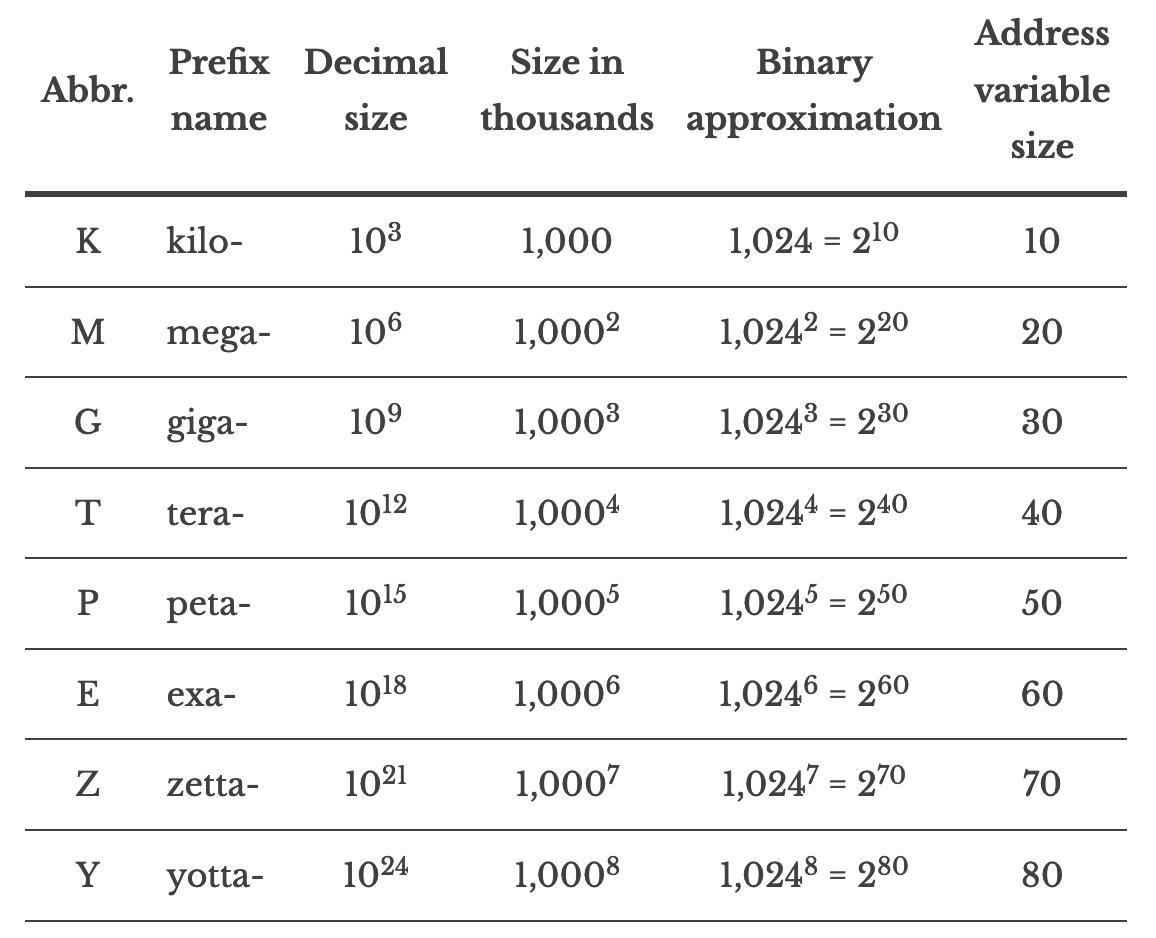
단위 계산을 위한 값들
c에서의 배열 관리방법
constant memory는 global memory with special cache
Latency & Throughput
latency
- 응답하는데 기다리는 거를 말함. low면 빨리 답한다는 거고 high면 응답하는데 기다려햔다는 것
- latnecy는 hardware의 speed때문에 느려질 수 있음!
throughput
- 높다면 performance 좋다는 소리
- CPU
-
low latency low throughput

