Control flow는 브랜치와 관련된 분석이고 어떤 코드 블록에서 얼마나 많은 브랜치가 있는지 수행하는 순서가 어떻게되는지를 분석하고 이를 이용해서 bb를 detection하고 그 후에 그 정보를 기본으로 CFG를 만들 수 있게 된다. 이를 통해서 어떻게 실행되고 어떠한 instruction 모임이 같은 Execution 특성을 가지는지 알 수 있고 프로파일링을 통해서 실행되는 빈도를 알 수 있고 그것을 추가하는 것을 dynamic control flow graph라고 함. 이걸로 여러가지 최적화를 수행하는데 여러개의 BB를 하나의 bb로 생각하도록 하고 이를 위해서 trace(빈도수가 높은 bb의 모임), side in-trance를 없애는 게 super block(중간에 새로운 Input이 들어오면 최적화가 어려우니까) super block에서 아예 브랜치를 없애는 것이 hyper block, 큰 basic block처럼 생각할 수 있도록 하는 것이 control flow analysis→ 이 후에 basic block의 사이즈를 크게 만들어놓음( 최적화를 잘 수행하기 위해)
여러개의 instruction을 보고 순서를 바꾸거나 중복되는 instruction을 지워서 성능을 높이고 이를 위해서는 instruction 간의 관계를 알아야 한다. : data flow analysis
프로그램에서 데이터가 어떻게 흘러가는지 표현
첫번째 데이터가 두번째 데이터는 첫번째 데이터에 의해서 나오게 되고 등등… 이런 분석으로 instruction간의 dependency를 알게 되고 이걸로 최적화가 가능
cf.
DU chain : def use, 누가 레지스터를 define하느냐, r5 = 인 거, use는 어딘가에서 +r5이렇게 사용하는 것, Def는 주로 producer라고 하고 use는 consumer라고 함. 위에서 만든 데이터를 밑에서 사용
SSA form : 레지스터들이 나중에 사실 겹침
R5 = ~~
R5=+r5
막 이러면 첫번쨰 r5와 두번째 r5가 다른 값이기 때문, 이름만 겹치지 거의 다르 애, 이러면 스케줄링하기 어렵기 떄문에 새로운 레지스터를 정의할 때는 무조건 지금까지 사용하지 않는 애로 선언한다. 심하면 레지스터가 1000까지 올 수 있음
너무 신경쓰지 않아도 됨
LLVM는 회사에서 커스터마이즈할 때 사용, 레지스터를 증가하는 방향으로 만드는게 ssa form
Looking inside the basic blocks : data flow anlaysis + optimization
Data flow analysis를 수행한 후에 이 데이터로 최적화를 수행
- control flow analysis
- bb를 하나의 black box로 생각
- branch만 고려
- now
- bb안에 있는 op, 실제 instruction를 관찰
- 어떤게 계산되는지 어디서 계산되는지(what, where고려)
- classical optimizations
- data flow analysis를 이용하여 computation을 좀 더 효율적으로 수행
CSE(common subexpression elimination)
Instruction을 관찰하게 되고 operation이 잘나오는데 CSE라는 컴파일러 최적화 테크닉에 대해서 알아볼 것
