블록체인, 딥러닝 두가지 토픽의 공통점은 gpu computing을 필요로 함
compute hash of blockchain or traning or inference deep learning model
이거 말고도 다른 분야에서도 gpu가 많이 사용됨
화학식이나 유체역학, 그래픽스, data mining 등등에도 많이 사용됨
functional progrmihnng을 배웠었고 이걸 oop랑 비교했었음
- FP vs OOP
- ML, c++, java, python 등등….
- 지금 배울 거는 바로 CUDA~
- based on c + syntax
- CUDA는 low level이고 하드웨어가 어떻게 동작하는지를 알아야 함
- fp, oop는 high level concept에 대해서 배웠다면 쿠다는 low level
Programing/running environment
- cloud GPU machines
- google colab == jufiter
- your own machine
The CPU(Central Processing Unit)
- 대부분의 application들은 계산 시 CPU를 사용했었음
- general purpose capabilities
- 4~16개의 powerful cores를 가짐
- optimal for concurrent process
- not large scale parallel computation
The GPU(Graphics Processing Unit)
- 비교적 최근의 개념 designed for parallelizable problems
- 처음에는 graphics를 위해 만들어짐
- 그래픽스는 많은 계산이 필요하기에 additional hardware to accelerate computation이였다가 essential이 된…
- became more capable of general compuations
- ai, 머신러닝, 딥러닝 등에 많이 이용됨
- 처음에는 graphics를 위해 만들어짐
GPUs- The motivation
ex) pixel computation, raytracing

raytracing은 각 픽셀마다 ray(광선), traversal, hit surffice를 계산해줘야 함
high resolution이라면 더 많이 계산해야하고 더블로 픽셀 수가 늘어나면 계산량은 4배 늘어남
→ 이 compuation을 parallel로 하려면 각 파트마다 gpu가 하나씩 맡아서 병렬적으로 계산
More examples
- gpu는 그래픽스 말고도 다른 분야에도 요즘 마니 사용되는 편
- cnn, resnet에서도 사용된대
ex)
a,b는 이미 존재하고 c배열을 만들어서 더한다고 가정
CPU(Single-threaded)

- sequential하게 동작하게 되는데 그렇다면 n의 수가 많다면 O(n)이 됨
→ 멀티 스레드를 이용해서 해보자!!
CPU(multi-threaded)

- c배열을 alloc
- thread를 core 수만큼 생성
- 각 스레드마다 addition인데 work를 적당하게 나눠서 넣어줘야 함
- leaping해서 계산하게 하면 됨…
→ 아까보다는 빨라질 거임!! : 아마 core의 수에 따라서 달라지게 될 것
Q. thread수를 그만큼 늘었는데 왜 딱 그만큼 늘지는 않고 좀 더 낮을 거임. 딱 core 수만큼 성능이 좋아지면 개꿀인데 왜그럴까??
A. 메모리에서 데이터를 가져오는데 시간이 오래 걸려서 그럼
누가 바꾸면 모두가 바꾼 정보를 봐야하니까 그것 떄문에도 오래 걸리기도 한다. advance topic
cf. memory hierarchy


A simple problem
- 아까 예시로 다시 돌아와서 multi thread CPU로 돌렸음에도 core수만큼 빨라지지 않았다
- because of fetch memory!
- 다른 cores에서 fetch data를 해서 store the result를 해야하는데 어떤 core는 waiting to get data in cores, 이기에 그만큼 딱 빨라지지는 않음
Context switching
- the action of switching which thread is being processed
- CPU는 context switching에 대해 high penalty 존재
- context switching in cpu에도 오버헤드 존재
- store register in memory and choose thread → fetch register from memory → switch ….
- context switching in cpu에도 오버헤드 존재
- GPU는 not an issue, 상대적으로 값이 적은 편
⇒ 위의 프로그램을 gpu로 해보자!!
CPU VS GPU