- 응답도 빠르고 throughput은 약간 작은 편
- 클럭이 빠른 편
-
- GPU
-
high latency high throughput

- 일반적으로 longer latency라면 주로 low throughput이지만 pararell은 다를 수 있음
- 응답시간이 느리면 처리양도 serial에서는 작지만 병렬은 빠를 수 있음!
← latency를 희생하더라도 동시에 하기 위해서 조금 응답이 느릴 뿐
- 클럭이 GPU보다 느리고 다른 부분도 CPU보다 긴 편
-
Q. 왜 GPU는 high latency일까?
A. 많은 sm이 있기에 병렬적으로 동시에 돌리기에 high throughput를 얻기 위함
- sm에서 cohereiance를 구현하지 않은 이유는 throughput때문
- cache coherience api는 주로 아주 비싸기 때문(memory address가 Update되면 broadcast)
Compute & I/O throughput

- throughput
- 초마다 sm performing float point 계산하는 양을 의미
- 테라 flops니까 매초 11.3* 10^12 번 계산한다는 것
- memory bandwidth
- 1초에 dram에서 sram으로 가져올 수 있는 데이터양이 484기가라는 소리
- float가 4바이트니까 484 / 4 = 121 Gloats =매초 float 121 * 10^9 개를 가져올 수 있다는 소리
- → 위의 두가지 값을 보면 100배정도 차이가 남
-
floating data point를 가져오는 시간보다 계산하는 시간이 100배빠르다는 거임
데이터 가져오는데 100만큼 기다렸다가 계산하는데 1만큼밖에 안쓰인다는 소리임!!
⇒ GPU는 아주 IO limited이다!!! IO는 throughput bootleneck
→ cuda 코드를 구현할 때에는 quickly fetch data dram to sram이 안되니까 최대한 잘 쓰는게 좋다
그래서 memory wall을 잘 극복할 수 있을지가 다음에 얘기할 부분임
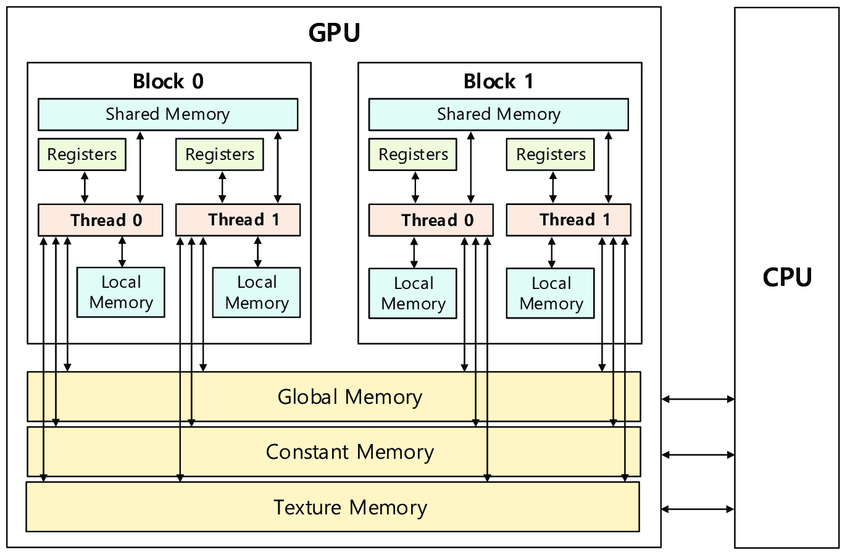
GPU memory breakdown

- gpu는 저런 메모리 heirarhcy를 가짐
- texture memory: 그래픽스 영역에서 사용되는데 커버안할 내용
Memory scope

- local memory, register
- 싱글 쓰레드만 접근 가능
- 쓰레드가 만들어지면 variable map to register
- 쓰레드가 끝나면 사라짐

- shared memory
- thread block에서 접근 가능
- 여러개의 warp이 생성되고 all thread in block 접근 가능
- 모든 thread가 끝나면 shared memory는 사라짐

