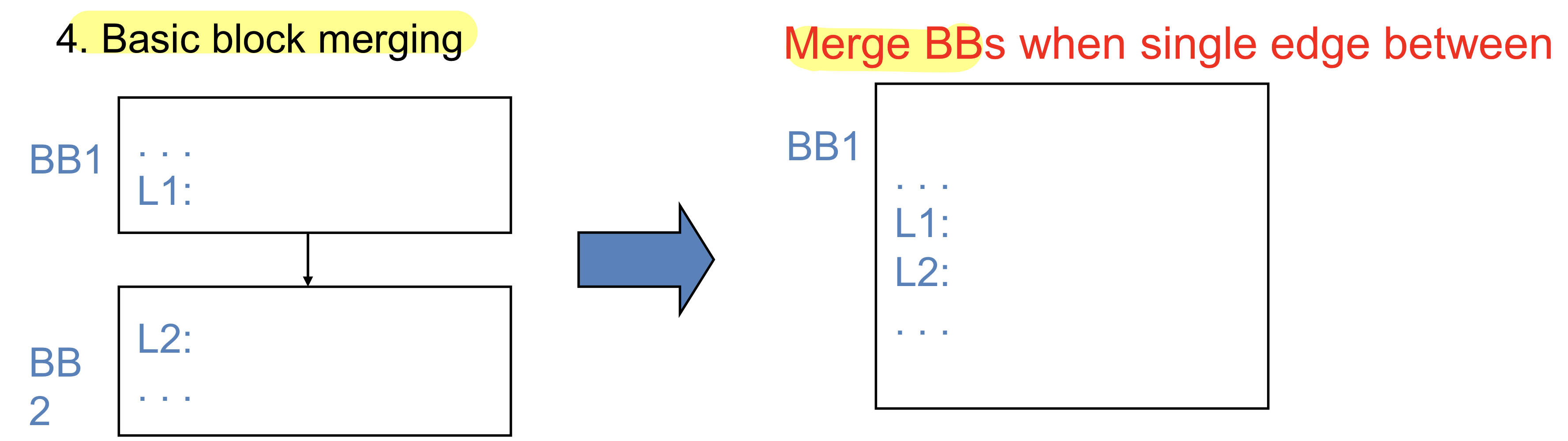
합칠 수도 있다
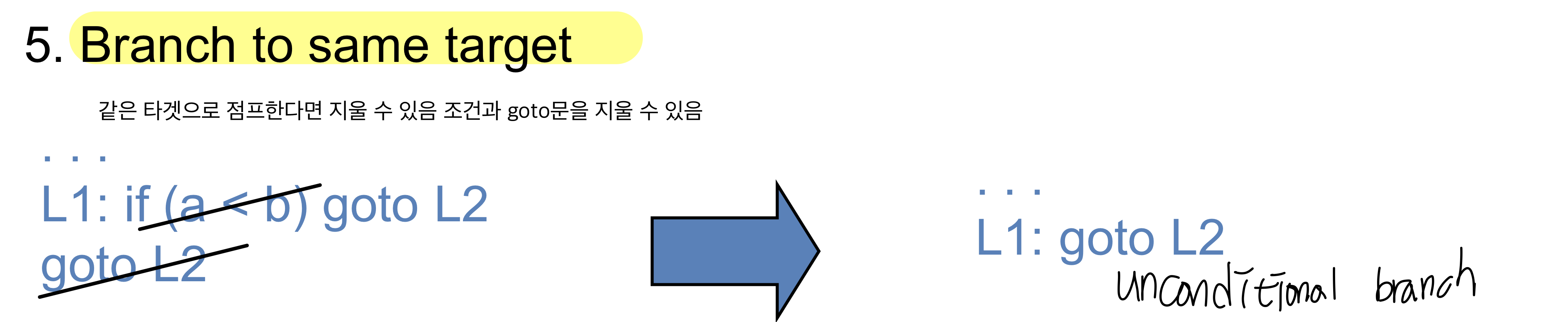
같은 타겟으로 점프한다면 지울 수 있음 조건과 goto문을 지울 수 있음
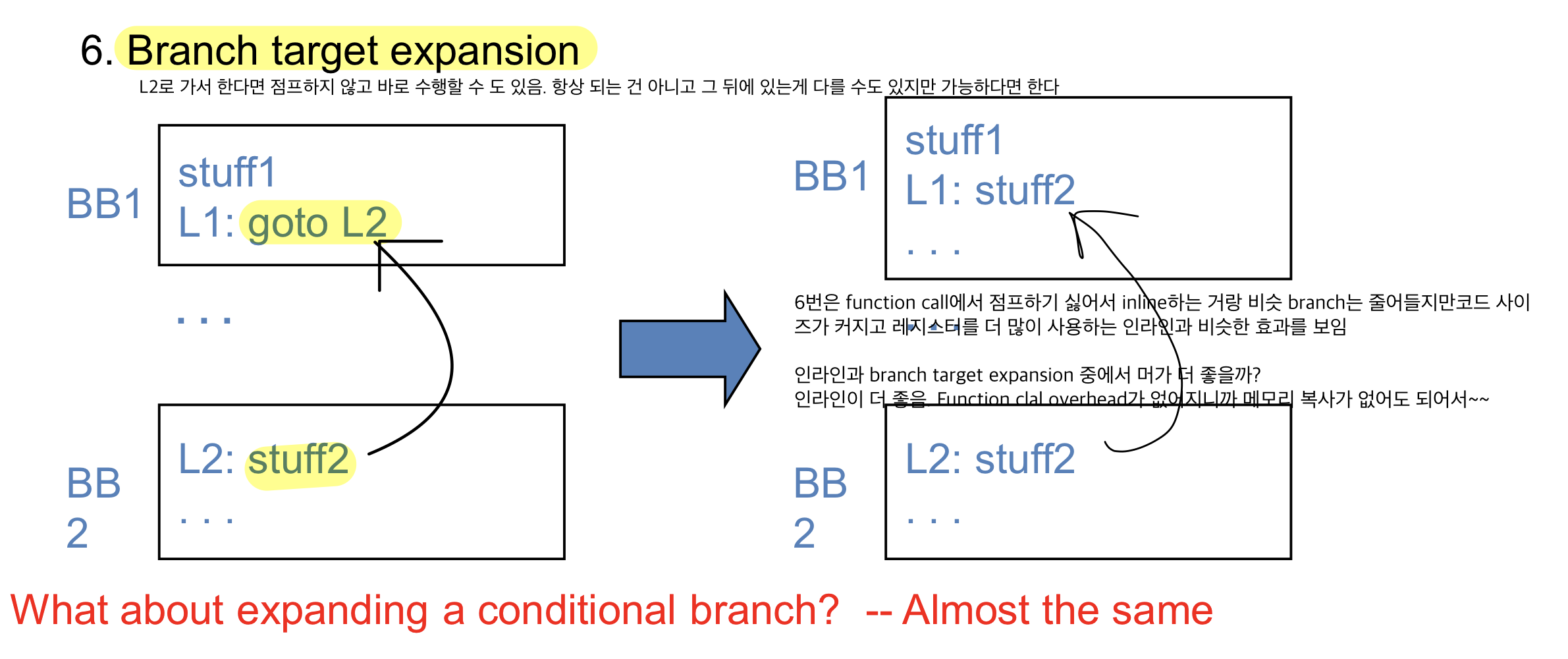
L2로 가서 한다면 점프하지 않고 바로 수행할 수 도 있음. 항상 되는 건 아니고 그 뒤에 있는게 다를 수도 있지만 가능하다면 한다
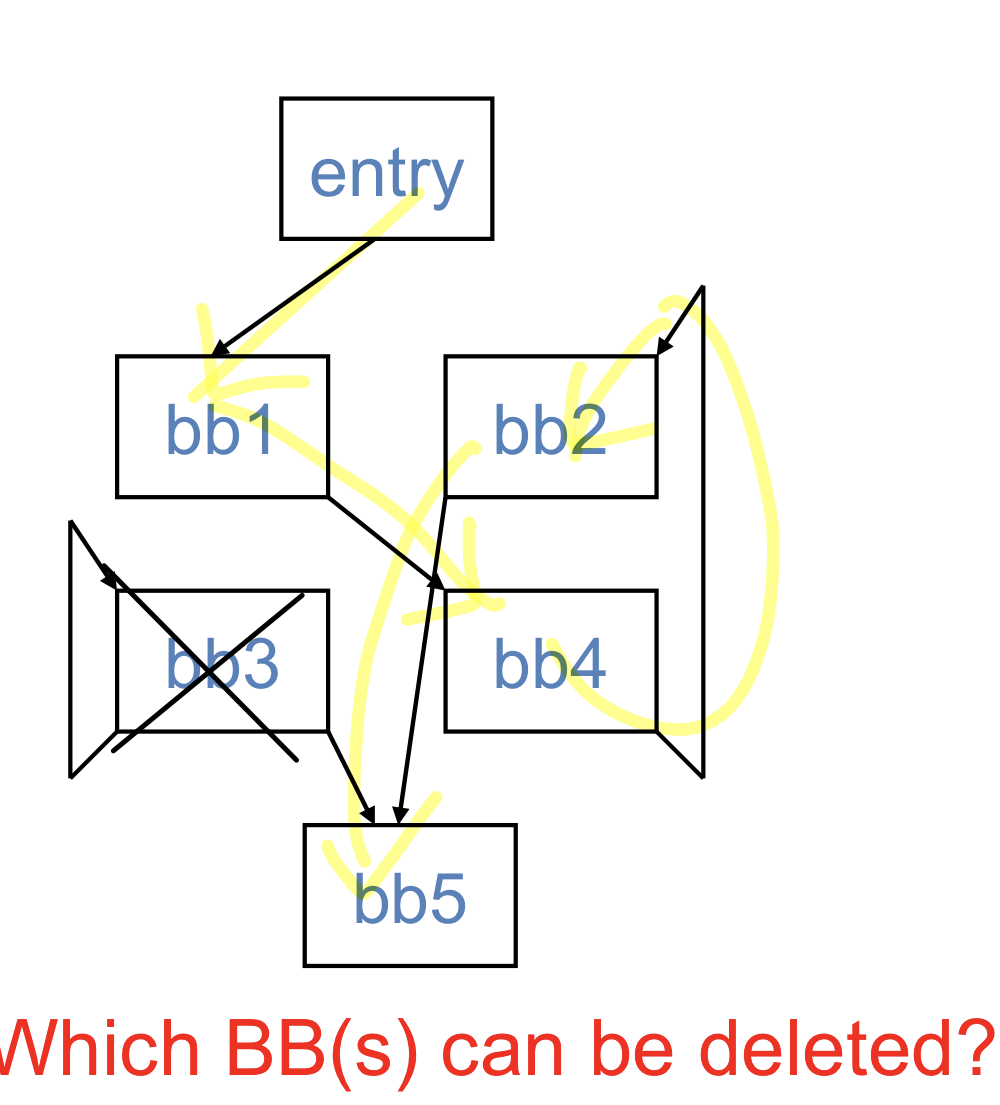
unreachable code eliminiation
절대로 실행되지 않는 코드를 삭제
Profile-based Control Flow Optimization : Trace selection
좀 더 심화된 내용도 있지만 trace selection에 대해서 알아보자