cpu
- 많은 트랜지스터들이 있는데 그걸 가지고 캐시, control(add 등등 하는 것), alu 등등으로 구성
- 대부분의 영역이 캐시인 편
gpu
- 캐시의 사이즈가 아주 작은 편. 대부분은 ALU가 많은 편
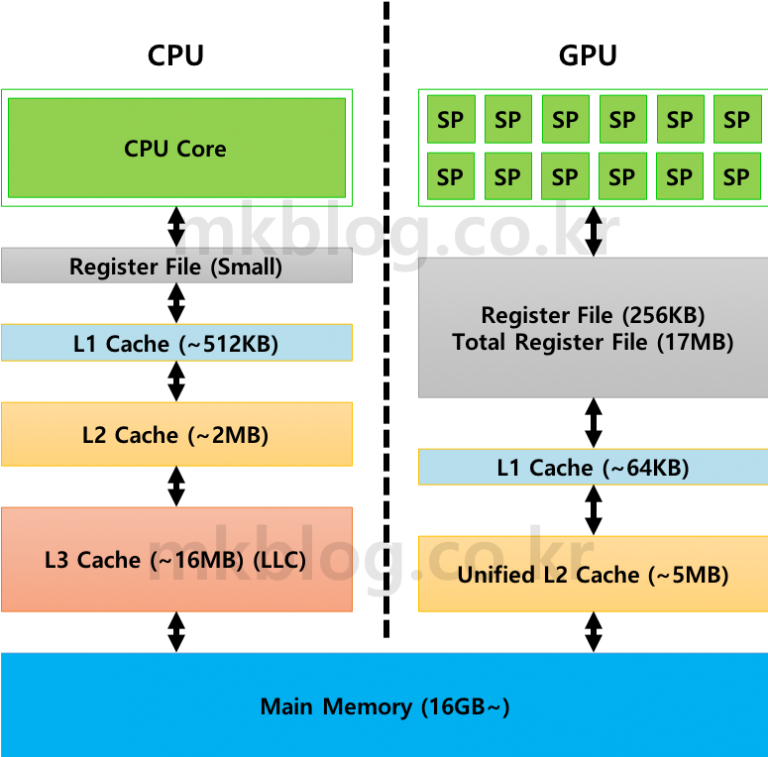
⇒ 두 아키텍처는 deal with memory wall strategy가 다른 것
- 디램은 가져오는데 시간이 오래걸리기에 CPU는 디램에서 gorup of data를 가져와서 캐시를 다 저장해서 접근하는 방식으로 해결
- 대부분 가져온 그 옆에 꺼를 접근할 가능성이 크기 떄문
- gpu의 경우에는 context swithing overhead가 작기 때문에 alu에서 계산하는데 캐시에 없고 기다려야 한다면 next group of thread한테 가서 computation을 하도록 진행 왜냐면 context swithing overthead가 작기 때문!!
Q. gpu에서 context switching 오버헤드가 작은 이유는?
A. cpu에서는 thread의 status(Register값들)은 레지스터들을 메모리에 저장해줘야 함 근데 그렇게 안하고 레지스터를 엄청 많이 저장하게 해놓고 이만큼만 thread 얘네들만 저만큼은 저 trhead애들만~ 뭐 이렇게 두고 이미 레지스터에 저장되어있는 switching context냅다 하는거지… 레지스터를 메모리저장하는 게 아니라 이미 있으니까!!
그리고 아키텍처도 간단한 편이여서~~
데이터 업데이트 되었을 때 업데이트되었다는 거를 전달할 필요가 없어서….
GPU

- a,b,c는 cpu memory에 있다라고 가정했다면 cpu dram, gpu dram다르니까 다시 가져와야 함
- kernel을 만들어야 함. 얘는 function인데 gpu에 돌아가는 함수래
- 각 커널은 아주 적은 수의 계산만 진행
- cpu multithread에서는 싱글 쓰레드는 많은 계산을 하는데 gpu는 아주 많은 thread를 많이 돌리기에 각 thread는 한두개 더하기 정도만 진행
- thread가 하나만 더하면 for문 필요없고 여러개 계산할 거면 for문 필요한데 인덱스는 지정해줘야 함
GPU: Streangths revealed
- Emphasis on parallelism means we have lots of cores
- allow to run many threads simultaneously with no context switches
- cpu는 core가 16개정도밖에 없는데 gpu는 수백개가 있으니까 많은 스레드가 동시에 많이 돌아가도록 함 왜냐면 context swithing이 쉽기 때문
- GPU context switching overhead is cheapper
1) CPU progrmaming - First Try