- global memory
- 모든 커널들도 같이 사용하는 곳
- 다른 커널에서 사용되는 값도 접근 가능
1) Global memory

- 연두 네모는 compuation chip(20개의 sm), 빨강이가 dram
- 연두 네모 안에는 compuation unit안에 shared, register, cache가 있음
- 따라서 dram은 computation unit과 떨어져 있기 때문에 시간이 많이 걸리는 편
- GPU SMs과 분리되어있는 hardware
- 레지스터, cache보다는 많은 편이고 대부분의 메모리는 global memory에 있음
- 1~80기가의 global memory를 가지는데 대부분 GPU는 10~20기가정도 가짐
- global memory는 cpu memory나 ssd보다는 작기에 넘는다면 여러개의 GPU를 써서 데이터를 나눌 수도 있고 chunk에 저장할 수도 있음
- 100기가를 접근해야하면 20기가씩 dram에 넣고 fetch 20기가 5번 반복
Accessing global memory efficeintly
-
Global memory IO는 GPU에서 가장 느린 form of IO
→ global memory를 최대한 적게 접근하고 싶음!
: coalesced memory accesses
-
optimize group the memory access very small transaction
- need to efficiently our program that coalesced memory accesses
- 커널코드가 메모리를 접근할 때 gpu에 좋도록
Memory coalescing
- Warp마다 large group of Memory transactions으로 묶어서 한꺼번에 하는 것을 말함
- warp에는 32 thread가 있는데 최대 32개의 transaction을 동시에 한번에 하는 걸 말함
- minimize number of cachine line to fetch memory access
- cache line은 unit임. fetch data to cache하는 단위로 주로 128바이트이고 align
- 이유: memory access는 group해서 한개 transaction으로 보낸다고 했는데 32개 thread * 4 바이트 = 128 가 되는 거
Mis-aligned accesses

- 하나의 warp은 32개의 thread가 있는데 각 쓰레드는 각 저걸 접근함
- 128~255까지는 128바이트이니까 single cache line에 저장되지만 그 후에는 another cache line
= 2 cache line 접근이 됨

- 모든 warp이 저 캐시라인에 다들어가게 한다면
= single cache line featching 가능
- colaesec access: 이전 그림을 아래처럼 하자는 거임!!
2) Shared memory
- 각 SM에 들어있는 fast memory
- shared memory는 L1 cache와 같은 하드웨어로 memory space 조절 가능
- shared memory는 많이 L1을 적게
- L1을 많이 shared memory를 적기
- latency: 5 ns보다 빠름
- global보다는 빠르지만 register보다는 느린 편
- 최대 96kb (per sm)의 사이즈
- thread block에서 접근 가능
- 흥미로운 메모리임
- L1,L2 cache는 프로그래머가 캐시의 존재를 알 필요 x
- shared memory는 프로그래머가 코드로 which data stored in shared memory를 정해주야 함
- cache, shared memory는 sram으로 구현되있는 편
-
dram은 1,2개의 트렌지스터로 구현되어있고 sram은 싱글 셀을 6개의 트렌지스터를 저장
→ 즉 더 비싸다는 소리
-
Shared memory syntax
- statically, dynamically allocation 모두 가능
- static allocation
- __shared__ float data[1024];
- 커널에서 선언하고 host code에서는 필요 없음
- shared memory에서 필요한 사이즈를 코드에 명시하는 것
- shared라고 쓰면 이거 shared memory에 저장하고 싶다는 소리
- dynamic allocation
- Host(부르는 곳)
- kernel«<grid_dim, block_dim, numBytesSHMem»>(args);
- kernerl을 부르면서 같이 적어줘야 함
- size of shared memory를 보내줌 예를들어 4096(4* 1024)
- Device(in kernel)
- extern __shared__ float s[];
- Host(부르는 곳)
- cuda는 다른 목적으로 사용되기 위함…
CUDA kernel w/ shared memory
- compute histogram of color usage를 해보자!
- input: n길이의 배열
- output: 256개의 길이를 가지는 int 배열
- 각 인덱스에 값이 얼마나 쓰였는지를 해당 배열에 저장할 거임
Naive

- build output in global memory, N global stores
- n개의 배열 요소마다 buckets라는 global memory에 1씩 더하니까 n번 store해줌
Using Shared memory

- build output in shared memory, copy to global memory at end, 256 global stores
- shared memory와 two level aggreation을 동시에 사용
- static하게 shared memory인 output 배열을 선언
- hist는 같은 블럭 내에서 공유
- static하게 shared memory인 output 배열을 선언
- global histogram을 건들기 전에 local thread block에 있는 값을 업데이트
- __syncthreads()
- 모든 trhead block이 local hist에 저장을 끝날 때 까지 기다림: barrier
- 그 다음에 로컬 히스토그램값으로 global memory인 buckets을 업데이트
- 우리는 256개길이만 볼거기에 256개까지만 글로벌 업데이트
근데 여기에 아주 큰 가정이 있음!!!
- 가정: block안에 thread 수가 256개보다 커야 함. 아니라면 글로벌 값을 업데이트 못하기 떄문
- 만약에 한 블럭에 128개의 쓰레드가 있으면 배열 256길이 중에 128개만 업데이트가 됨!!!
→ 그래서 그런 케이스를 체크해서 block dimension.x가 256보다 작다면 루프를 돌려야 함
Q. 더빨리 하고 싶으면?