-
Trace : bb의 linear collection, 가장 sequential하게 순차적으로 실행할 것 같은 모임을 말함
대부분의 경우에 실행될 거같은 bb들의 execution flow를 의미
- likely control flow path
- acyclic(outer backedge는 가능)
- side entrance : trace 중간으로 들어오는 엣지
- side exit : trace 중간에 나가는 엣지
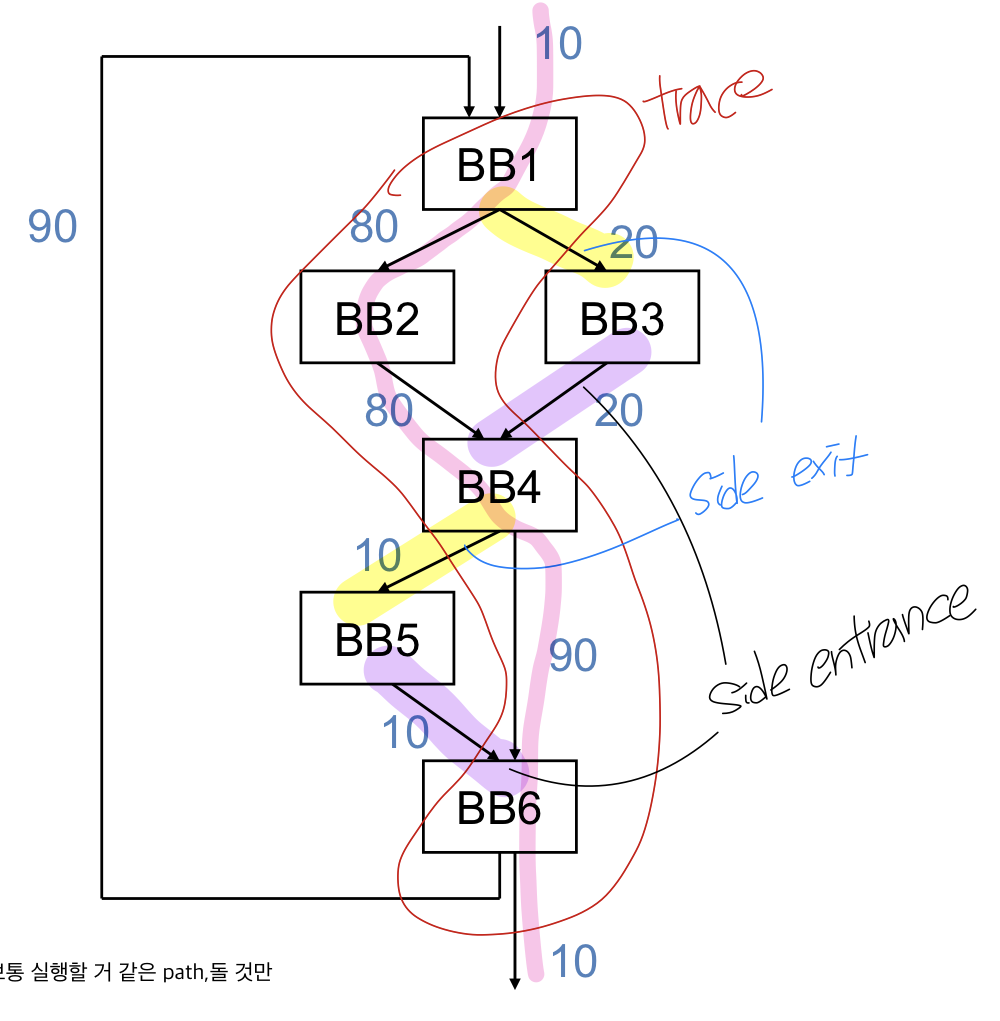
ex) 1,2,4,6이 주로 발생할 것 같다 이걸 trace이고 대부분 여기서 수행될 것
- → Trace를 찾게 되면 trace에 포함된 블럭들은 실행될 확률이 크니까 좀 더 최적화해보자!!, 1246는 35보다는 좀 더 중점적으로 최적화하면 될 거 같다 35가 instruction block이 크면 좀 고려를 해줘야 한다