2) GPU Prograaming- First Try(CUDA)
CUDA Programs
- CUDA Programming interfaces(Library)
- extended syntax
- based on c + extended syntax
- c인데 cuda interface와 extened syntax(to control something)
- Add function needs to run on GPU
-
함수 앞에 **global**이라고 쓰면 CUDA에게 얘는 gpu에 돌아야 한다고 알려주는 거임

-
-
Memory allocation on GPU

- cudaMallocManaged라는 함수를 써서 alloc을 해줘야 함
- free도 cudaFree로!
- unified memory: 저 함수로 하게 된다면 access from cpu as well as gpu - cpu, gpu 둘 다 접근할 수 있게 할당 - 프로그래머가 카피해주진 않지만 알아서 하기에 오버헤드가 더 큼 - cpu dram, gpu dram은 다른 스토리지 이니까 따로 해야하는데 귀찮으니까 그냥 한번에 하려고 한 거임 싱크도 알아서 해줘서 기다려서 카피해줌
-
Launch add() kernel on GPU

- 1은 블럭 수를 의미하고 뒤의 1은 thread 수를 의미함: block은 group이고 thread들이 존재하여 다같이 돌리고 그럼. 각 그룹은 1개의 thread를 가지고 있는데 그 그룹 1개만 쓴다는 소리임
- nonblocking function임. 안끝나도 그냥 냅다 지나감(비동기 함수)
-
그래서 기다리는 cudaDevicesSynchronize함수를 넣어주면 결과를 볼 수 있을 것

컴파일 방법

- Performance를 보고 싶으면 profile 어쩌고 밑에 명령어를 쳐야함
3) From 1 Thread to 256 Threads
아까는 1개의 쓰레드에서 돌렸는데 이제는 256개의 스레드에서 돌리게 해보자!!

- 저 숫자만 바꾸고 돌리면 256개의 쓰레드가 같은 계산을 하게 되기 때문에 저 파라미터만 바꾼다고 되는 게 아님!!
→ 256개의 쓰레드가 다른 일을 하도록 해보자!


200배 가량 성능이 향상됨!!
4) From 1 Block to multiple Blocks
cuda programming에 map thread to data가 중요한 부분


- numBlocks가 적어도 n보다는 많아야 하기 때문에 안나눠떨어질 것을 대비해서 round up하는 n+ blockSize-1/blockSize를 넣은 것!
- ex) n= 1000 , blockSize = 256 → 그냥 나누면 3.90니까 3이 되는데 round up을 하면 4가 됨
- round up으로 계산했기 때문에 block의 수는 n보다 크게 될 거기 때문에 루프 필요없음
- 밑에는 entire thread수가 작을 때의 코드여서 for문이 있는 거임