- current thread가 접근하는 global(dram)값인 color도 shared memory에 저장하자!!
→ 향상되긴 하지만 엄청되지는 않음 왜냐면 한번 fetch해서 한번쓰니까!
- but better scheduling을 주지만 한번 가져와서 한번 쓰니까 엄청 좋아지지는 않음
- 이전
- update value multiple time 1024개의 thread라면 각 요소는 평균적으로 4번 update
- 지금
- fetch 한번 use 한번
⇒ 데이터를 dram에서 가져와서 shared memory를 저장하고 한번만 써도 도움이 됨
한번만 써도 shared memory아니면 L1 cache에 있겠지만 그래도 여기서 syncthreads를 하는데 왑 스케줄링도 하니까 좋아지더라~ L1 cache에 될수도 있지만 shared memory에 바로 하는 게 낫다!
A common patten in kernels
- copy dram(global memory) to shared memory
- __syncthread(): wait for the memory fetching finish
- perform computation using shared memory
- incrementally shared memory에 저장해야하면 _syncthread 해줘야 함
- save in shared memory
- copy shared memory → dram(global memory)
Bank conflict for shared Memroy
커버 안할꺼임
- shared memory는 32개의 bank가 사실상 있음
- bank conflict
- shared memory가 bank들로 구성되어있고 bank마다 다른 와이어가 있어서 병렬적으로 접근 가능.
- 같은 bank라면 다른 address라도 serialzie되니까 시간이 오래걸리니 같은 뱅크를 접근하는 거를 최소화하게 해보자!
3) Register
- fastest memory
- shared memory보다 10배 빠름
- 각 sm은 10000개의 레지스터를 가지고 있음
- thread마다 32, 64개의 32 bit register를 사용할 수 있음
- good idea design code each thread는 20,40,60개 정도를 쓰는 게 좋음
- 많이 쓰면 병렬적으로 처리 못하기 때문, register가 bottleleck이 되기 떄문
- local variable(stack varaible) in kernel 은 레지스터에 주로 저장
- ex) Int i, float c;
- allocate static allocated array in kernel이라면 register에 저장될 수 있지만 사이즈가 커지면 local memory에 저장
4) Local Memory
- 레지스터에 저장하지 못하는 값을 local memory에 저장
- variable은 주로 레지스터에 배열은 주로 local memeory에 저장하는 편
- global memory(dram)의 하드웨어 위치는 동일하지만 스콥이 thread에만 접근 가능
- register보다 느린 편
CUDA variable type qualifer

- 접근 가능한 영역
- thread: register, local
- block: shared
- grid: global, constant
CUDA variable type performance

- 속도
- 빠름: register, shared(둘 다 SM 안에 있음), constant
- 느림: local, global(둘다 gpu 밖에 dram에 있음)
CUDA variable type scale