Subexpression- 계산의 일부
R1= r2+r3
R4= r2+r3 → r1
R5= r2+r3 → r1
덧셈을 많이 하게 되면 똑같은 덧셈을 사용하면 alu를 계속 사용하니까 r4=r1, r5=r1으로 바꿀 수 있음.-> 원래 코드는 덧셈을 세번했지만 r1으로 대체해서 덧셈을 한번으로 바꿈, 여기서의 subexpression은 R2+r3 → 중복되는 r2+r3 instruction 두개를 지워주는 작업 : CSE
- 좋지만 항상 되는 것은 아님 : 중간에 r2값이 바뀌면 r4식을 바꾸 수 없게 된다. R3,r1값이 바뀌어도 안되므로 중간에 값이 바뀌는지 체크해줘야 함
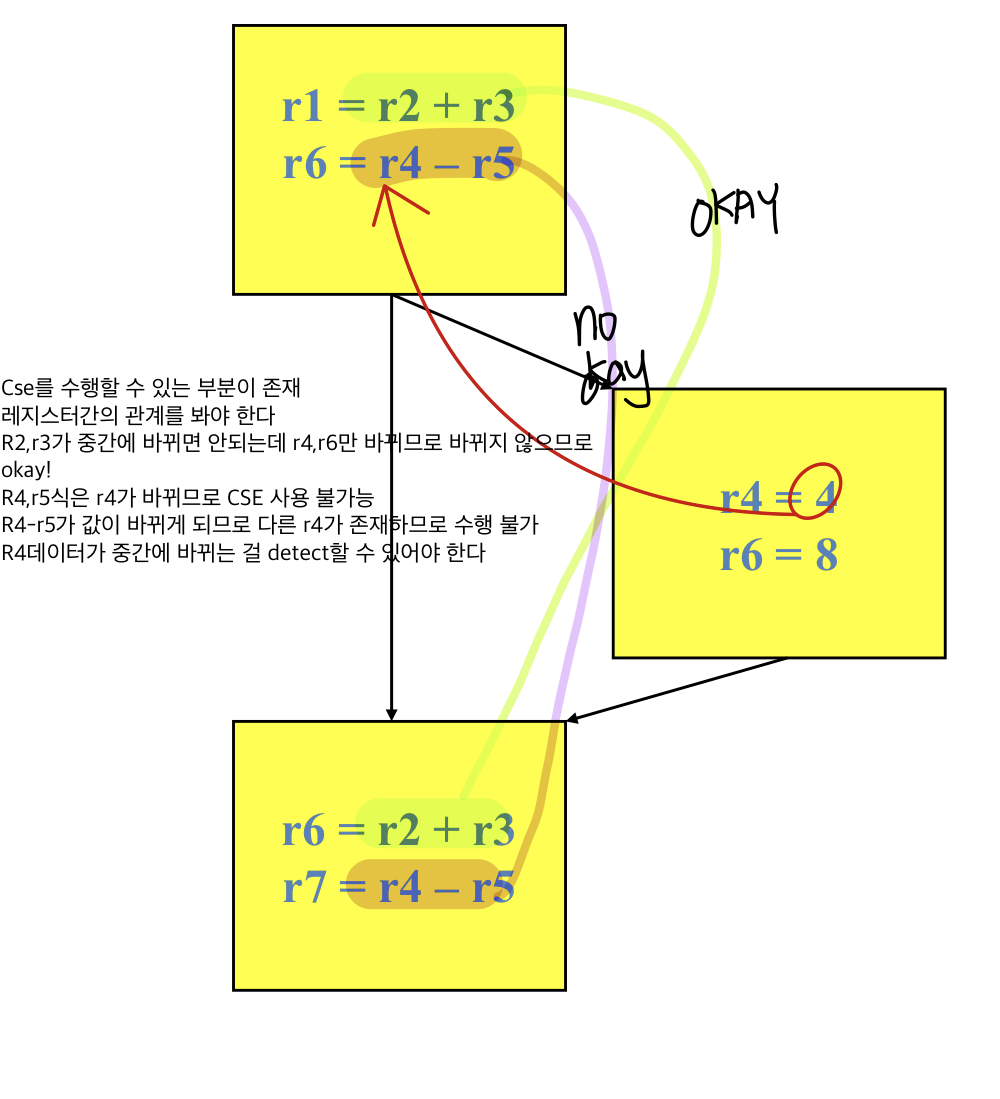
왼쪽의 CFG를 보면 control analysis로 CFG가 나오고 branch는 arrow로 다 대체된 상태
Cse를 수행할 수 있는 부분이 존재, r1+r3, r4-r5
레지스터간의 관계를 봐야 한다
- R2,r3가 중간에 바뀌면 안되는데 r4,r6만 바뀌므로 바뀌지 않으므로 okay!
- R4,r5식은 r4가 바뀌므로 다른 r4가 생기므로 CSE 사용 불가능
→ R4데이터가 중간에 바뀌는 걸 detect할 수 있어야 한다
dataflow anlaysis introduction
Dataflow analysis – Collection of information that summarizes the creation/destruction of values in a program. Used to identify legal optimization opportunities.
- dataflow anlaysis에는 여러가지 종류가 존재하는데 데이터가 언제 생기고 언제 없어지는가, 이것에 집중
- 다양한 종류가 있고 데이터의 creation, destruction 조건을 잘 지정해야 올바른 data flow analysis를 할 수 있게 된다.
1) dataflow anlaysis의 주체가 무엇이냐? 어떠한 데이터를 볼 것인가? : 레지스터값, 각각의 instruction값, 언제 사용되고 죽는지를 볼 수 있음.
→ 어떠한 데이터를 볼 것인가
2) 언제 생기고 언제 없어지는가?의 정의가 필요
3) 데이터가 여러개의 path로 들어올 떄 서로다른 데이터가 path로 들어올 수 있을 때 데이터가 다르니까 없애야 하는가, 아니면 모든 path로 들어오니까 있다고 해야하는가? 데이터의 생성과 삭제의 조건을 잘 결정해줘야 한다

4가지 경우가 있음. 레지스터를 볼 것인가 definition(instruction)을 볼 것인가? 똑같은 vlaue를 볼 때 어떤 point에서 데이터가 올 수 있는가 guaranted to reach 할 수 있는가? : creation / destruction condition을 체크, 두 개 중에 하나만 오면 오케이인지 둘다 와야 오케이인지
data를 creation, destruction condtion 조건을 잘 생각해서 서로 다른 data flow analysis를 수행
Live variable(Liveness) anlaysis
-
defn :각 프로그램의 point p와 variable y에서 y가 p에서 시작하여 재정의되기 전에 y를 사용할 수 있는가?