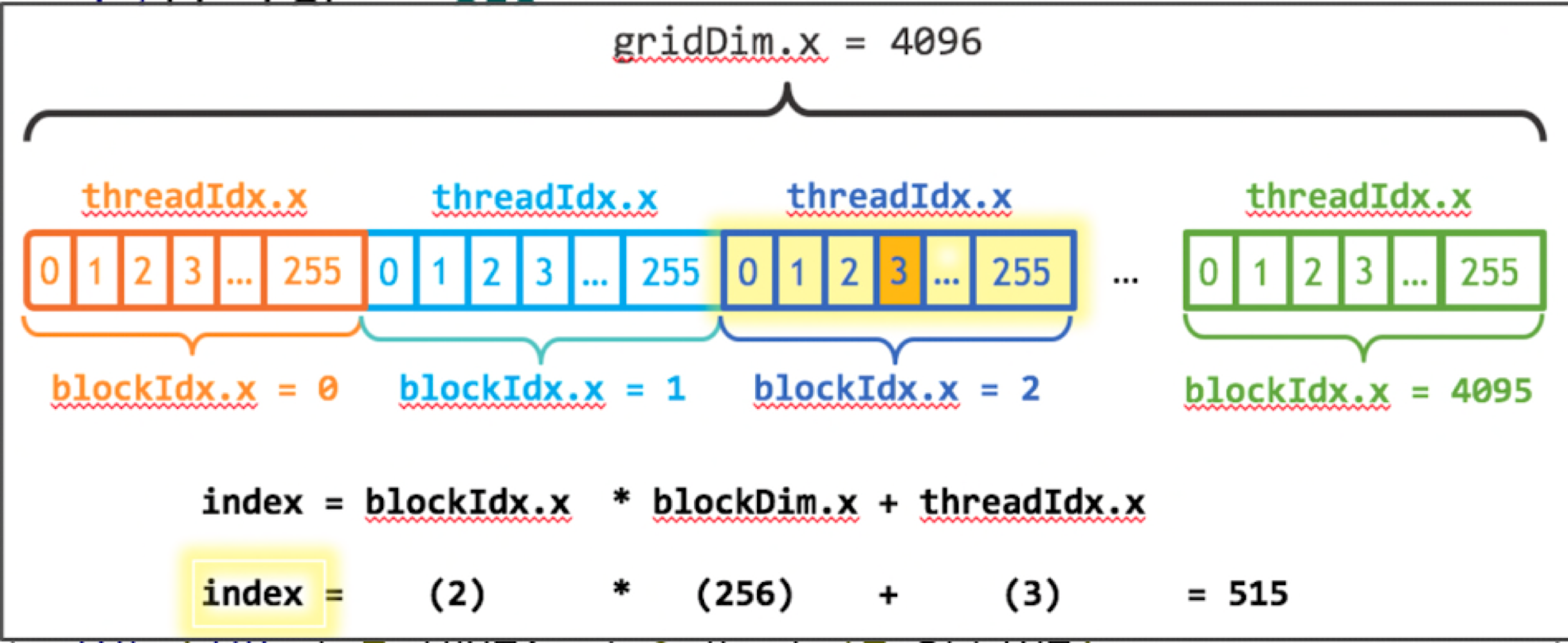
- blockdim = 256, gridDim = numBlocks
- 첫번째 255개의 thread의 block indx는 0일거임 반복~
- 그 thread block안에 local thread id가 있을 거임
- array additon이니까 array를 thread에 맵핑해야함
- 대부분의 배열을 2차원일거니까 Mapping thread to data가 쉬울거라고 생각해서 이렇게 디자인된 거래!
- block idx: 몇번째 블럭인지를 나타내는 거
- blockDim: size of thread, 즉 256을 의미함. 해당 블럭에 있는 쓰레드의 수를 의미
- 저 주황색의 thread일 때의 index 값은 515 == 전체 array mapping하나씩 했을 때의 순서가 되는 거임!!!
2차원이 된다면 좀 더 어려워지겠지만 간단한 편이긴 함

→ 여러 블럭을 쓰게 된다면 왕밤빵 빨라짐!!
#include <stdio.h>
__global__ void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i< n; i+=stride) // 이거 필요없음
y[i] = x[i] + y[i];
}
int main()
{
float *x,*y;
int N = 10<<20;
cudaMallocManaged((void**)&x, N*sizeof(float));
cudaMallocManaged((void**)&y, N*sizeof(float));
for(int i=0;i<N;i++){
x[i] = i; //x를 i로 초기화
}
int blockSize = 256;
int numBlocks = (N+blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N,x,y);
cudaDeviceSynchronize();
for(int i=0;i<N;i++){
printf("%.2f, ",y[i]);
}
cudaFree(x);
cudaFree(y);
return 0;
}