- instance는 얼마나 많이 생기느냐인거고 visibility는 해당 변수를 몇개의 쓰레드가 볼 수 있는 가를 말함
오늘은 remain of gpu memory hiearachy
after explian more about effectiviely access memory
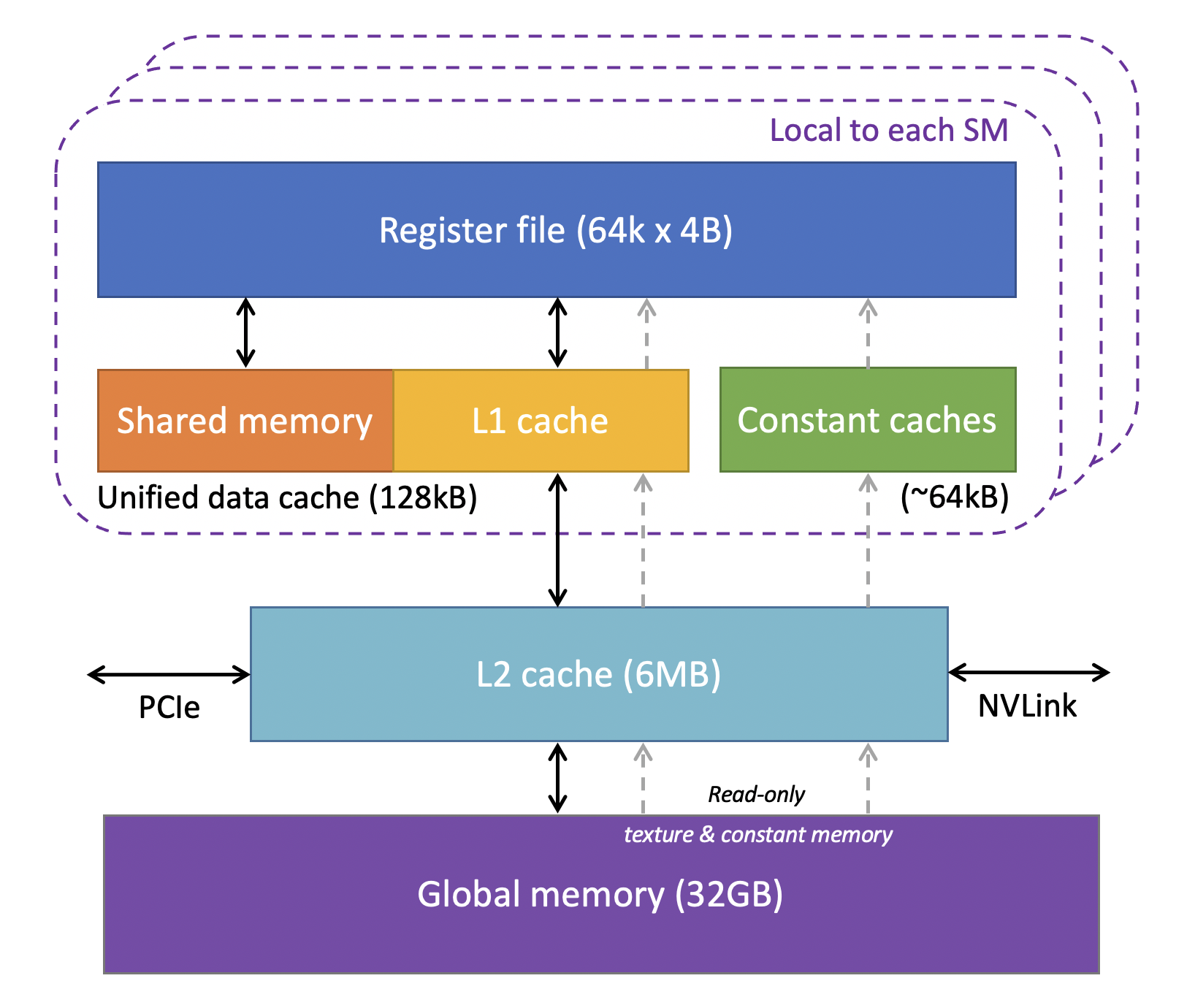
L1/L2/L3 cache
대부분 l1,l2 cache를 가질 수 있지만 l3까지 가질 수 있음
L1 cache
- local and global memory(dram)를 캐시
- shared memory(SM안에 존재)와 같은 하드웨어를 사용
- 각 SM 안에 L1 cache를 가짐
- 16,32,48 KB
- configure share memory and L1 cache 여서 맘대로 양 변경 가능
- cache coherience가 gpu에 없다고 했는데 이건 비싼 거여서 없는 거라구 했음… prorpagate all other sm이기에 expensive
- 다른 thread block끼리는 atomic을 써야 함
L2 cache
- 모든 SM에서 공유
- caches all global and local memory access
- size는 최대 1MB
Constant memory(cache 아니고 memory!!!)
- global memory인데 special hardware cache
- program에서 compile되지 않은 constant에 사용
- constant는 host로부터 설정되어야 함
- user에게 최대 64KB, compiler에게 64KB
- to store constant information + constraint all the thread in same warp에는 무조건 같은 어드레스를 접근해야 함
-
이름은 constant이긴 한데 constant를 저장하기도 하지만 하나의 warp에 있는 쓰레드들이 무조건 같은 어드레스를 접근하도록 만들어서 그 경우에 빨리 접근하도록 옵티마이즈를 했기에 그래야 그렇게 한 거
ex) read only이지만 color 예시에서 constant memory 못씀 왜냐면 color[i]는 왜냐면 같은 주소를 안쓰니까!!! 대신 blockIndex는 가능하대…
-
- ex) kernel argument: size of block, thread configuration을 말함
- 이게 constant memory에 저장된대!!!
- Constant memory syntax
- global scope에 __constant__를 이용해서 Outside of kernel, at top level of program에서 선언
**__constant__** int foo[1024];
- 커널 안에서 cudaMemcpyToSymbol 사용하여 가져옴
- **
cudaMemcpyToSymbol**(foo, h_src, sizeof(int) * 1024);- h_src가 가리키는 메모리를 foo에 복사
- **
- global scope에 __constant__를 이용해서 Outside of kernel, at top level of program에서 선언
Constant cache
- SM마다 존재
- 8KB 사이즈
- 사이즈는 지바지니까 그냥 limit라는 것만 알기
- special instruction(LDU, load uniform)
- constant data acess마다 warp에 들어있는 모든 쓰레드는 같은 location을 접근(uniform access)
- constant memory의 일부를 캐싱하는 거라고 생각하면 될 듯
Q. constant cache, constant memory 다른건가요?
A. constant cache는 아키첵처 기준이고 constant memory는 프로그래머쪽…
constant Memory에 저장하면 dram에 저장되면 얘를 위한 하드웨어인 constant cache가 있다는 것!
Example - shared variables
중요한 부분이래
- input[i] - input[i-1]을 result[i]에 저장하는 예시
naive version