바로 앞에서 새로 define되지 않아서 원래 사용되던 변수가 계속 사용될 수 있는지 체크하는 것을 말함
-
알고리즘
여러개의 변수가 있을 떄 p에서 사용될 수 있는제 체크하기 위해서 알고리즘을 사용함
- 각각의 bb에서 y는 bb에서 정의되기 전에 사용하거나 bb를 나갈 때 live한 형태로 나간다 : y가 사용되거나 define되지 않고 나가면 Live
- backward dataflow anlaysis는 use에서 defs로 전파, 마지막 use에서 내가 define하는 것을 아래에서 위까지 찾으면 그 사이, 언제부터 언제까지 살아있는지 체크 가능
-
4 sets : Liveness analysis를 위해서 네가지 새로운 용어를 이용해서 각 변수의 liveness를 판단

Gen – 어떤 변수인데 bb에서 이용될 변수, bb에서 새로 생겨나는 변수, 이용되는 변수
Kill – b에서 사라지는 변수, bb에서 없어지는 변수들을 의미, 새로 define되는 것을 의미
Kiil은 bb에서 새로 define된 변수로 더 이상 위로 올라갈 수 없으므로 Kill
In/out은 out은 바깥으로 나가는 부분, in은 들어오는 부분을 의미
→ Out은 exit point, 뒤에 있는 b에서 올라오는 livable 변수의 모임이고 In은 bb에서 out에서 지정된 아이들과 bb안에서 새로 생겨난 아이들을 합쳐서 bb위로 올라간 livable 변수의 합을 의미
⇒ 이 네가지 변수로 Life time을 지정, 여러개의 bb를 넘어들면서 체크, 어떠한 변수가 언제 생겨서 언제까지 살아있는지를 4가지 변수로 체크해주는 것을 의미
Computing GEN-KILL sets for each BB
4가지 변수를 찾을려면 bb에서 먼가 사용되면 gen(새로 생긴 것)이고 어디선지 모르지만 define되어서 사용된 것이고 kill은 define되는 것(어떻게 사용되었는지는 모르겠지만 위에 있는 z와는 다르니 올라가면 안된다!), 아래에서부터 보고 define부터 찾게 되고 define되면 kill, 사용하면 gen

찾기 위해 각각의 bb이 있을 때 Bb안에 모든 instruction을 뒤에서부터 위로 체크, define부터 보기로 했으니까 destination operand를 먼저 본 후 source 를 본다
Define이 된다는 것은 위와 아래의 변수가 다르므로 kil에 넣어주고 gen에 들어있다면 빼는 작업을 수행
→ Source를 봐서 데이터가 쓰이면 사용되니까 gen에 넣고 kill에서는 뺴주는 작업을 수행해서 bb의 gen, kill set을 만들어보자
Compute IN/OUT sets for all BBs
- 하나의 bb에서 gen,kill set을 만들어야 하는데 gen set은 위에 있는 bb로 이어질 수 있는 변수의 모임임(use, = y), kill set은 위로 올라가고 있는 것을 막는 set(define,y = )
- 어떤 변수가 bb 밖에서 아래에서 생긴다고 한다면 x가 사용되면 올라올 것인데 bb에서 kill이 된다고 한다면 얘는 올라갈 수 없게 된다. 아래의 bb에서 live하다고 올라오는 변수 중에서 Kill된 애들은 위로 가지 못하게 되고 새로 사용된 애들은 추가되어서 위로 올라갈 수 있다
→ 밑으로 내려가는 것을 Out, 위로 올라가는 set은 in
Out - 밑에서 올라오는 live variable
In – 아래에서 올라온 애들중에서 kill은 뺴고 gen은 추가한 애들

- 각각의 bb에서 out set은 나의 뒤에 있었던 아이들의 in set의 교집합이고 그 중에서 실제로 bb에서 사라져야 하는 애들을 빼고 gen으로 추가된 애들을 in이라고 한다.