-
성능이 더 좋아질 것
프로파일링해서 100번 도는데 bb3보다는 bb2로 가는 확률이 높고 bb4로 무조건 가서 bb5는 잘 안가니까 넘어가서 6는 무조건 가서 1246가 trace가 되며 안들어가는 블럭이 35
Linear한 순서로 trace를 잡는데 60퍼이상으로 진행하는 bb만 하고 아니면 끝내자 등의 threshold를 잡아서 함
- side entrance, side exit이 있기 때문에 trace를 하나의 블럭이라고 볼 수 없기에 최적화하기가 어려운 편
cf. Side entrance, exit을 최적화하는 super block, hyper block도 하지 않으니까 그것도 중요하지 않음
Q.Trace를 잡았을 때 얘는 잡아서 성능을 높일 수 있는게 머가 있을까??!?!
A. 실제로 성능이 좋아지는 것은 trace만 가지고는 볼 수 없지만 좀 더 생각을 해보면 좋아질 수 있는 여지가 있음
intelligent trace layout for i cache performance
Trace를 이용해서 I cache performance가 좋아진다
잘 알필요는 없음, 하드웨어와 관련됨
Icache : 코드를 저장하는 임시 메모리
Icache가 있을 때 캐시는 여러개의 캐시 블럭으로 이루어지고 캐시 블럭에 데이터를 넣을 때 시간이 오래걸린다고 가정
Cpu, memory가 있는데 메모리에서 캐시는느리고 캐시에서 cpu는 빨리 걸린다고 생각
캐시 블럭 한개가 bb를 다 저장할 수 없다면 두개의 블럭을 매번 가져와야 하지만 trace를 잡아서 메모리를 다르게 배치한다면 대부분의 경우 하나의 블럭만 가져오게할 수 있다