- 성능 측면에서의 성능:
- input이 global memory이므로 access가 느리다
- 각 쓰레드는 input이 두번 읽힘
- input[i]자체는 두번 읽힘 한번은 i thread에서 두번째는 i+1 thread에서 input[i-1]를 읽을 때!
Q. 캐시라인으로 읽으니까 괜찮지 않니???
A. 여러 warp이 동시에 돌기에 redict될 수도… 안될 수도 있다는 거~~ L1 cache는 프로그래머가 관리하는 게아니니까 확신할 수 없음
→ share memory를 쓰자!

- share memory를 bock size(블럭에 들어있는 쓰레드 수)만큼 할당
- 해당 thread에서의 input을 한개 읽어서 s_data를 할당
- 다른 쓰레드들이 load할 때까지 기다림

- 그다음 tx가 0보다 큰지 확인
- 이유: 딱 0이면 tx-1이 -1이니까 안됨!!
- shared memory에 있는 값으로 차를 계산해서 Result에 저장
- 조건 한개 더 추가
- input 배열을 s_data로 블럭마다 쪼개서 쓰는 걸로 바꿨음
- 만약 s_data의 맨 처음인데 그게 input[0]이라면 맨앞이니까 비교할 게 없으니까 더이상 처리 x
- 근데 s_data의 맨 처음인데 input[0]이 아니라면 그 전 s_data의 마지막 요소를 가져와서 차를 구해야 함 → input[i-1]를 로드해서 차를 구해야 함
Optimization analysis

- 기존
- load: input[i]를 두번씩 읽히니까 2N개 읽어야 함
- store은 동일
- throughput 느림
- 개선
- load: s_data에 불러놓으니까 한번씩 읽게 되어 N번 읽힘 + s_data[0]일 때 그 전꺼 불러오는게 블럭마다 한번씩 일어나니까 N/block_size(블록 안에 들어있는 쓰레드 개수)
- 가정: 쓰레드 갯수가 배열에 딱맞거나 살짝 크게 되어야 함
- store은 동일
- throughput: 1.6배 많이 처리함
- load: s_data에 불러놓으니까 한번씩 읽게 되어 N번 읽힘 + s_data[0]일 때 그 전꺼 불러오는게 블럭마다 한번씩 일어나니까 N/block_size(블록 안에 들어있는 쓰레드 개수)
Q. array size가 작다면 캐시에 올라간다면 improve와 차이가 없을 거 같은데 improve는 shared memory를 만들어서 캐싱을 보장해주는 거니까 차이 없는 거 아닌가요??
A. L1 캐시 안에 어레이가 전부있지 않더라도 실행되고 있는 블록에서 access되는 게 다 캐시되어있으면(혹은 배열이 작다면 다 캐시될 수 있음) 개선될 필요가 없는 게 맞는거같대 별 차이 없을 수도 있을 수 있대
Matrix multiplicaiton example
중요한 함수래 대부분의 mlp나 대부분 딥러닝 같은 경우에는 multiplication matrix를 사용, convolution도 마찬가지~

- 어떻게 thread block에 map해야할까???
- 쓰레드 블럭이 각 하나를 관리하자
- 왜냐면 다들 Output 기준으로 나누기 때문
- thread block on each grid
Naive implementation
일단 원래 정의한대로 계산해보자!!