- union의 의미, 합집합 : bb이 밑으로 내려갈 때 y가 여러개 있을 수 있는데 여기서 x가 올라오고 y가 올라온다면 x,y가 모두 존재함을 알 수 있음
- 다른 종류의 data anlaysis를 볼 경우에는 둘 중 하나에만 있어도 올릴 수 있고 둘 다 있는 경우에만 올리는 경우도 있음. 이건 data-flow analysis 종류에 따라서 다름
- Union의 반대는 intersect(교집합)
→ 두가지 모두 사용할 수 있지만 여기서는 union 사용
ex)
각 블럭의 gen, kill을 만들어야 한다
무슨 블럭부터 보는지는 안에서만 고려하기에 상관없기는 하지만 reverse sequential order이므로 밑에서 보고 보고 dest(kill, 선언)부터 봐야 한다. 순서가 중요
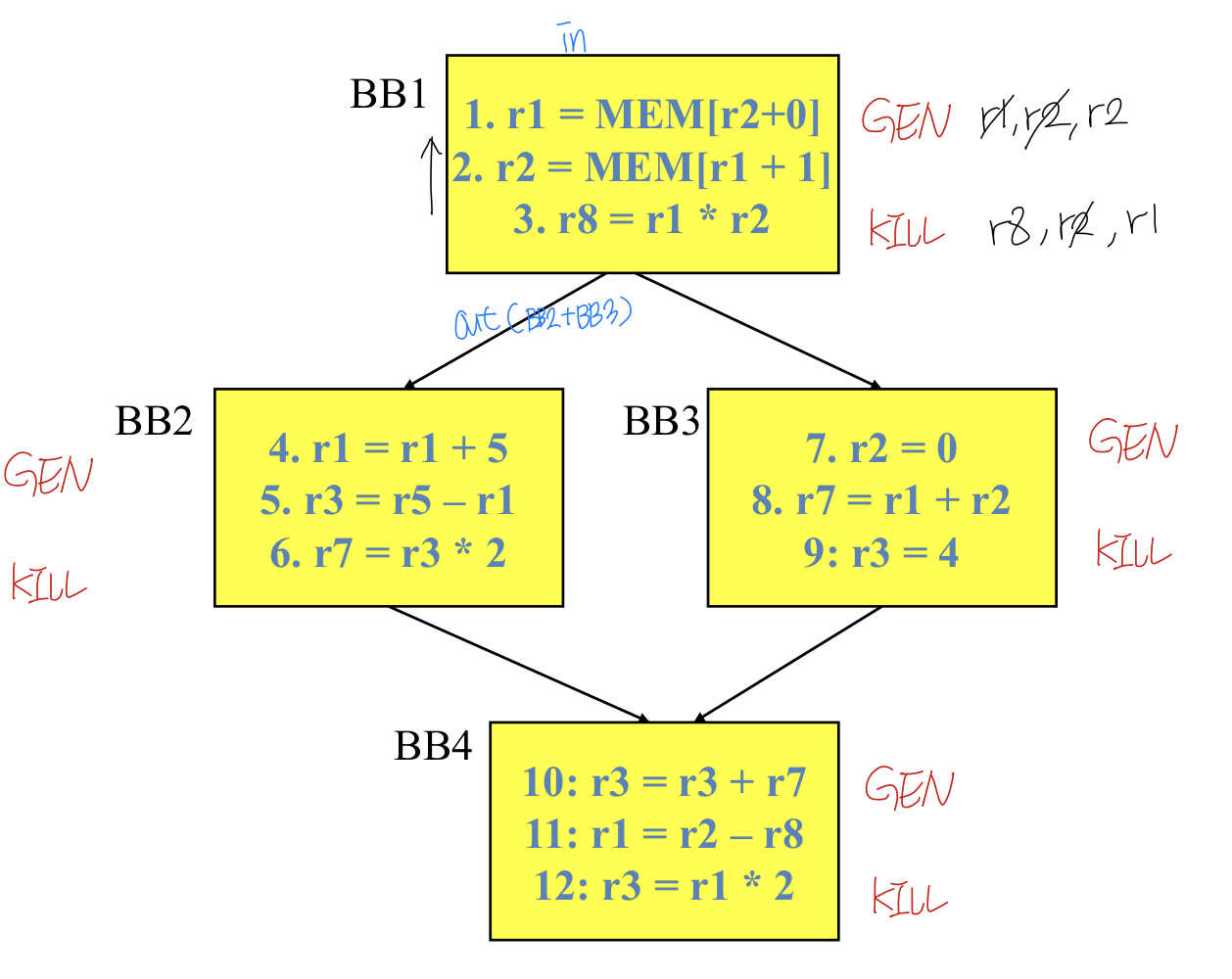
Kill은 bb2,3,4에서 이용될 때 r8은 새로 생기니까 bb1위로는 r8는 올라가지 않는다. R1도 올라가지 않는다
Gen은 r2가 밑에서 올라오든 말든 r2는 무조건 올라온다, R2가 위에서 지정이 되어야 함
gen, kill set을 구한 후 rever로 올라가면서 Out은 union하고 in은 out에서 kill을 없애도 gen을 합치면 구할 수 있다