- 저 네모 하나가 블럭이기에 안에 쓰레드가 한개만 들어있는 게아니라 똑똑똑 엄청 들어있음 유의할 것!!
- row, col,k은 레지스터에 저장
- a,b, ab는 글로벌 메모리에 저장
✅ How will this perform? 시험에 나온대!!
- peak fp performance
- peak fp performance가 805라는 거 hardware limit임
- memory bandwidth
- 즉 각 초마다 dram에서 sram으로 얼마나 메모리를 가져오는지를 의미함
→ 이걸로 이전 커널로 나머지 애들을 구할 거임

- dot product 할 때 몇번 load하니?
- 2: a,b 두번씩 하니까!!
- 저건 for문 안에서 얼마나 하는지를 말하는 거임
- for문에서 몇번 floating point operation을 하는가?
- 2번: 곱해서 더하니까
- GMAC
- GMAC: 각 floating operation에서 얼마나 바이트를 fetch를 해야하나?
- 8바이트를 가져온다고 했고 2번 해야하니까 나누면 약 한번 계산할 때 4바이트를 가져와야 함
이걸로 fully utilize throughput을 구할 수 있음
- peak fp performacne를 얻기 위한 lower bound bandwidth
- 이 커널에서는 한번 fp point를 sm안에서 하기 위해서 dram→ sram에서 4바이트를 가져와야 함
- 이 gpu는 초당 805 gflops를 최대 처리할 수 있는데 이걸 다채우려면 얼마나 데이터를 가져올 수 있어야 하냐?
- 4 * 805 = 3.2 TB/s
- 이 커널에서는 한번 계산할 때 4바이트를 가져와야 하는데 하드웨어는 일초에 805 gflops를 한다니까 이걸 achieve를 하면 4*805 = 3.2 tb가 되는거
- 아까 주어진 actual memory bandwidth
- 112 GB
→ memory bandwidith가 3.2tb를 최대 가져올 수 있는데 실제로 가져오는 건 3%인 112기가밖에 안됨
- 우리 구현의 fp performance는?
- 112*1/4 = 28 gflops
→ 805gfops인데 실질적으로 사용되는건 28gflop니까 3%정도밖에 안된다는 거임
IDEA: global data를 재사용하기 위해 shared memory를 쓰자!!

- 사실 하나 계산하고 옆에있는 애를 계산하려면 같은 a row를 접근함!! 이걸 이용해서 해보자!!!
- thread별로 하나씩 계산하는데 한줄마다 같은 a값을 이용하니까 그걸 share하자!!
→ reduce require of memory bandwidth!
Tiled multiply

- loop를 phase로 한번 더 나누자!!!
- 파랑이 긴 네모를 검정 tile로 나누자
- tile에 있는 로드를 한 후에 shared_memory에 불러와서 partial result를 result에 저장(사실 shared memory 필요 없음)
- store the temporary result 한 후에 모든 thread가 끝나면 다음 tile을 진행하고 … 반복
Use of Barriers in mat_mul

- two barrier가 필요
- phase는 정사각형 네모 하나를 말함
- 각 phase마다 two barrier(sync thread)가 필요
- 모든 데이터가 share memory에 올린 후에 계산 시작
- 두번째는 next phase으로 가서 새로 계산하기 전에 이전에 있던 애들이 모두 계산을 끝내야 함
- guard
- global에서 shared로 가져와야하는데 fetch하기 전에 계산하는 것을 막음
- 두번째는 before using it overwrite하지 않음
→ 처음꺼는 shared memory를 다 로딩된후에 읽도록 하게!! 두번째는 읽었으면 써야하는데 어떤 왑은 써서 계산했는데 다른 왑은 안끝났는데 패치하면 안되니까 !!
Q. 왜 기다려야 하죠?
A. 저 파랑이 네모가 사실 이동하는게 아니라 같은 어드레스에 그냥 덮어쓰여지면 됨
로드할 때에도 w1은 여기를 로드 w2는 여기를 로드하는데 w1는 w2가 로드한 부분도 읽어야하니까
Q. 로드를 왑마다 나눠서 하면 시간이 느리게 되는 거 아닌가??
A. 무조건 로드를 해야하고 여러번 로드를 하는 건 아니니까 비효율적인 건 아님. 리드만 하tb1이 로드하고 tb2가 계산하고 이럼 되지~
Q. a,b를 그냥 네모네모로 하는 게아니라 row줄별로 하면 되지 않나???
A. 그러면 row만 share되니까 안좋을 거같은데~~
공유를 하기 때문에 생기는 barrier이기 떄문에 그닥 문제가 되지 않음!!
Better



- s_a, s_b 공식 나오는 이유
- row: 그리드 관점에서의 output의 y좌표 - 4
- col: 그리드 관점에서의 output의 x좌표 - 3
- width: a,b의 가로 세로 길이 - 9
- TILE_WIDTH: tile의 width - 3
- tx: thread id - 1
- ty: thread id - 0
- p: phase - 0
- s_a
- 일단 해당 row까지 펼쳐서 가려면 row * width(우리 ab좌표 구하는 거 참고해서!!) 그다음에 p*tile_width+ tx는 얼마나 옆으로 이동할건가 인데 phase마다 tile_width만큼 이동해야하니까 곱한거고 tx는 thread마다 계산하는 부분
- s_b
- 몇번째 줄인지를 구한 후에 width를 곱해서 col을 더하는 거는 알겠지??(ab구하는 거처럼)
- 몇번째줄인지는 타일마다 달라질거고 타일에서의 쓰레드마다 계산하는 거가 들어가야하니까 ty추가!!

- tile width == thread block size : 16 * 16 = 256개의 쓰레드 필요
- 쓰레드 블럭 수
- 1024 * 1024 matrix라면 (모든 a,b,c가 같은 사이즈라고 가정했을 때 계산임) tile width가 16이니까 1024/16 = 64 이므로 64 * 64개의 thread block 필요
- 여기에 sm이 3개의 블럭을 가질 수 있다면 sm은 16163 = 768개의 쓰레드를 사용할 것 → hardware max가 768개라면 100%사용하는 거고 1024%사용한다면 75%를 쓰는 것
- 각 쓰레드는 2개의 로드(a,b)가 필요하고 블럭에 256개의 쓰레드가 있기에 512개의 로드가 필요함
- 거기에 4바이트(32비트)
- 256개의 쓰레드가 각각 곱하고 더하는 걸 k번(16) 하니까 = 256 * 2* 16 = 8192 ops
→ 512개의 floating data를 가져와서 8192개의 연산을 하는 거지!!
== 약 데이터 하나 가져올 때마다 20번(16번) 계산한다는 소리
- 아까는 한번 가져왔을 때 한번 계산했었음 GMAC가 4b니까
→ memory bandwidth는 더이상 문제가 되지 않음!!

- 기존
- nn matrix이니까 이걸 다하면 a,b 다 한번씩 로드하면 되니까 적어도 2 n^2임
- 근데 Row는 share되고 col만 바뀌었었는데 계속 로드했으니까 사실상 a는 n번씩 각 요소가 불리는 거!!
→ 2* n^3
- 개선된 버전
- 일단 a,b를 로드하니까 w*n^2
- 아까는 타일이 사이즈가 1*1인거와 같으니까 n번을 로드해야하는 건데 타일만큼 뭉탱이로 shared memory에 올라오니까 n/tile_width만큼 올라오게 되니까 그만큼만 로드하는 거!!!

- throughput도 타일 사이즈가 커지니까 좋아짐
- 타일 사이즈가 커지면 좋아지는데Tile size가 너무 크면 share memory의 사이즈가 크다니까 multiple block in single sm이 되기에 cannot switch를 못할 수 있대 → 발란스 필요
다음주에 하는 거는 시험범위 아니래
local memory: logical하게 쓰레드만 접근하지만 실질적으로는 dram에 있다…
중간고사 부분은 나중에 공지해주겠다고 함